Semantic Infrastructure, Responsible AI & DoDTR Modernization
Ethics of Clinical AI — Lecture 4 of 4
Data InDeed | dataindeed.org
2026-01-01
The vocabulary is not a technical detail. It is the foundation on which every ethical claim about the data rests.
What You’ll Learn Today
Post 10 Semantic Infrastructure as Ethics
- Local codes are an ethical problem
- OMOP CDM as shared semantic foundation
- The civilian-military translation problem
- Ontology governance as a political act
Post 11 Responsible AI — Beyond the Checklist
- What Delphi consensus gets right
- Six gaps the consensus leaves open
- AI literacy as a precondition
- PHI in LLM workflows as catastrophic risk
Post 12 DoDTR Modernization
- The status quo has a body count
- What modernization actually requires
- The five-level framework as ethical scaffolding
- Responsible modernization architecture
Part 1
Semantic Infrastructure as Ethical Foundation
Ontology is not optional
Local Codes Are an Ethical Problem
What local codes mean in practice:
A trauma registry built on local codes has:
"GSW_ABD"at Site A = gunshot wound, abdominal, confirmed penetrating"ABDO_PEN"at Site B = abdominal penetrating trauma (includes blast)"PENET_TORSO"at Site C = penetrating torso (may include thoracic)
These are not the same thing. A federated query that pools them treats them as equivalent.
The result: a multi-site mortality analysis that compares apples, oranges, and blast injuries — labeled identically.
The ethical implication:
When a clinical practice guideline is developed using pooled multi-site data built on local codes, the guideline is based on a fiction of definitional consistency.
If the guideline is wrong because the underlying data was inconsistently defined, the harm falls on patients — not on the data architects who chose local codes for convenience.
Using local codes in a registry intended to support multi-site analysis or CPG development is an ethical failure of infrastructure design.
OMOP CDM as Shared Semantic Infrastructure
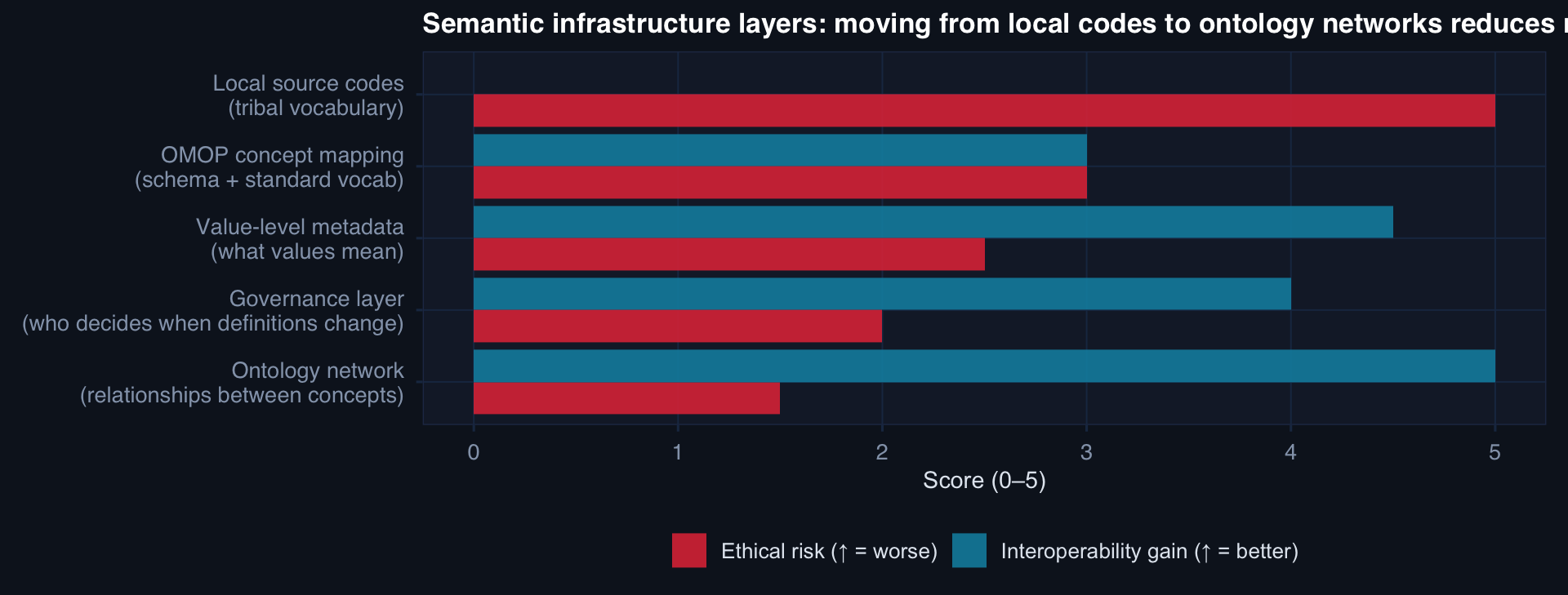
OMOP CDM addresses the first two layers. Value-level metadata, governance, and ontology networks require additional institutional investment — but they are the layers that make federated research actually reliable.
