RCTs: The Cornerstone of Evidence – Why AI Needs Controlled Chaos
Design of Experiments
A practical introduction to randomized controlled trials, randomization, allocation, crossover designs, and why design remains central to causal evidence in AI and clinical research.
In an RCT, the treatment groups should differ mainly because of chance, not because one group was sicker, older, more adherent, or more likely to receive a clinician’s preferred intervention.
That design feature makes RCTs the cleanest setting for estimating causal effects.
This matters in both biostatistics and AI/ML.
In biostatistics, RCTs remain the gold standard for efficacy questions. In AI/ML, they provide clean intervention data that can anchor baseline causal models, validate treatment-response hypotheses, and contrast sharply with messier real-world evidence.
This post introduces:
why randomization matters,
how parallel-group and crossover trials differ,
what allocation ratios do,
and how simulation can show the difference between randomized and non-randomized comparisons.
RCTs matter because good causal evidence does not begin with complicated modeling, but with a design that makes the treatment comparison fair from the start.
1. RCTs Begin with a Simple Problem: Treatment Groups Are Usually Not Comparable
In routine practice, treatment is rarely assigned randomly.
Patients receive one treatment rather than another because of:
disease severity,
clinician judgment,
access,
preference,
contraindications,
timing,
or site-level practice patterns.
That means treatment groups often differ before the treatment effect is ever observed.
If we compare them naively, we risk attributing those baseline differences to the treatment itself.
This is the core problem randomization is designed to solve.
2. Randomization Minimizes Bias by Breaking Systematic Assignment
The defining feature of an RCT is that treatment assignment is randomized.
That means, at the point of assignment, no patient characteristic should systematically determine who receives which intervention.
In expectation, randomization balances both:
measured variables,
and unmeasured variables.
This is what makes RCTs so powerful for causal inference.
It does not guarantee that groups are exactly identical in every realized sample. Chance imbalance can still occur.
But it removes systematic assignment bias, which is the more dangerous problem.
That is why randomization is often described as the cleanest design solution to confounding.
3. Randomization Does Not Eliminate Noise — It Eliminates Predictable Bias
A useful way to understand RCTs is this:
randomization does not make the data noiseless,
it makes the treatment comparison unbiased in expectation.
In other words:
outcomes can still vary,
small trials can still be imbalanced by chance,
and estimates can still be imprecise,
but the treatment difference is not systematically driven by the same kinds of assignment processes that distort observational studies.
That is a major distinction.
RCTs do not remove uncertainty. They remove one of the most damaging sources of structured bias.
4. A Parallel-Group Trial Is the Standard RCT Design
The most common RCT design is the parallel-group trial.
In a parallel-group RCT:
one group receives treatment A,
another group receives treatment B or control,
and each participant remains in that assigned arm for follow-up.
This design is common because it is:
conceptually simple,
broadly applicable,
and relatively easy to analyze.
It works especially well when:
the intervention has a lasting effect,
carryover would be problematic,
or the disease process is not stable enough for within-person crossover comparison.
For many readers, this is the default mental model of an RCT.
5. Crossover Trials Ask a Different Kind of Question
A crossover trial assigns participants to receive multiple treatments in sequence.
For example:
one group may receive A then B,
another may receive B then A.
This allows each participant to serve as their own control.
That can be powerful because it reduces between-person variability.
But crossover designs only work well under specific conditions, such as:
a stable condition,
reversible treatment effects,
and adequate washout periods.
If carryover effects are likely, crossover designs can become misleading.
So crossover trials are not a superior version of RCTs in general. They are a specialized design for the right setting.
6. Allocation Ratios Affect Efficiency and Practicality
Another important design choice is the allocation ratio.
The most familiar ratio is:
1:1 treatment to control
This is often statistically efficient when group costs are similar.
But other ratios may be used, such as:
2:1
3:1
or more complex multi-arm allocations
Why would this happen?
Possible reasons include:
ethical preference for giving more participants access to an experimental treatment,
logistical constraints,
safety data collection goals,
or unequal treatment costs.
The key tradeoff is that unequal allocation may reduce statistical efficiency for a fixed total sample size, though it may improve feasibility or acceptability.
7. A Simple Allocation Example Makes the Arithmetic Concrete
Let us create a simple allocation example for a two-arm trial.
Even though the true effect remains +3, the observational estimate may be much smaller or even misleading because sicker patients were more likely to receive treatment.
This is the main contrast the blog title is pointing toward:
controlled chaos beats uncontrolled selection.
