Prediction, Human Oversight & The Ethics of Data Exclusion
Ethics of Clinical AI — Lecture 2 of 4
Data InDeed | dataindeed.org
2026-01-01
A risk score predicts. It does not decide. It does not justify. It does not bear responsibility.
What You’ll Learn Today
Post 04 Prediction vs. Responsibility
- How risk scores become moral shortcuts
- High accuracy ≠ no moral burden
- When prediction launders policy
- Trauma settings intensify the problem
Post 05 Human-in-the-Loop
- Why HITL feels like a safeguard
- Automation bias: rubber-stamping machines
- Cognitive load as the silent killer
- Meaningful authority vs. nominal oversight
Post 06 Ethics of Excluding Data
- Who are “messy” patients?
- Exclusion changes the population being modeled
- “Data quality” as a proxy for privilege
- When exclusion is ethically defensible
Part 1
Prediction vs. Responsibility
Risk scores predict — they do not legitimize
Risk Scores Predict; They Do Not Legitimize
What a risk score does:
Given features X, a risk score outputs P(outcome | X, model). It summarizes the statistical relationship between observed features and a historical outcome in a specific population.
What a risk score does not do:
- Determine that a patient deserves a particular resource allocation
- Establish that withholding care is appropriate
- Transfer moral responsibility from the clinician who acted to the model that predicted
- Guarantee that the historical population reflects the current patient
The ethical shift:
When a risk score of 0.85 is used to justify a care withholding decision, the question changes from “What does this patient need?” to “What does the model say about this patient’s probability of benefit?”
The trauma triage scenario:
A mass casualty event produces 40 patients. A triage algorithm assigns priority scores. Those with scores below 0.2 are designated expectant.
The score does not know: this patient has a contraindication to the standard protocol. This model was trained before this mechanism of injury was common. The model’s calibration has drifted since the last validation.
The score predicted. The human decided. But did the human review the score or ratify it?
How Risk Scores Become Moral Shortcuts
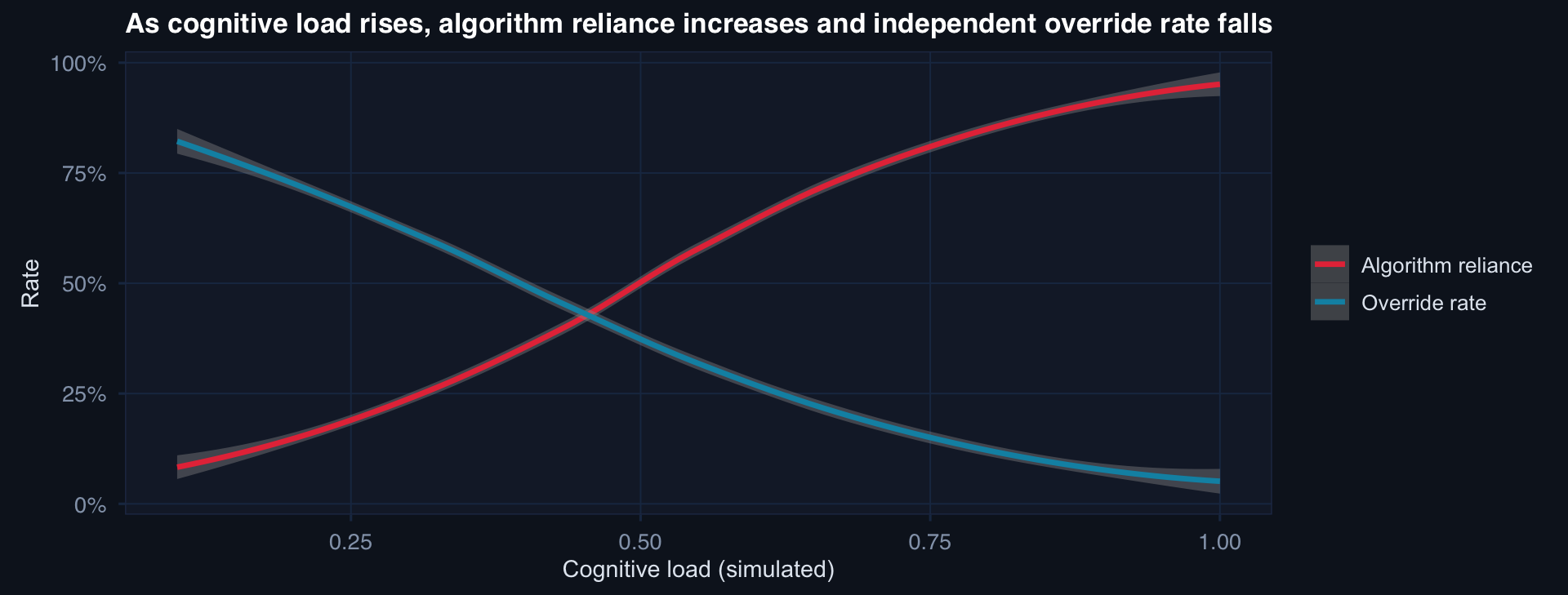
The moral risk is highest exactly when the environment is most demanding. In trauma, mass casualty, and high-tempo operations — when cognitive shortcuts are most attractive — the conditions for automation bias are maximally present.