The Civilian-Military Translation Problem
The semantic gap is real and consequential:
| Civilian EHR | Military / DoDTR | Semantic equivalent? |
|---|---|---|
| ICU admission | Role 3 stabilization | Partial |
| OR / surgery | Damage Control Surgery | No |
| Ambulance transport | CASEVAC / MEDEVAC | No |
| Emergency dept | Role 2 / Aid station | No |
| Transfer | Echelon transition | No |
Why this matters:
When civilian EHR data is mapped to OMOP and DoDTR data is mapped to OMOP separately — using different source value mappings — a federated query may silently compare incomparable care episodes.
The ethical requirement:
A trauma registry that serves both civilian and military populations must document:
- Where civilian and military concepts map to the same OMOP concept_id
- Where they are semantically different despite sharing a code
- What analytical precautions are required for cross-sector pooling
This is not a technical footnote. It is a required section of every data use agreement and methods section in any study that crosses the civilian-military boundary.
Ontology Governance as a Political Act
The governance question:
Who decides what “penetrating trauma” means in the DoDTR? Who decides when that definition changes? Who is notified when it changes? How are historical records handled after a definitional change?
These are not technical questions. They are political questions with ethical stakes. Whoever controls the ontology controls what the data says — and therefore what the evidence supports.
What responsible ontology governance requires:
- A named governance body with documented authority
- A versioned change-control process with amendment history
- Notification protocol for all data users when definitions change
- Retrospective impact assessment: how many records are affected by a definitional change?
- A published data dictionary with effective dates for every value-level definition
Without governance:
A definition change propagates silently through the registry. Historical analyses become non-reproducible. Two publications using “the same registry” with different extraction dates reach different conclusions — not because the data changed, but because the vocabulary did.
The scientists, clinicians, and policy makers who rely on those publications have no way to know.
Part 2
Responsible AI in Clinical Guidance
Beyond the checklist
What the Delphi Consensus Gets Right
Five themes the consensus addresses well:
- Transparency and explainability — models must document their assumptions and limitations, not just their performance metrics
- Validation requirements — local validation is not optional; global validation does not transfer
- Human oversight — clinical AI must support, not replace, clinical judgment
- Equity considerations — subgroup performance must be assessed and reported
- Continuous monitoring — performance must be tracked post-deployment, not just at release
These are correct, important, and well-specified.
Why checklists are necessary but insufficient:
A checklist tells you what to do. It does not tell you when it’s hard, what to do when requirements conflict, or how to make judgment calls in the gaps.
Responsible AI in clinical settings requires institutional capacity — not just compliance with a list.
The six gaps below are the places where checklists run out and judgment begins.
