Opacity, Accountability & Ethical Failure Modes in Clinical AI
Ethics of Clinical AI — Lecture 1 of 4
Data InDeed | dataindeed.org
2026-01-01
The question is not whether the model is interpretable. The question is whether the deployment is defensible.
What You’ll Learn Today
Post 01 Opacity & Interpretability
- When black boxes are ethically defensible
- The cost of demanding full interpretability
- Performance as an ethical property
- Explanation ≠ justification
Post 02 Accountability Without Interpretability
- Who owns a model’s decision?
- The accountability stack
- Traceability, not transparency
- Governance as the accountability mechanism
Post 03 Ethical Failure Modes in Registry Data
- Bias before the model
- Selection, measurement, documentation bias
- Survivorship and temporal bias
- Where to actually look for ethical failures
Part 1
Opacity & Interpretability
When black boxes save lives
The Standard Critique of Black Box Models
The popular argument:
“Clinical AI must be interpretable because clinicians need to understand why the model made its recommendation before they can trust it.”
The assumptions embedded in this argument:
- Interpretability produces understanding
- Understanding is required for appropriate use
- Clinicians routinely interrogate clinical tools at the mechanism level
- Post-hoc explanation is equivalent to trustworthiness
All four are contestable.
The clinical reality:
Clinicians use blood pressure readings, troponin assays, and pulse oximeters without understanding the underlying sensor physics or assay biochemistry.
What they require: validation, calibration, known failure modes, and clear decision context. Not a causal pathway through the measurement.
What “Opacity” Actually Means
Opacity refers to:
- The internal weights and learned representations of a neural network
- The exact feature interactions in a large ensemble
- Why a specific prediction was made for a specific patient
Opacity does not refer to:
- Whether the model has been validated
- Whether calibration is documented
- Whether failure modes are characterized
- Whether deployment conditions match training conditions
The conflation:
Opacity of mechanism ≠ Opacity of behavior
A black box can have:
- Well-documented performance across subgroups
- Prospective calibration data
- Audit logs of predictions
- Clear human override protocols
These are the ethically relevant properties — not the ability to explain a specific weight.
The Ethical Cost of Demanding Interpretability

If the interpretable model makes more errors, the demand for interpretability has a body count. The ethical case for a black box with strong governance is real.
Performance Is an Ethical Property
The traditional ethics framing:
- Interpretability → trust → appropriate use → good outcomes
The alternative framing:
- Validation → calibration → deployment conditions → monitoring → good outcomes
The second chain does not require interpretability. It requires governance.
When black boxes are ethically defensible:
- Performance is prospectively validated in the deployment population
- Calibration is documented and monitored continuously
- Failure modes are characterized and communicated
- Clinicians receive training on appropriate use and override authority
- An audit trail exists for every prediction and decision
The sepsis example:
A black box sepsis alert with AUC 0.87 and documented false positive rate of 12% — deployed with clear override protocol and continuous monitoring — is more ethically defensible than an interpretable logistic model with AUC 0.71 and no prospective validation.
The ethics are in the governance, not the glass box.
Explanation vs. Justification
The critical distinction:
Explanation: “Feature X contributed weight W to this prediction.”
Justification: “This prediction is reliable enough to support this clinical decision in this patient population.”
SHAP values and LIME provide explanation. They do not provide justification. Justification requires validation evidence — not post-hoc attribution.
Why this matters:
SHAP tells you which features drove the model score for patient 12345. It does not tell you whether the model’s overall behavior is trustworthy for that patient’s clinical context.
A clinician who sees SHAP values and concludes the model is justified is reasoning from explanation to justification — a logical gap that has caused real harm.
The trauma registry implication:
A trauma triage model with good SHAP explanations but no prospective calibration data in the deployed theater is not ethically justified — regardless of how interpretable it appears.
The question to ask: Has this model been validated in conditions like these? Not: Can the model explain its decision?
Part 2
Accountability Without Interpretability
Traceability, not transparency
Why Interpretability Gets Mistaken for Accountability
The intuition:
If we can see inside the model, we can hold it accountable.
The problem:
Models cannot be held accountable. They have no agency, no authority, and no consequences.
Accountability is a property of people and institutions. It requires:
- Someone who made a decision
- A record of what was decided
- Authority to act and responsibility for consequences
- A mechanism for oversight and correction
The dangerous comfort of “the model did it”:
When accountability is attributed to the model — through interpretability, audit logs of weights, or SHAP values — it displaces from the humans who deployed it, set the thresholds, trained the clinicians, and monitored the outcomes.
This displacement is not neutral. It is an accountability gap that protects institutions at the expense of patients.
