Fairness, Performance Monitoring & The Ethics of Automation
Ethics of Clinical AI — Lecture 3 of 4
Data InDeed | dataindeed.org
2026-01-01
Fairness does not begin at the loss function. It begins at the registration desk, the field report, and the data dictionary.
What You’ll Learn Today
Post 07 Missingness as Fairness
- Missingness is rarely random across groups
- Exclusion as representation bias
- Clean data is often privileged data
- Fairness metrics can mask missingness bias
Post 08 AI Performance Monitoring
- What model drift actually is
- Validated-at-deployment ≠ safe-to-use
- Delphi mandate: continuous monitoring
- Alert mechanisms as ethical infrastructure
Post 09 Ethics of Automation
- What CPG compliance measures
- The five-level automation framework
- Data lineage as accountability
- What responsible automation requires
Part 1
Missingness as a Fairness Issue
Who gets modeled — and who gets left behind
Fairness Does Not Start at the Loss Function
The standard fairness framing:
Train a model → measure performance by subgroup → apply fairness constraints (equalized odds, demographic parity) → redeploy.
The upstream problem:
If Group A has 8% missing outcomes and Group B has 35% missing outcomes, the model was not trained on the same population for both groups.
No post-hoc fairness constraint corrects for this. The model has less information about Group B — structurally, by design, before a single weight is learned.
Fairness is a data quality problem before it is a modeling problem:
Group B appears less often in the training data → model has higher uncertainty for Group B → at deployment, Group B predictions are less reliable → adverse decisions fall disproportionately on Group B → Group B outcomes worsen → Group B representation in follow-up data decreases further
This is a self-reinforcing loop. Fairness constraints applied to the model alone do not break it.
Missingness Is Rarely Random Across Groups
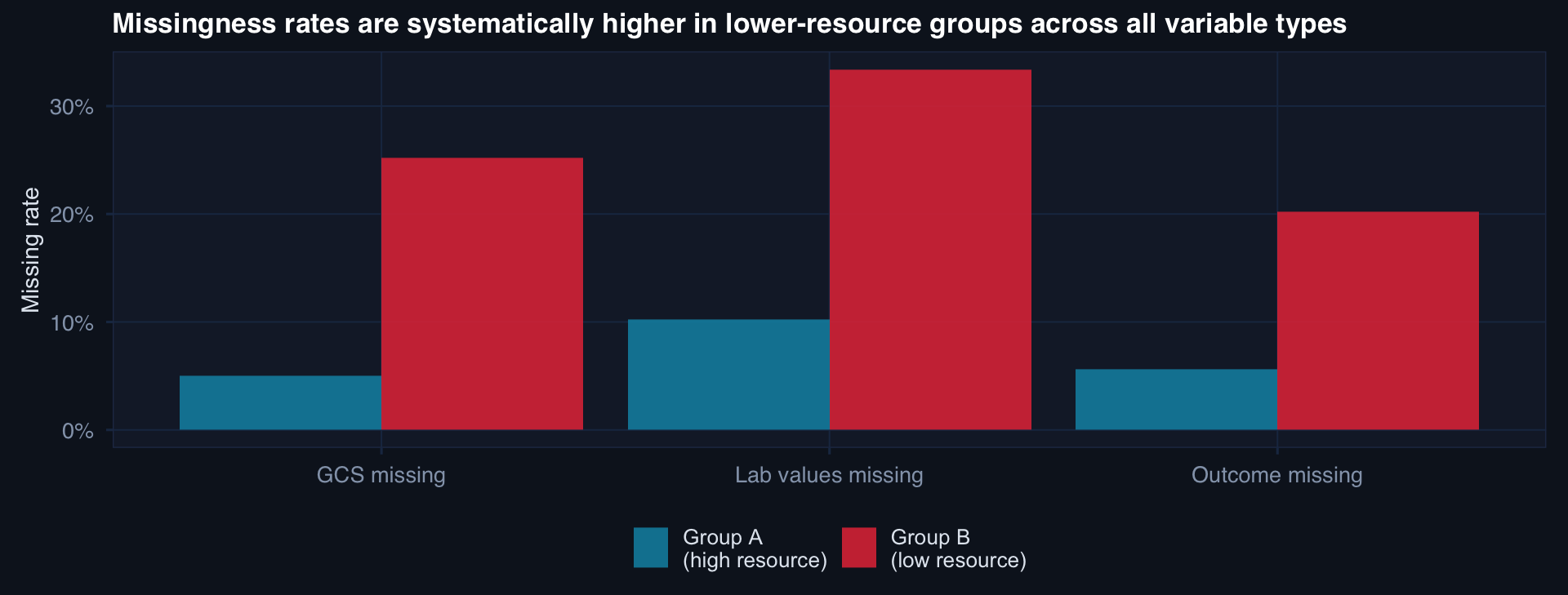
In DoDTR context: Role 1 and Role 2 care in contested environments generates substantially more missingness than Role 4 stateside. A model trained on this data is less reliable for exactly the care contexts that are most operationally critical.
