# Beta-Binomial: estimating mortality rate with prior knowledge
# Prior: Beta(3, 17) = prior belief of ~15% mortality from previous theater
alpha_prior <- 3; beta_prior <- 17
# Observed: 14 deaths in 60 patients
deaths <- 14; total <- 60
alpha_post <- alpha_prior + deaths
beta_post <- beta_prior + (total - deaths)
x <- seq(0, 0.6, length.out=300)
bind_rows(
tibble(x=x, dens=dbeta(x, alpha_prior, beta_prior),
dist="Prior Beta(3,17)\n[~15% belief]"),
tibble(x=x, dens=dbeta(x, alpha_post, beta_post),
dist="Posterior Beta(17,63)\n[14/60 observed]")
) |>
ggplot(aes(x, dens, fill=dist, color=dist)) +
geom_area(alpha=0.35, position="identity") +
geom_line(linewidth=1.2) +
geom_vline(xintercept=alpha_post/(alpha_post+beta_post),
linetype=2, color="#f59e0b") +
scale_fill_manual(values=c("#2563eb","#e63946")) +
scale_color_manual(values=c("#2563eb","#e63946")) +
annotate("text", x=0.29, y=8, label=paste0("Posterior mean\n",
round(alpha_post/(alpha_post+beta_post)*100,1),"%"),
color="#f59e0b", size=3.5) +
labs(title="Bayesian update: prior belief + 14/60 data → posterior distribution over mortality rate",
x="Mortality rate θ", y="Density", fill=NULL, color=NULL) +
theme_di()Modeling Philosophy: Bayesian Thinking, Beyond p-Values & Hierarchical Models
Trauma Registry Analytics — Lecture 2 of 5
2026-01-01
Posterior Uncertainty vs. Point Estimates
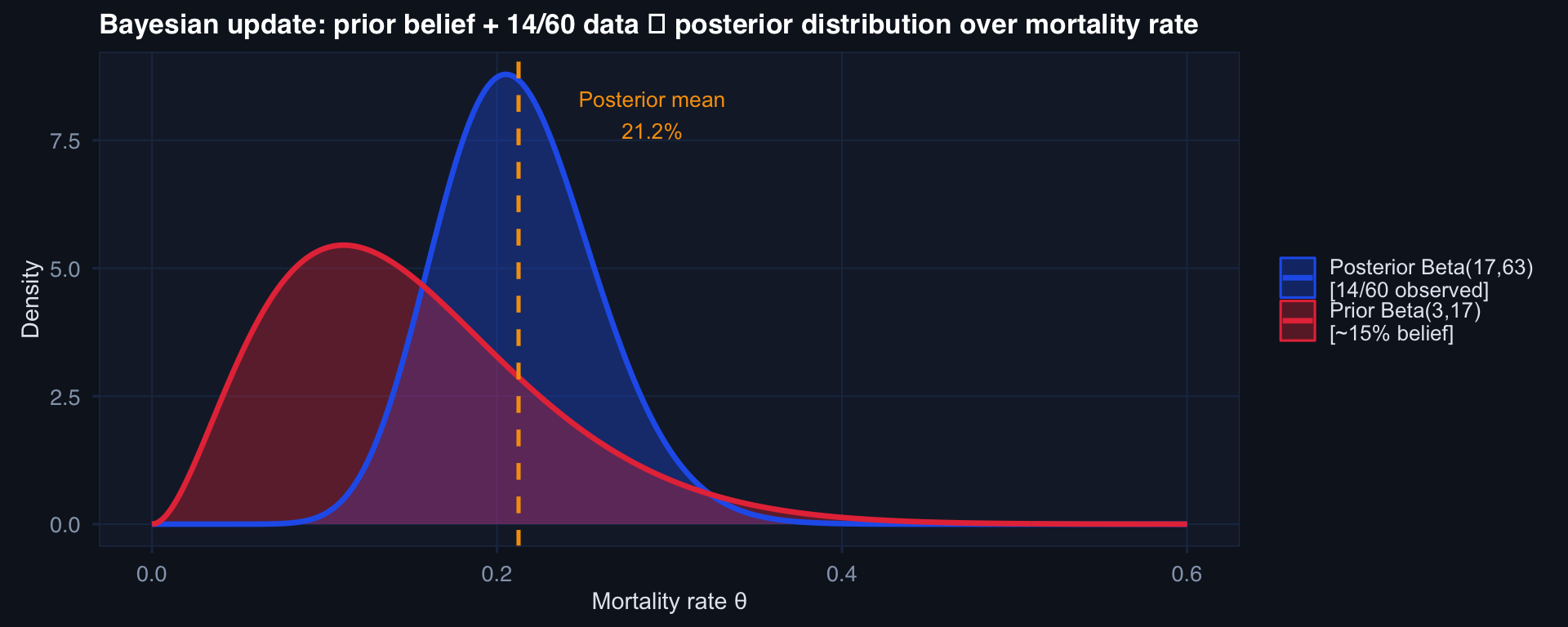
The posterior is a full distribution — not a point estimate. It quantifies uncertainty honestly. The 95% credible interval contains the true value with 95% probability (unlike a confidence interval, which doesn’t quite say that).