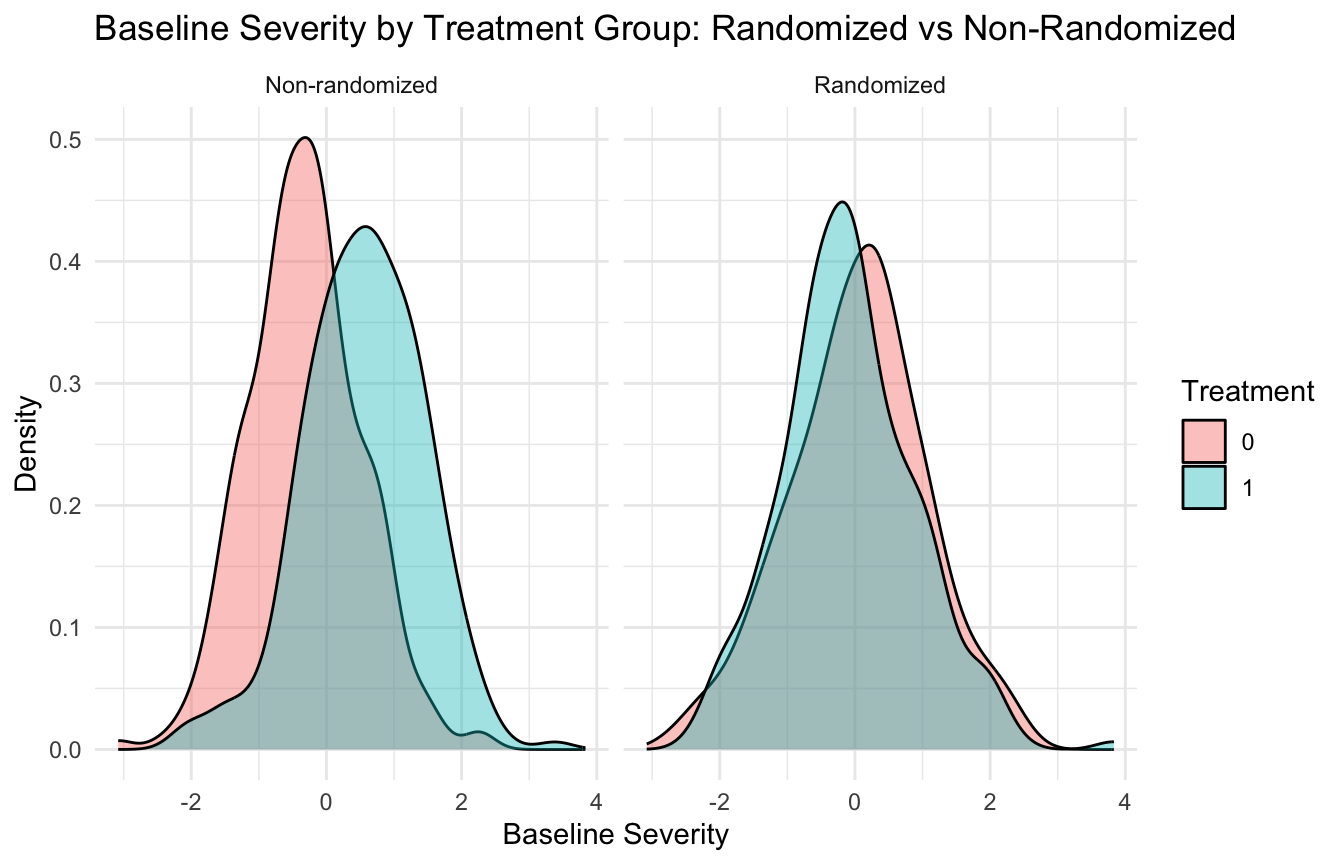
13. Visualization Helps Make the Contrast Immediate
A simple plot can show the difference in baseline severity across designs.
This kind of figure often teaches more quickly than paragraphs of description.
14. RCTs Are the Gold Standard for Causal Inference, but Not for Every Question (Sibbald and Roland 1998)
RCTs are powerful because they solve a major causal problem at the design stage.
But that does not mean they are automatically ideal for every question.
RCTs can still be limited by:
cost,
narrow eligibility criteria,
short follow-up,
ethical constraints,
nonadherence,
and limited external validity.
So the real lesson is not:
“RCTs are always enough.”
It is:
“RCTs provide the cleanest causal benchmark.”
That is why they remain the reference design even when later work must move into pragmatic or real-world settings.