The Six Gaps the Consensus Leaves Open
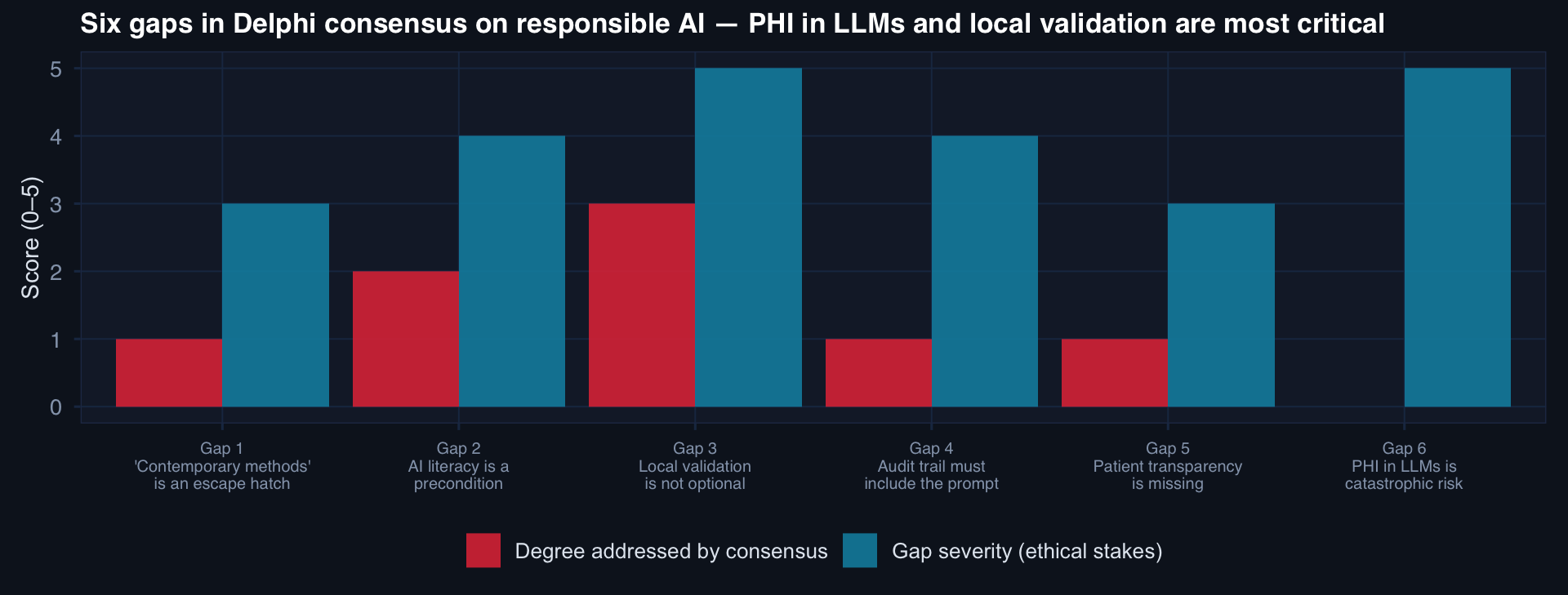
The two highest-severity, least-addressed gaps: local validation requirements and PHI in LLM workflows. Both are operationally critical for military trauma AI.
Gap 6: PHI in LLM Workflows Is Catastrophic Risk
The risk:
LLMs (GPT-4, Claude, Llama, Gemini) are increasingly used in clinical workflows for:
- Clinical note summarization
- CPG compliance checking from free text
- Differential diagnosis generation
- De-identification assistance
The PHI risk:
If a LLM is called via an API with patient data in the prompt — even with a BAA in place — the data may be:
- Retained for model training (depending on agreement)
- Stored in API logs accessible to the vendor
- Processed outside the covered entity’s data boundary
This is not a hypothetical. It is happening in clinical institutions now, without systematic governance.
The ethical requirement: Every LLM integration in a clinical workflow must have a documented, approved data governance policy specifying: what PHI categories may be included, what data remains within the organizational boundary, what retention applies, and who approved the exception.