Fairness Metrics Can Mask Missingness Bias
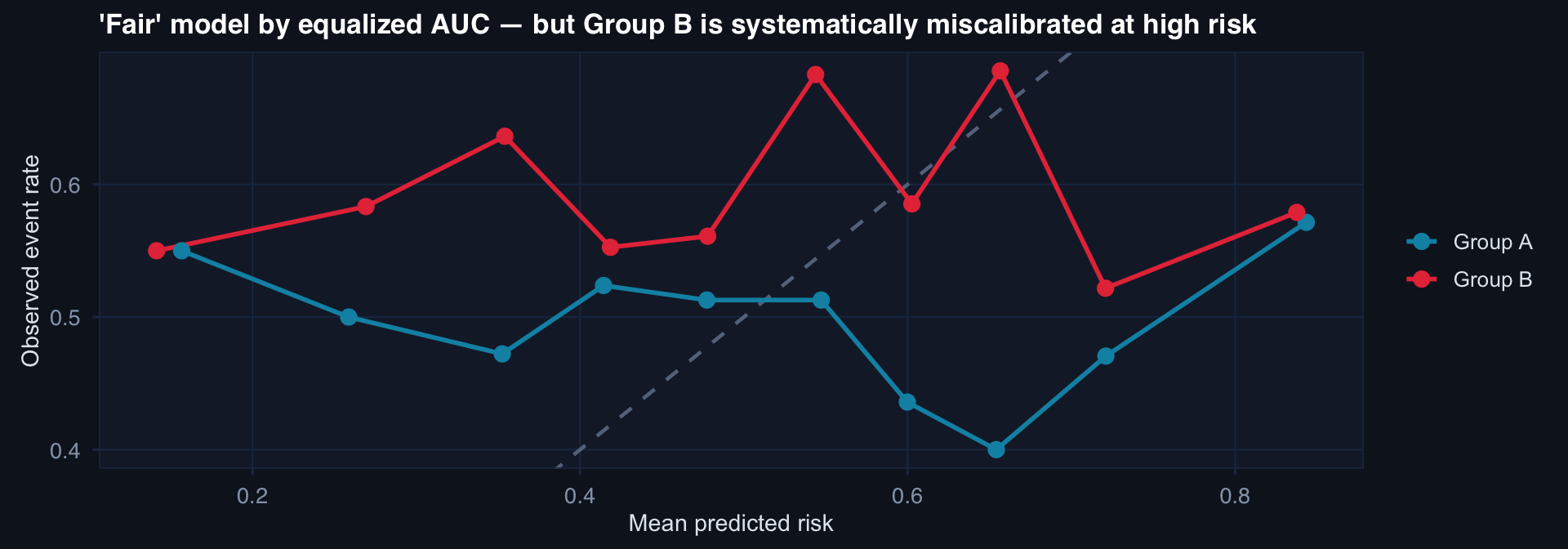
AUC can be equal across groups while calibration differs. Group B faces miscalibrated risk scores — the model says 40% when the true rate is 55%. Fairness constraints on discrimination metrics do not catch calibration failures.
Missingness-Aware Modeling as a Fairness Intervention
Standard approach (unfair by structure):
- Exclude patients with missing covariates
- Impute missing values with mean/mode (ignoring mechanism)
- Train model on complete or imputed data
- Apply fairness constraints to predictions
Missingness-aware approach:
- Document missing rates by subgroup before any exclusion
- Model the missingness mechanism (is it MCAR, MAR, MNAR?)