15. RCTs Matter in AI/ML Because They Provide Clean Intervention Data
In AI/ML, RCTs matter because they produce data where treatment assignment is not tangled up with the same observational biases that plague real-world datasets.
This makes RCT data valuable for:
benchmarking treatment-response models,
validating causal assumptions,
estimating cleaner baseline effects,
and contrasting trial evidence with real-world deployment data.
For example, a model predicting drug efficacy may benefit from trial-derived labels precisely because the assignment mechanism is known and controlled.
That does not mean trial data alone are always enough for deployment. But they provide a strong anchor.
16. Hybrid Evidence Strategies Often Compare RCTs with RWE
A very important modern theme is that RCTs and real-world evidence are not enemies.
They answer different parts of the evidence problem.
RCTs are strong for:
internal validity,
efficacy,
and causal clarity.
RWE is often stronger for:
broader populations,
routine-care settings,
implementation variation,
and long-term use patterns.
This is why hybrid evidence approaches matter so much in AI and biostatistics. RCTs often define the causal core. RWE tests transportability, heterogeneity, and practical deployment.
Intent-to-treat analysis compares participants according to their randomized assignment, regardless of later adherence.
This preserves the causal benefit of randomization.
That is an important lesson because post-randomization behavior can reintroduce bias if handled carelessly.
Even when the main blog post does not go deep into adherence or attrition, it helps to mention that trial design and trial analysis are linked.
The causal strength of an RCT depends partly on preserving the logic of the assignment process in the analysis.
18. Small Trials Can Still Show Chance Imbalance
A useful caution is that randomization does not guarantee perfect balance in a single realized sample, especially in smaller trials.
This is why analysts still:
inspect baseline summaries,
consider stratification or blocking,
and interpret small-sample imbalances carefully.
The point is not that imbalance means the RCT failed. It means randomization eliminates systematic bias, not all observed difference.
That distinction matters for both teaching and interpretation.
19. A Practical Checklist for Applied Work
Before designing or interpreting an RCT, ask:
What exactly is being randomized?
Is the design parallel-group or crossover?
Is the allocation ratio appropriate?
Is time zero clearly defined?
Are important baseline covariates likely to be balanced by design, or should stratified randomization be used?
Is the estimand clear?
Will the analysis preserve the benefits of randomization?
These questions usually matter more than superficial trial labels.
NoteWhere This Shows Up in AI/ML
The stepped-wedge RCT is increasingly the design of choice for evaluating clinical AI deployment — a decision support tool rolls out across units sequentially, with each unit serving as its own control before exposure. This is how MAVEN-integrated triage decision support tools should be evaluated, not with single-site pre-post comparisons that confound the AI effect with temporal trends. Without randomization of rollout order, any observed improvement is as likely attributable to staff attention, concurrent training, or seasonal case mix as to the tool itself. Skipping this design for convenience produces AI “effectiveness” claims that cannot survive scrutiny when the system is proposed for wider fielding.
Closing: RCTs Earn Their Status by Making the Comparison Fair
Randomized controlled trials remain the cornerstone of evidence because they address a central causal problem directly:
they make treatment assignment fair in expectation.
That does not make them simple, cheap, or universally sufficient. But it does make them uniquely powerful.
Parallel-group and crossover designs answer different questions. Allocation ratios shape efficiency and feasibility. Simulation makes the main lesson visible:
when treatment is randomized, the comparison is cleaner
when it is not, the estimate can be distorted before the model even begins
RCTs matter because the most convincing evidence often comes not from more complicated analysis, but from a design that prevents bias from entering the treatment comparison in the first place.
This post is part of the Real-World Evidence Toolkit — a companion reference with RCT reporting checklists, intent-to-treat analysis templates, and hybrid RCT/RWE comparison scaffolds.
Friedman, Lawrence M., Curt D. Furberg, David L. DeMets, David M. Reboussin, and Christopher B. Granger. 2015. Fundamentals of Clinical Trials. 5th ed. Springer.
Moher, David, Sally Hopewell, Kenneth F. Schulz, et al. 2010. “CONSORT 2010 Explanation and Elaboration: Updated Guidelines for Reporting Parallel Group Randomised Trials.”BMJ 340: c869. https://doi.org/10.1136/bmj.c869.
Sibbald, Bonnie, and Martin Roland. 1998. “Understanding Controlled Trials: Why Are Randomised Controlled Trials Important?”BMJ 316 (7126): 201. https://doi.org/10.1136/bmj.316.7126.201.