The Accountability Stack
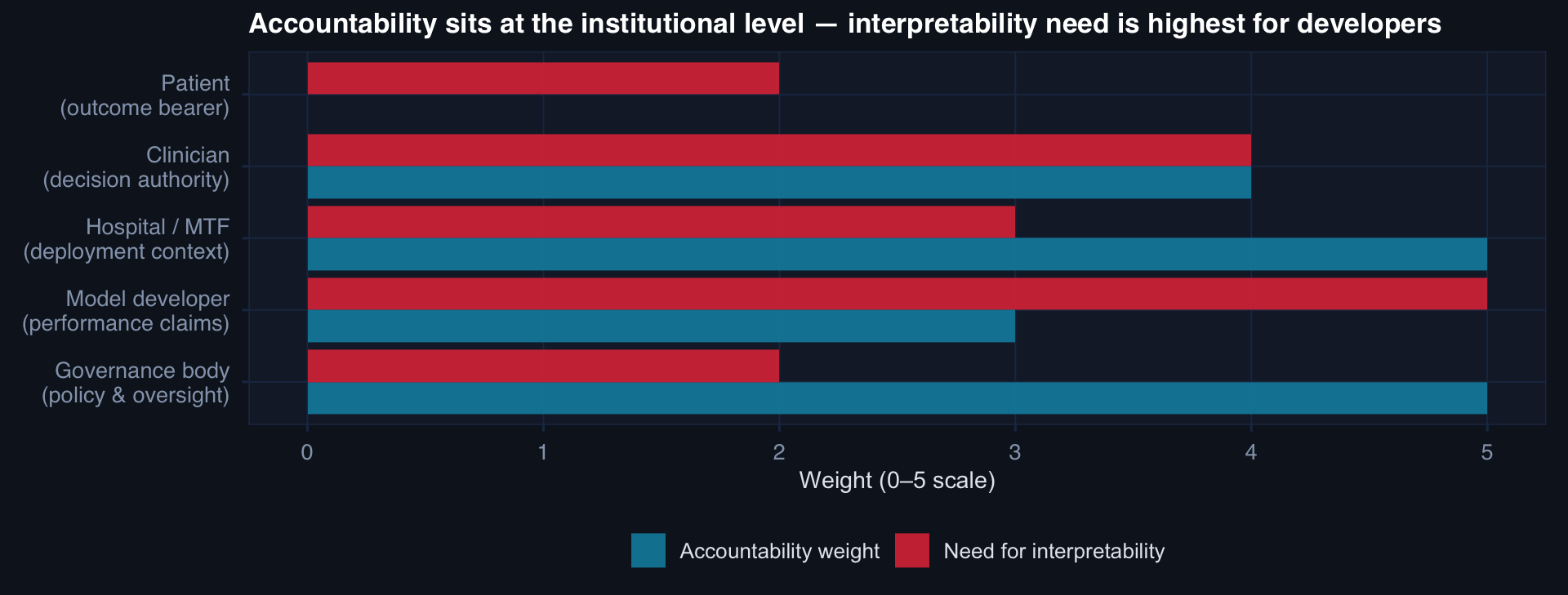
Accountability is highest at the institutional level — the hospital or MTF that deploys the model and the governance body that sets the policy. Interpretability of the model itself is most relevant to developers — not to the accountability chain for a specific decision.
Accountability Requires Traceability
What traceability requires:
# Every prediction that enters a clinical workflow must:
prediction_log <- list(
patient_id = "12345",
model_version = "mortality_v2.3.1",
model_hash = "sha256:a3f7c1d...",
prediction = 0.31,
threshold = 0.25,
alert_fired = TRUE,
clinician_id = "MD-0412",
override = FALSE,
override_reason = NA,
timestamp = "2026-09-01 14:32:07 UTC",
data_snapshot_hash = "sha256:b2e9f..."
)This log is the accountability artifact — not the SHAP values.
DoDTR context:
Every model prediction that informs a triage decision, a resource allocation, or a clinical practice guideline recommendation must be traceable to:
- The model version and training data
- The input data used for that prediction
- The clinician who received it
- The action that followed (or didn’t)
Without this, a post-incident review cannot determine whether the model contributed to harm — or protected against it.
Part 3
Ethical Failure Modes in Registry Data
Bias before the model
The Myth: Bias Is a Model Problem
The standard framing:
A biased model → biased predictions → unfair outcomes. Fix: debias the model (reweighting, adversarial training, fairness constraints).
The upstream reality:
A biased registry → a biased training set → a model that learned real patterns — in a population that was itself shaped by systemic inequities.