- Multiple imputation with substantively appropriate auxiliary variables
- Sensitivity analysis across imputation assumptions by subgroup
- Report uncertainty as a function of missingness — show that Group B predictions carry higher uncertainty
The reporting standard:
Every model report should include:
- Missing rate by subgroup for each key variable
- Missingness mechanism assessment
- Sensitivity of subgroup performance estimates to imputation assumptions
If Group B performance cannot be reliably estimated due to high missingness, the honest answer is: “We do not have sufficient data to characterize model performance for Group B.”
That is a governance failure — not a modeling failure. Fix the data collection, not the model.
Part 2
AI Performance Monitoring
You can’t trust what you don’t track
What Model Drift Actually Is
Concept drift: The relationship between predictors and outcome changes over time. Protocol changes, population shifts, new injury mechanisms, updated care standards — all can shift P(Y|X) such that a model trained on historical data makes systematically wrong predictions.
Covariate shift: The input distribution P(X) changes — the case mix, injury severity distribution, mechanism of injury, or patient demographics at deployment differ from training. The model may have learned correctly but is now being applied to out-of-distribution patients.
Label shift: P(Y) itself changes — overall mortality rates improve with care protocols, or worsen with case mix. A well-calibrated historical model becomes miscalibrated as base rates shift.
Why “validated at deployment” is insufficient:
A model validated in 2023 with AUC 0.83 and good calibration:
- 2024: New tourniquet protocol introduced → covariate shift
- 2025: New theater opens with different injury mix → covariate shift
- 2026: Major protocol change → concept drift
The model may now have AUC 0.74 and poor calibration — but no one knows, because validation happened once, three years ago.
The moment of deployment is the beginning of validation — not the end.
Continuous Monitoring as Ethical Infrastructure
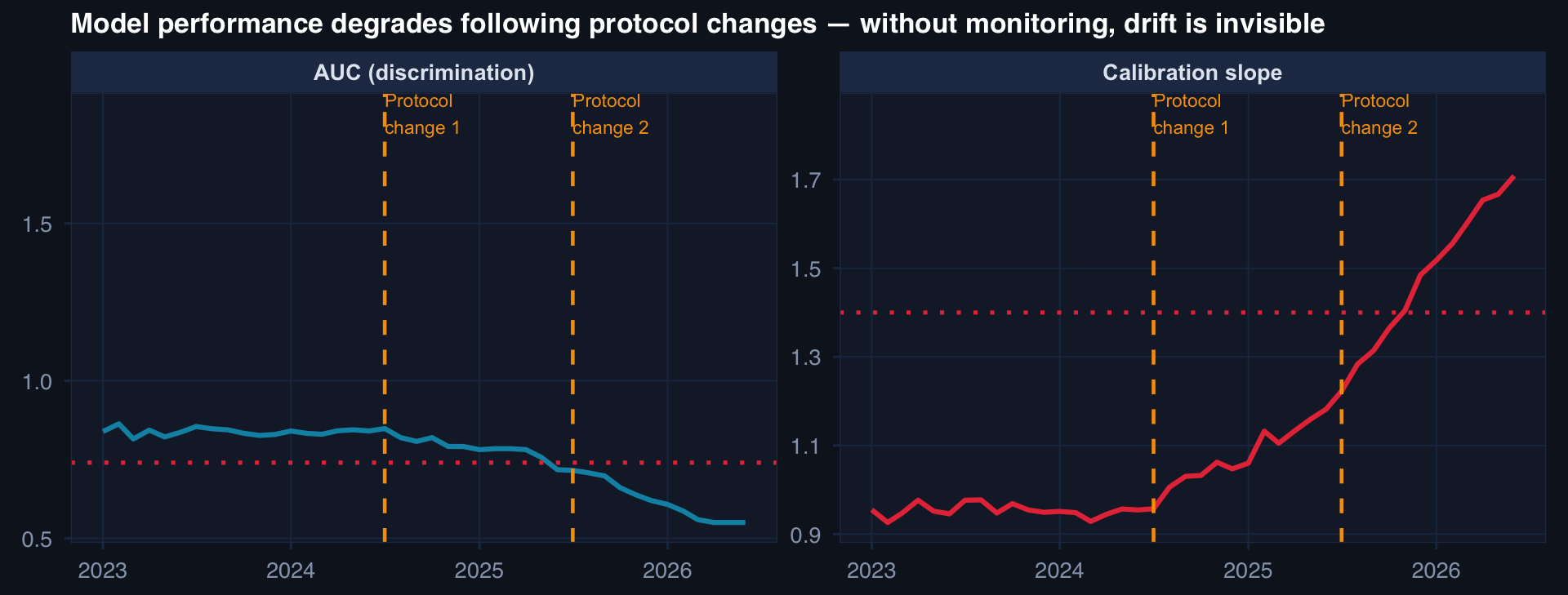
Red dashed lines: alert thresholds. Neither is crossed in the monitored data — but without monitoring, the drift would be completely invisible. The governance question: who is watching these panels, and what do they do when an alert fires?