Historical Data Are Not Moral Ground Truth
The laundering argument:
“We’re not making this decision — the model is. The model learned from thousands of historical cases.”
The problem:
If historical decisions reflected system-level inequities — differential access, varying standards of care, documentation gaps — then the model has learned to reproduce those inequities.
A model that was trained on data where patients from under-resourced settings had worse outcomes will predict worse outcomes for similar patients at deployment — and if that prediction is used to allocate resources, the inequity becomes self-perpetuating.
The historical data are not a moral baseline. They are a record of what happened — including what happened that was unjust. Using “the model learned from data” as a justification implicitly endorses everything embedded in that history.
Trauma Settings Intensify the Problem
Standard clinical settings:
- One patient, one clinician, deliberate decision pace
- Time for override, second opinion, chart review
- Patient can advocate, family can intervene
- Documentation is routine and retrievable
Trauma / mass casualty settings:
- Many patients, scarce resources, compressed time
- Override requires deliberate resistance to cognitive default
- Severely injured patients often cannot advocate
- Documentation is retrospective and incomplete
The compounding effect:
In mass casualty events, a risk score that is probably right for most patients will occasionally be wrong. In a standard setting, the wrong decision is one tragedy. In a MASCAL with 40 patients processed in 20 minutes, the wrong decision rate is multiplied across a cohort — and the feedback loop for correction is hours or days away.
The stakes of prediction errors in trauma are not normally distributed. They are clustered at the worst moments.
Part 2
Human-in-the-Loop
Why nominal oversight often fails
Why HITL Feels Like a Moral Safeguard
The intuition:
“We have a human in the loop. The model recommends; a clinician decides. Therefore accountability is preserved.”
What this gets right:
- A human has formal decision authority
- There is a nominal override mechanism
- The model is not making final decisions autonomously
What this misses:
- Whether the human has the capacity to meaningfully evaluate the recommendation
- Whether the interface design encourages review or ratification
- Whether override is practical in the deployed workflow
- Whether the clinician has training to know when to override
The critical question HITL rarely answers:
Does the human have enough information, time, and cognitive bandwidth to exercise meaningful judgment — or are they rubber-stamping the algorithm?
If the answer is rubber-stamping, HITL is not a safeguard. It is liability transfer.
The institution can say “a clinician reviewed every decision” while providing conditions under which real review was impossible.
Automation Bias in Clinical Workflows
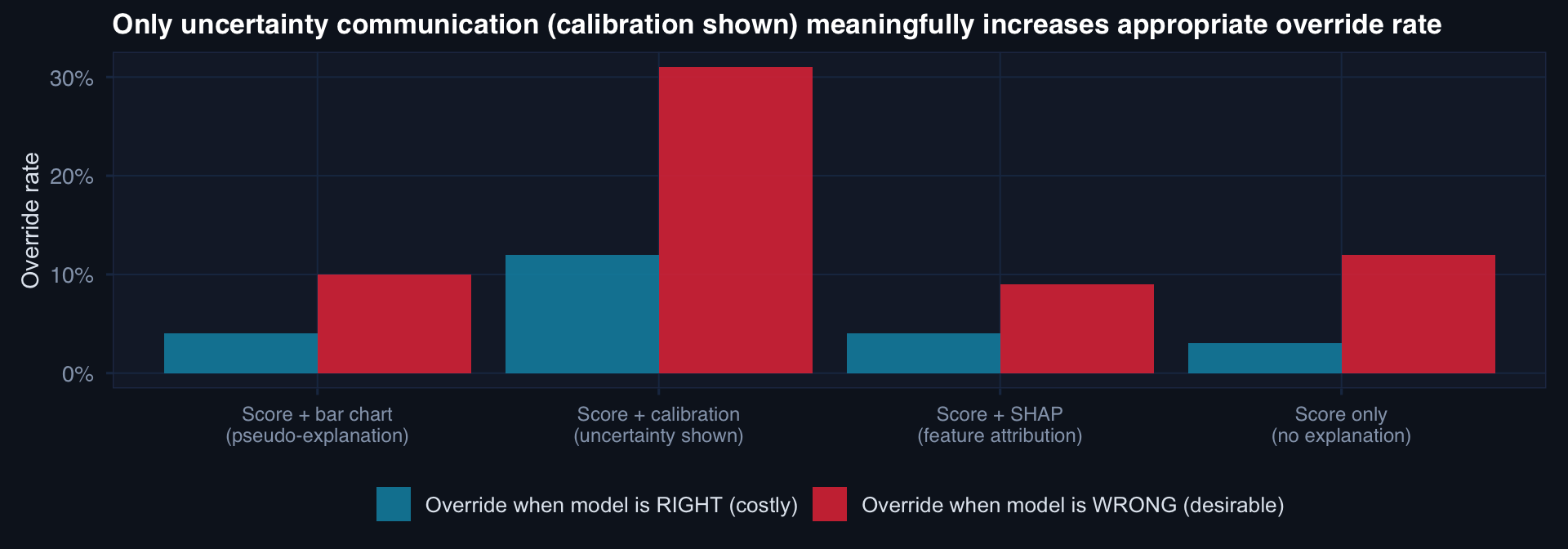
Adding visual explanation (bar charts, SHAP) does not reduce automation bias. Showing calibration and uncertainty intervals does — modestly. The interface is a governance decision.