“Debiasing” a model trained on biased data doesn’t undo the bias — it launders it.
Where ethical failure actually begins:
- Selection — who enters the registry
- Measurement — what gets recorded under pressure
- Documentation — what the system rewards capturing
- Survivorship — who is followed up
- Temporality — when data is recorded relative to outcomes
The implication:
Ethical analysis of a registry model must begin at the data dictionary and the inclusion criteria — not the loss function.
If the registry underrepresents severely injured patients who died in the field, every model trained on it will underestimate severe injury mortality.
Selection Bias: Who Enters the Registry
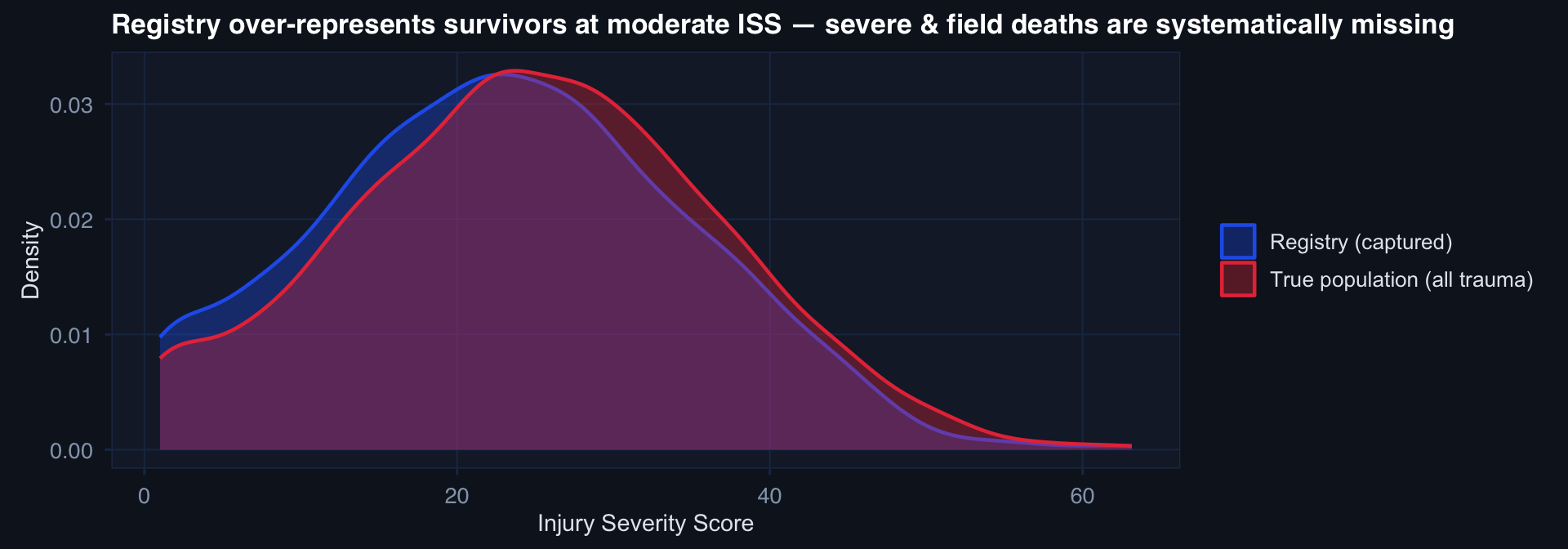
The model sees only the red distribution. Any model trained on registry data will have implicitly learned: “What predicts outcomes in patients who survived to Role 2.” Not: “What predicts outcomes in all trauma patients.”
Measurement and Documentation Bias
Measurement bias:
What gets measured depends on who is being measured, who is doing the measuring, and what tools are available.
- Lactate drawn for hemodynamically unstable patients → missing for stable patients (informative missingness)
- GCS assessed by trained medic at Role 1 ≠ GCS assessed by ER nurse at Role 3
- Pain scores vary by documented cultural norms, not just pain experience
Documentation bias:
What gets documented depends on what the system rewards:
- ICD code selection for billing vs. clinical accuracy
- Abstractors completing required fields with plausible defaults
- High-tempo care: fewer fields completed, greater missing rate
Survivorship bias:
The quietest failure mode:
Patients who die before discharge disappear from follow-up. If you analyze 30-day outcomes, you only observe patients who survived long enough to have 30 days of data.
Long-term outcomes (PTSD, TBI sequelae, limb function) are only observed in survivors — meaning every model of long-term outcomes has built-in survivorship bias.
There is no statistical fix. The fix is documentation: acknowledging who is not in the data.