Gap 2: AI Literacy as a Precondition
What AI literacy requires for clinicians:
- Understanding what a prediction interval means (and that it’s not a diagnosis)
- Knowing what the model was trained on — and whether the current patient matches that population
- Recognizing the failure modes: miscalibration, dataset shift, automation bias
- Understanding when to override — and having the authority to do so without friction
- Knowing how to report anomalies (the feedback loop)
What the consensus says:
“Clinicians should have appropriate literacy.” It does not specify what “appropriate” means, how it is assessed, or what happens when a clinician who lacks literacy uses the system.
The military context:
A trauma surgeon at a Role 3 facility using a model-assisted triage tool needs to know:
- What injury populations the model was validated on
- Whether the current theater differs from the training population
- What the model’s calibration looks like at the ISS range of the current patient
- How to override and document the override
This is not generic AI literacy. It is this model in this context. Deployment requires training — not just access.
Part 3
DoDTR Modernization as an Ethical Imperative
The status quo has a body count
What the Status Quo Actually Costs
The current DoDTR state:
- Manual abstraction: 30–90 day lag from care to data
- Local codes: inconsistent across echelons and theaters
- No continuous CPG compliance monitoring
- No automated performance monitoring of deployed models
- No shared semantic infrastructure for civilian-military data exchange
What this costs:
- Patterns of preventable injury or care deviation take months to detect — after many patients have been affected
- CPG updates based on pooled multi-site data rely on definitional consistency that doesn’t exist
- “Evidence-based” trauma care guidelines rest on data infrastructure that cannot support the analytical standards those guidelines require
The body count argument:
If tourniquet-to-amputation analysis requires 90-day data lag, and the analysis that would reveal a care deviation takes 6 months to conduct, then 8+ months of patients experience the deviation before a corrective protocol is issued.
This is not an abstract concern about data quality. It is a structural delay in the feedback loop between care delivery and care improvement — with casualties at every month of lag.
What Modernization Actually Requires
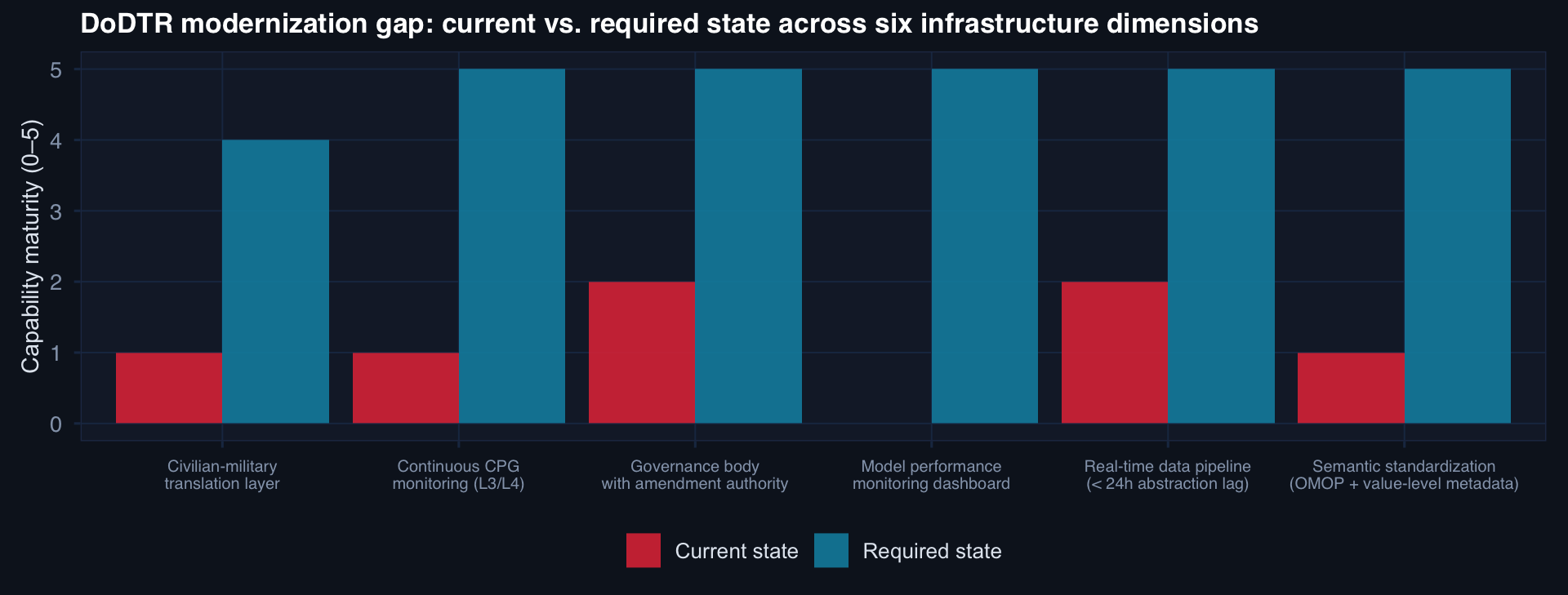
The largest gaps: model performance monitoring (zero current capability), CPG monitoring automation, and semantic standardization. These are not aspirational — they are prerequisites for defensible clinical AI in trauma.