When HITL Becomes Liability Transfer
The liability transfer mechanism:
- Institution deploys model with nominal override
- Workflow is designed so override is friction-heavy (extra clicks, documentation burden)
- Cognitive load + time pressure → clinicians rarely override
- Adverse event occurs following model recommendation
- Institution points to override mechanism: “The clinician reviewed and accepted the recommendation”
This is a governance failure, not a clinical failure. The institution designed a system in which meaningful review was unlikely — then used the form of HITL to shield itself from accountability.
What meaningful HITL requires:
- Competence: Clinician has training to evaluate when and why to override
- Information: Uncertainty, calibration, and failure modes are visible at the point of decision
- Time: Workflow design provides sufficient time for review — not just formal authorization
- Low-friction override: Override is as easy as acceptance
- Feedback: Clinicians learn when their overrides were correct or incorrect
All five are infrastructure investments — not just UI decisions.
Part 3
The Ethics of Excluding Data
When data cleaning becomes a moral decision
Who Are “Messy” Patients?
Common exclusion criteria in clinical modeling:
- “Missing key covariates” (ISS, GCS, vital signs)
- “Incomplete follow-up” (< 30-day outcome data)
- “Outlier values” (physiologically implausible readings)
- “Protocol deviations” (received non-standard care)
- “Insufficient volume” (facility with < 10 cases)
These sound methodologically reasonable. But:
Who is actually excluded:
- Missing ISS: Most severely injured patients — those who died before full assessment, or were cared for in austere settings without documentation infrastructure
- Incomplete follow-up: Transferred patients, those lost to contact, those in under-resourced settings
- Protocol deviations: The most complex patients — those for whom standard care was inappropriate
- Small facilities: Role 1 and Role 2 in contested environments
The “messy” patients are disproportionately the most severe, most marginalized, and most operationally important.
Exclusion Changes the Population Being Modeled
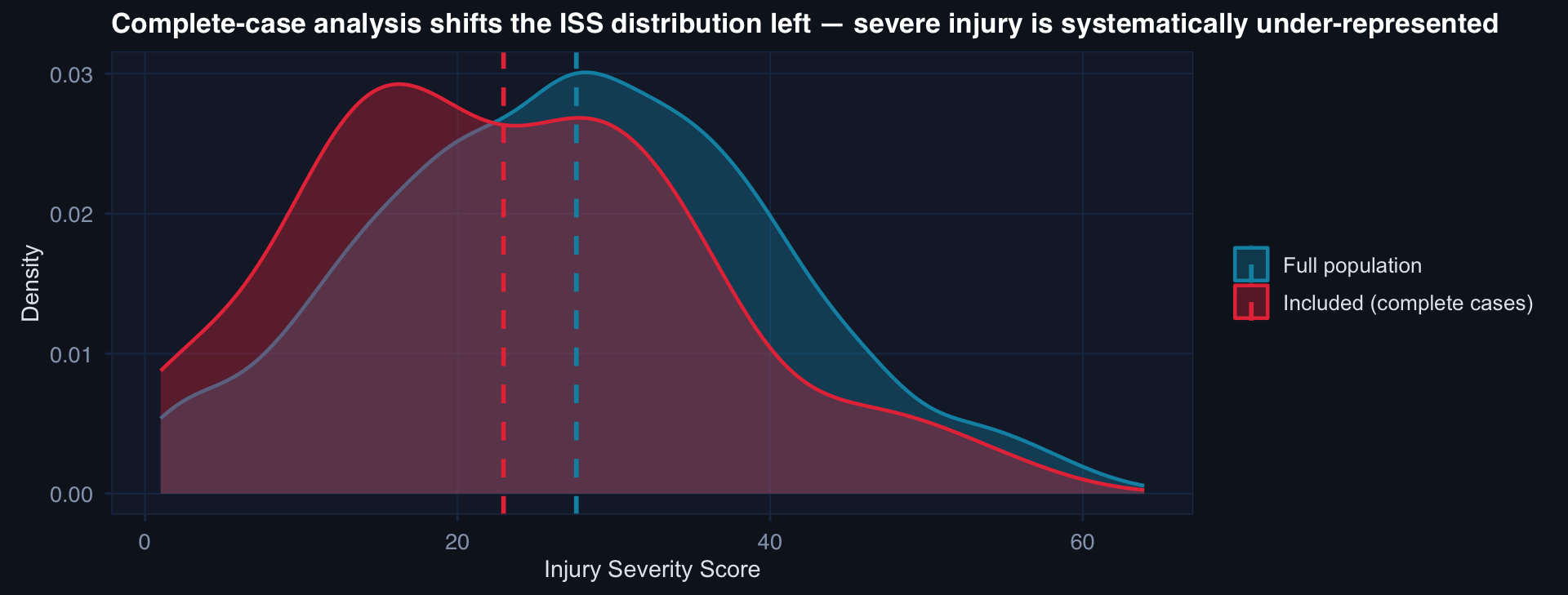
A model validated on complete cases will underestimate mortality risk for severe patients — exactly the patients for whom accurate risk estimation matters most.
“Data Quality” as a Proxy for Privilege
The uncomfortable observation:
Patients who generate “clean” data — complete records, standard presentations, routine follow-up — are systematically different from patients who generate “messy” data.
Clean data patients tend to have: better access to care before injury, more resources to engage with follow-up, injuries that present within standard clinical pathways, documentation infrastructure at their care site.
“Data quality” is not random. It is correlated with social, geographic, and operational determinants of health. Excluding on “quality” therefore systematically excludes on these determinants.