The Delphi Mandate: Monitoring Is Not Aspirational
What the Delphi consensus on responsible AI requires:
“Continuous performance monitoring is a required component of responsible clinical AI deployment — not an optional enhancement.”
What this means operationally:
- Prospective calibration data: Real outcomes collected after deployment, linked to predictions
- Scheduled re-evaluation: AUC and calibration assessed at fixed intervals (monthly minimum for high-stakes models)
- Alert thresholds pre-specified: What performance level triggers review? Who reviews? In what timeframe?
- Expert feedback loops: Clinicians can report cases where the model appears wrong — these feed back into performance assessment
- Retirement criteria: Pre-specified conditions under which the model is suspended pending revalidation
The ethical implication:
Deploying a clinical AI without continuous monitoring is not a neutral decision about resource allocation. It is a decision to accept unknown harm as it accumulates — invisibly — until it becomes large enough to notice without monitoring.
The monitoring infrastructure is not optional overhead. It is the mechanism by which deployment remains ethically defensible over time.
Part 3
Ethics of Automating CPG Compliance
Speed is not the ethical risk — selective slowness is
What Clinical Practice Guideline Compliance Measures
CPG compliance monitoring asks:
Are patients receiving the care that evidence says they should receive?
- Tourniquet applied within 30 minutes of penetrating extremity injury?
- REBOA deployed for hemodynamically unstable torso injury?
- Damage control resuscitation initiated within 15 minutes?
- TXA administered within 3 hours?
Why this is an ethical issue:
When guideline compliance is measured monthly or quarterly, patients harmed by non-compliance in January are not identified until April — if ever.
Delayed compliance information is the same as no compliance information, for the patient affected.
The ethics of selective monitoring:
Many registries monitor mortality rates in near-real-time but measure CPG compliance quarterly.
If a care process deviation is harming patients, the harm accumulates for weeks before detection.
Selective monitoring — fast for outcomes that protect institutions, slow for processes that could implicate them — is not a neutral data decision.
The ethical standard: Monitor the process as close to real-time as the data infrastructure allows.
The Five-Level Automation Framework
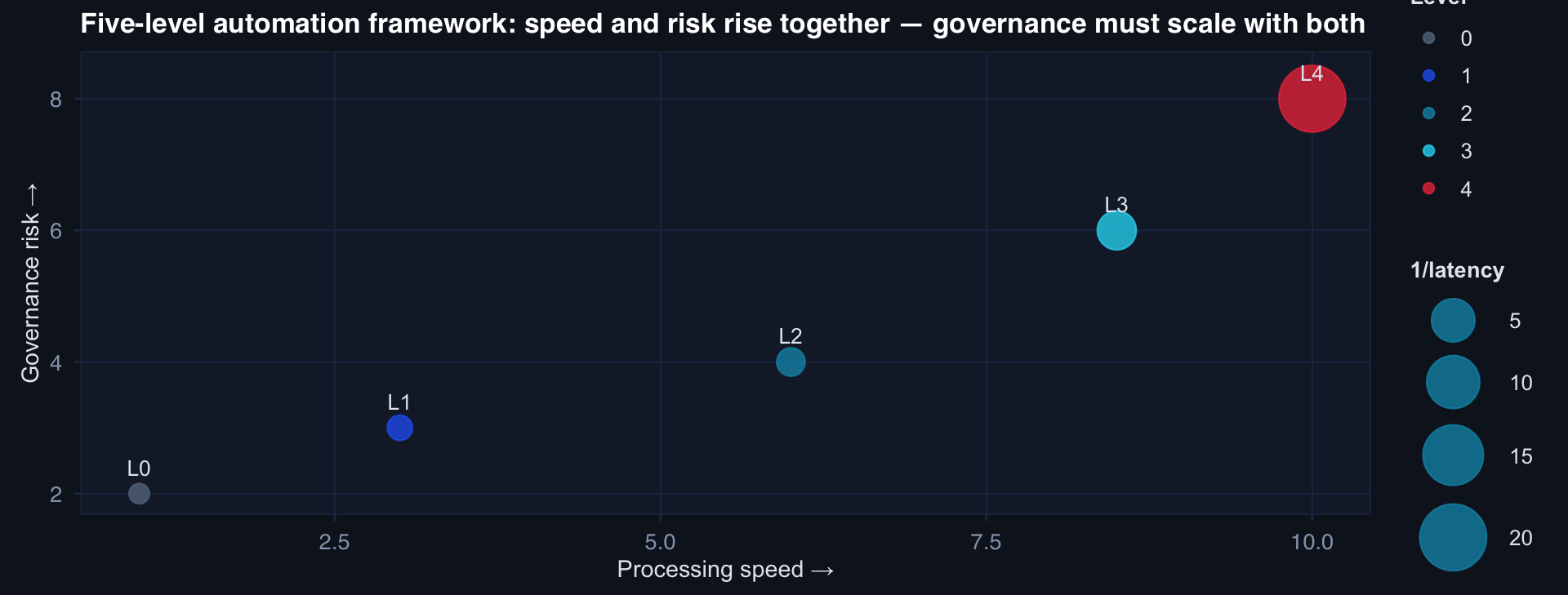
Higher automation levels deliver faster compliance data — which is ethically valuable. They also require stronger governance: audit trails, exception protocols, definition versioning, and prompt-level documentation.
Data Lineage as Accountability Infrastructure
What data lineage must capture:
compliance_event:
case_id: "TR-20261003-4421"
metric: "tourniquet_within_30min"
result: "compliant"
result_timestamp: "2026-10-03T14:22:07Z"