The Five-Level Framework as Ethical Scaffolding
Why the framework matters ethically:
The five-level CPG compliance automation framework provides a progression from manual to autonomous processing — with governance requirements at each level.
This is ethical scaffolding: each level increase requires:
- Validation of the automated component before promotion
- Documented governance approval
- Retained human review for exception cases
- Audit trail requirements that scale with automation level
The ethical risk of skipping levels:
An institution that jumps from L0 (manual) to L4 (autonomous) without intermediate validation has produced an autonomous system with no validated foundation — and no institutional experience with the failure modes of each intermediate level.
The commander’s report as governance:
In the DoDTR modernization vision, the Commander’s Report is not a PDF delivered monthly. It is a live governance document:
- Real-time CPG compliance by unit and echelon
- Model performance alerts with investigation status
- Data quality metrics with trend lines
- Active protocol deviation cases with clinical lead assignment
The data infrastructure to produce this document is the same infrastructure that makes clinical AI in trauma defensible. They are not separate investments — they are the same investment.
Responsible Modernization: What It Requires Institutionally
The five institutional requirements for responsible DoDTR modernization:
- A governance body with authority — not an advisory committee; a named body that can approve, reject, and amend definitions and models
- A data dictionary with version control — every field, every value, every change, with effective dates and amendment rationale
- A validation protocol — pre-specified performance thresholds, subgroup requirements, temporal validation standards, and retirement criteria
- A monitoring infrastructure — real-time, not periodic; automated, not manual; with pre-specified alert thresholds and response protocols
- An AI literacy program — not generic; specific to the deployed models, the deployment context, and the clinical use cases at each echelon
None of these is a technology purchase. All five are organizational decisions that must be made before the first line of production code is written.
Series Summary — Ethics of Clinical AI
Lectures 1 & 2
- Interpretability ≠ justification; governance = defensibility
- Accountability lives with institutions, not models
- Bias starts upstream: selection, measurement, documentation, survivorship
- Risk scores predict — they don’t justify, decide, or bear responsibility
- HITL requires meaningful authority — not nominal authorization
- Excluding messy patients excludes the most critical population
Lecture 3
- Missingness is a fairness infrastructure problem, not a model problem
- Monitoring is ethically required — the deployment date is the start of validation
- Automation ethics: govern the speed, audit the lineage, test the pipeline
Lecture 4
- Local codes are an ethical failure of design, not a technical inconvenience
- Ontology governance is political — control the vocabulary, control the evidence
- Responsible AI requires six capabilities the checklist consensus leaves underspecified
- PHI in LLMs is catastrophic risk, not an edge case
- DoDTR modernization is an ethical imperative — the status quo has a body count
- Responsible modernization is an organizational decision before it is a technology decision
The series meta-lesson: Ethics in clinical AI is not a philosophical add-on — it is embedded in every decision about data collection, model training, deployment governance, and monitoring infrastructure. The work is upstream, front-loaded, and institutional.
![]()
Data InDeed · Ethics of Clinical AI · Lecture 4 | ⚡ Open App