What p < 0.05 Actually Answers
p-value = P(data this extreme or more | H₀ is exactly true)
It does not answer:
- P(H₀ is true | data) — that’s Bayesian
- Whether the effect is clinically meaningful
- Whether the finding will replicate
- Whether you should change practice
# Same effect, different n → different p-value
set.seed(77)
effect <- 0.3 # small but real effect
results <- tibble(n = c(30, 100, 300, 1000, 5000)) |>
mutate(
p_val = sapply(n, function(n) {
x <- rnorm(n, effect, 1); y <- rnorm(n, 0, 1)
t.test(x, y)$p.value
}),
sig = p_val < 0.05
)
ggplot(results, aes(n, p_val, color=sig)) +
geom_hline(yintercept=0.05, linetype=2, color="#94a3b8") +
geom_point(size=5) +
geom_line(color="#64748b", linewidth=0.5) +
scale_color_manual(values=c("#e63946","#0891b2"),
labels=c("p ≥ 0.05","p < 0.05")) +
scale_x_log10() +
annotate("text", x=4000, y=0.08, label="α = 0.05", color="#94a3b8", size=3.5) +
labs(title="True effect d=0.3 becomes 'significant' only when n is large enough — the effect didn't change",
x="Sample size (log scale)", y="p-value", color=NULL) +
theme_di()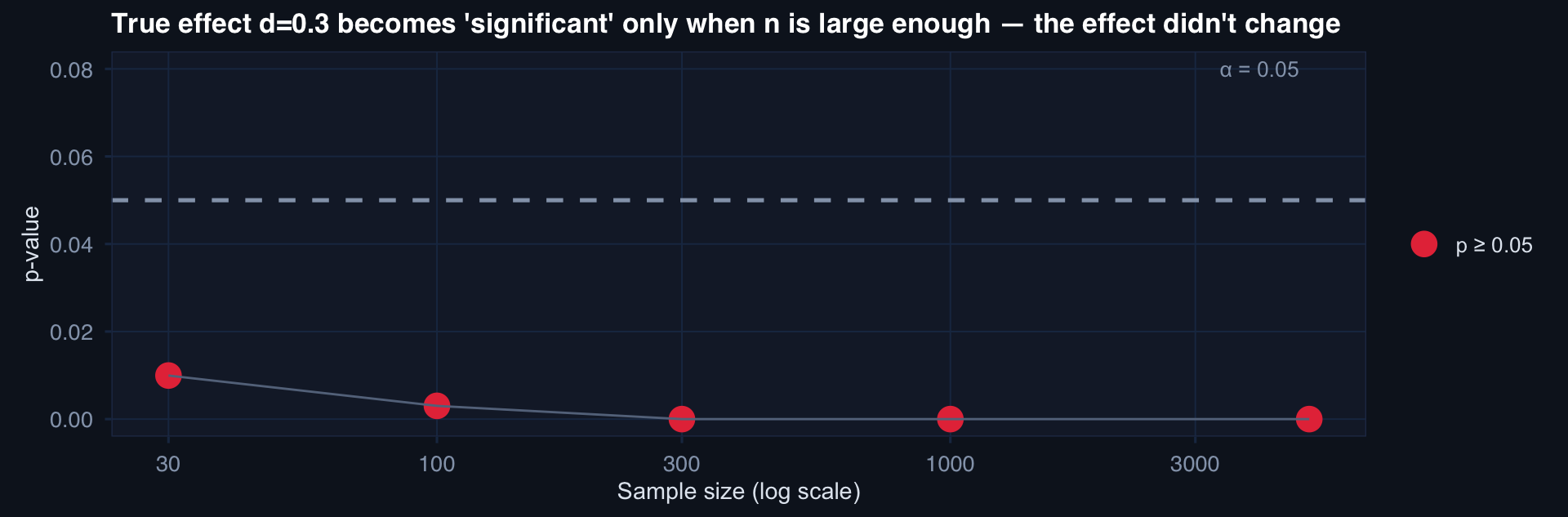
With n=5000, even a trivially small effect is “significant.” Sample size turns anything into a discovery.