evidence_chain:
- source: "TCCC_card_field_note"
extraction: "NLP_v3.1"
extracted_value: "TQ applied 14:08"
confidence: 0.91
- source: "Role2_admission_note"
extraction: "rule_v2.0"
extracted_value: "TQ on arrival: yes"
definition_version: "JTS_CPG_tourniquet_v4.2"
definition_hash: "sha256:d3f9a1..."
review_required: false
reviewer: nullThis is the audit artifact. Without it, “compliant” is an assertion — not a finding.
The test patient problem:
When automated systems generate compliance metrics, how do we know the pipeline is working?
The ethical requirement: a known test case (a “canary patient” with known ground truth compliance status) is processed by the pipeline regularly. If the pipeline misclassifies the test patient, an alert fires.
This is not a technical edge case. In an autonomous pipeline, a silent system failure can produce weeks of incorrect compliance data — with downstream implications for clinical practice review, quality improvement, and J9 briefs.
Lecture 3 — Key Takeaways
Missingness as Fairness
- Missingness rates differ systematically by group — this is a structural fairness problem, not random noise
- Fairness metrics (AUC parity) can mask calibration failures in high-missingness groups
- The honest answer when Group B missingness is high: “We cannot characterize model performance for Group B” — fix the data collection
- Missingness-aware modeling: document rates by subgroup, model the mechanism, report subgroup-specific uncertainty
AI Performance Monitoring
- Validated at deployment = beginning of validation, not the end
- Three drift types: concept drift, covariate shift, label shift
- Monitoring is ethically required — not optional
- Pre-specify: alert thresholds, review protocol, retirement criteria
Ethics of Automation
- Selective slowness — fast monitoring for institutional outcomes, slow for care processes — is an ethical failure
- Five-level automation framework: each level delivers faster data and requires stronger governance
- Data lineage is the accountability artifact: source, extraction method, confidence, definition version
- Test patients / canary cases are required to detect silent pipeline failures
- AI-generated definition candidates require human review before deployment
The meta-lesson: Fairness, monitoring, and automation are all infrastructure questions — not algorithm questions. The ethics are in the governance architecture: who watches, what triggers action, what gets documented, and who is accountable when the system fails.
Coming Up: Lecture 4
Semantic Infrastructure, Responsible AI & DoDTR Modernization as an Ethical Imperative
Posts 10, 11 & 12:
- Ontology is not optional — semantic infrastructure as ethical foundation
- What responsible AI in clinical guidance actually requires — beyond the checklist
- DoDTR modernization — an ethical and technical imperative
![]()
Data InDeed · Ethics of Clinical AI · Lecture 3 | ⚡ Open App