Temporal Bias: Using the Future to Explain the Past
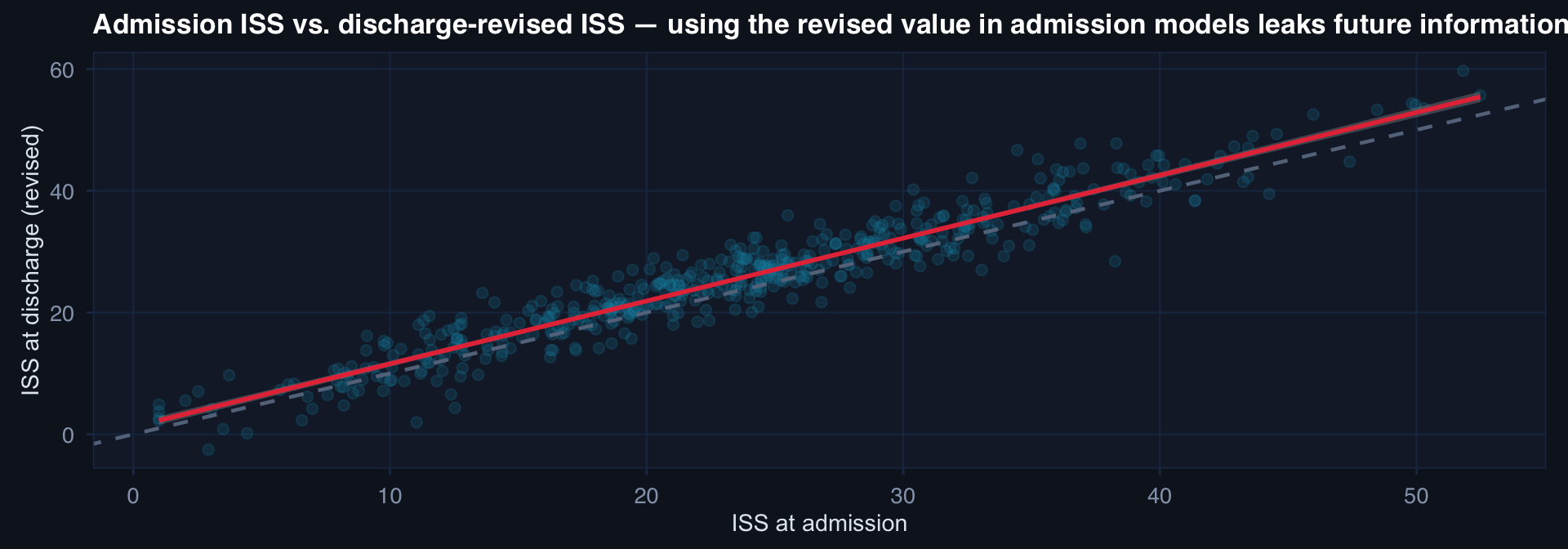
Using discharge-revised ISS or post-hoc complications as predictors in an admission-time model is temporal leakage. The model will appear better than it is at deployment — where only admission-time data is available.
Lecture 1 — Key Takeaways
Opacity & Interpretability
- Demanding interpretability has a performance cost — performance is an ethical property
- Explanation (SHAP/LIME) ≠ justification (validation evidence)
- Black boxes are ethically defensible when governance is strong: validation, calibration, failure mode characterization, monitoring, audit trails
- The ethical question: Is deployment defensible? Not: Can we see the weights?
Accountability
- Models cannot be accountable — people and institutions can
- “The model did it” is accountability displacement
- Accountability requires traceability: model version, data snapshot, prediction, decision, outcome
- Interpretability is most relevant to developers — accountability sits at the institutional level
Ethical Failure Modes
- Bias is upstream: selection, measurement, documentation, survivorship, temporality
- The registry captures who survived to be captured — not the true population
- Measurement bias is informative: missing lactate ≠ normal lactate
- Temporal leakage: using discharge-revised variables in admission-time models
- “Debiasing” a model trained on biased data launders — it does not fix
The meta-lesson: The ethical work in clinical AI is front-loaded — in how the registry was built, who was captured, what was measured, and how the deployment is governed. Statistical methods cannot repair upstream failures.
Coming Up: Lecture 2
Prediction, Human Oversight & The Ethics of Data Exclusion
Posts 04, 05 & 06:
- Prediction vs. responsibility — why risk scores can be ethically dangerous
- Human-in-the-loop — why nominal oversight often fails
- Excluding messy patients — when data cleaning becomes a moral decision
![]()
Data InDeed · Ethics of Clinical AI · Lecture 1 | ⚡ Open App