The model learns to work best for patients who already have the best access to care. This is the opposite of where clinical AI capacity is most needed.
When Exclusion Is Ethically Defensible
Exclusion is defensible when:
- The excluded cases are explicitly documented (who, how many, why)
- The analysis explicitly acknowledges the resulting population being modeled
- The conclusions are not extrapolated to the excluded population
- Sensitivity analyses check whether exclusion changes key estimates
- The estimand is defined before exclusion decisions are made
Exclusion is not defensible when:
- The excluded population is precisely the population the model will be deployed on
- Exclusions are made post-hoc to improve model performance metrics
- The analysis claims generalizability to the full population
- No sensitivity analysis is conducted
The ethical alternative to exclusion:
- Multiple imputation — model the missing data structure explicitly
- Estimand redefinition — clearly state you are modeling the complete-case subpopulation
- Sensitivity to exclusion — show results with and without each major exclusion criterion
- Representativeness analysis — document how excluded cases differ from included cases
The discipline is not in excluding cleaner patients — it is in being explicit about what population your model actually serves.
Lecture 2 — Key Takeaways
Prediction vs. Responsibility
- Risk scores predict — they do not legitimize decisions or transfer moral responsibility
- Historical data encode historical inequities — using them as justification launders injustice
- Automation bias is highest under maximum cognitive load — exactly when stakes are highest
- Trauma settings amplify every failure mode: compressed time, scarce resources, vulnerable patients
Human-in-the-Loop
- HITL is a governance standard, not a checkbox
- Automation bias: visual explanation doesn’t help; uncertainty communication helps modestly
- Liability transfer: designing conditions where meaningful review is unlikely, then claiming oversight
- Meaningful HITL requires: competence, information, time, low-friction override, feedback
Ethics of Data Exclusion
- “Messy” patients are disproportionately the most severe, most marginalized
- Complete-case exclusion shifts the modeled population toward less severe injury
- “Data quality” correlates with social determinants — exclusion is not neutral
- Defensible exclusion: documented, explicit population definition, sensitivity analyses, no extrapolation beyond the included population
The meta-lesson: Prediction, oversight, and exclusion are three distinct ethical decision points — each with its own failure mode. None of them can be resolved by better statistics alone. All of them require institutional governance.
Coming Up: Lecture 3
Fairness, Performance Monitoring & The Ethics of Automation
Posts 07, 08 & 09:
- Missingness as a fairness issue — who gets modeled and who gets left behind
- AI performance monitoring — why validated-at-deployment is not a safety guarantee
- CPG compliance automation — ethics of speed in guideline monitoring
![]()
Data InDeed · Ethics of Clinical AI · Lecture 2 | ⚡ Open App