The Silence of Flat Models
# Simulate clustered trauma data: patients within facilities
n_facilities <- 15; n_per <- 25
facility_effects <- rnorm(n_facilities, 0, 0.6)
df_hier <- expand_grid(
facility = 1:n_facilities,
patient = 1:n_per
) |> mutate(
u_fac = facility_effects[facility],
iss = rnorm(n(), 28, 10),
died = rbinom(n(), 1, plogis(-3 + 0.07*iss + u_fac))
)
# Mortality rate by facility
fac_rates <- df_hier |>
group_by(facility) |>
summarise(rate=mean(died), n=n(), mean_iss=mean(iss))
ggplot(fac_rates, aes(reorder(factor(facility), rate), rate)) +
geom_col(fill="#0891b2", alpha=0.8) +
geom_hline(yintercept=mean(fac_rates$rate), linetype=2, color="#e63946") +
labs(title="Mortality varies substantially across facilities — ignoring this inflates false positives",
x="Facility (sorted by mortality rate)", y="Observed mortality rate") +
theme_di() + theme(axis.text.x=element_blank())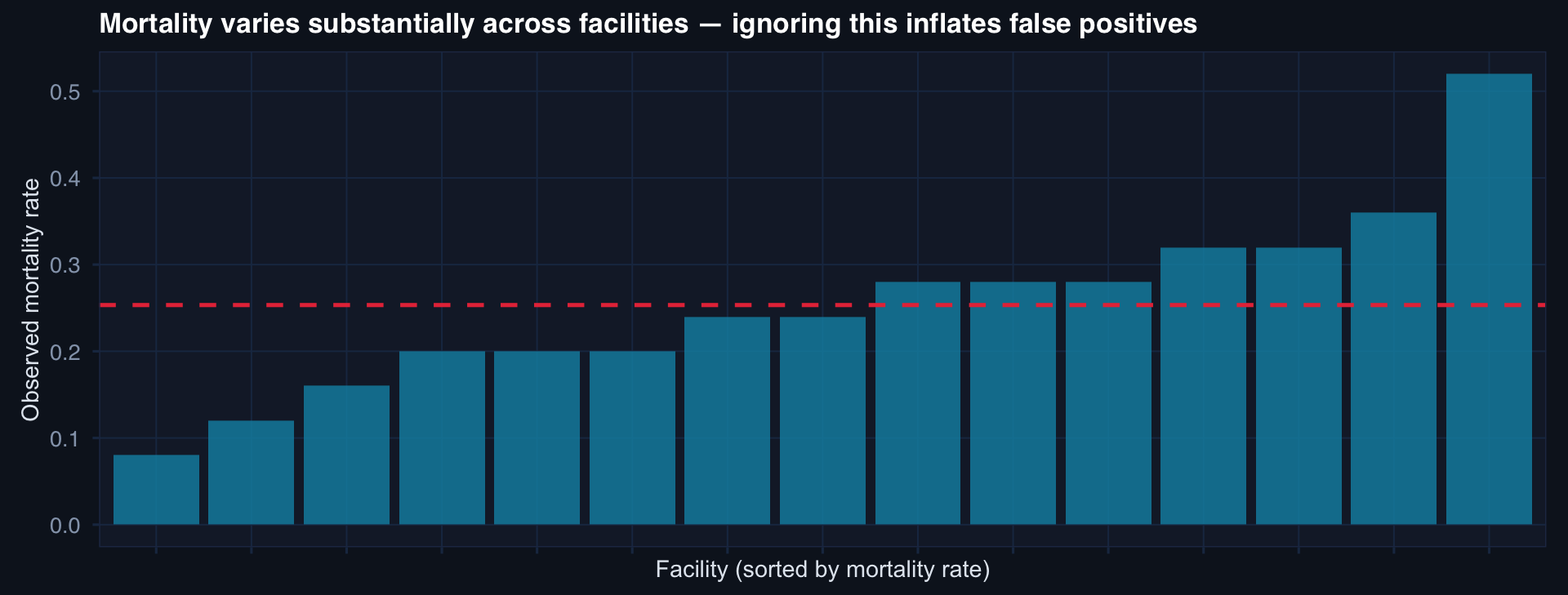
ICC = 0.10 here. This means 10% of outcome variance is explained by facility membership alone. Every patient-level model that ignores facility is pooling patients across structurally different care contexts — as if a Role 2 facility in a contested environment and a Role 4 stateside hospital were identical.
Partial Pooling: The Core Idea
# Compare: no pooling (raw rates) vs. partial pooling (shrinkage estimate)
fac_rates <- fac_rates |>
mutate(
grand_mean = mean(rate),
# Shrinkage toward grand mean based on n
shrinkage = n / (n + 10),
partial_pool = shrinkage * rate + (1 - shrinkage) * grand_mean
)
fac_rates |>
pivot_longer(c(rate, partial_pool)) |>
mutate(name=recode(name, rate="No pooling (raw)",
partial_pool="Partial pooling (shrinkage)")) |>
ggplot(aes(reorder(factor(facility), value), value, color=name, group=name)) +
geom_point(size=3) +
geom_line(alpha=0.5) +
geom_hline(yintercept=mean(fac_rates$rate), linetype=2, color="#94a3b8") +
scale_color_manual(values=c("#e63946","#0891b2")) +
labs(title="Partial pooling shrinks extreme estimates toward the grand mean — proportional to small n",
x="Facility", y="Mortality rate estimate", color=NULL) +
theme_di() + theme(axis.text.x=element_blank())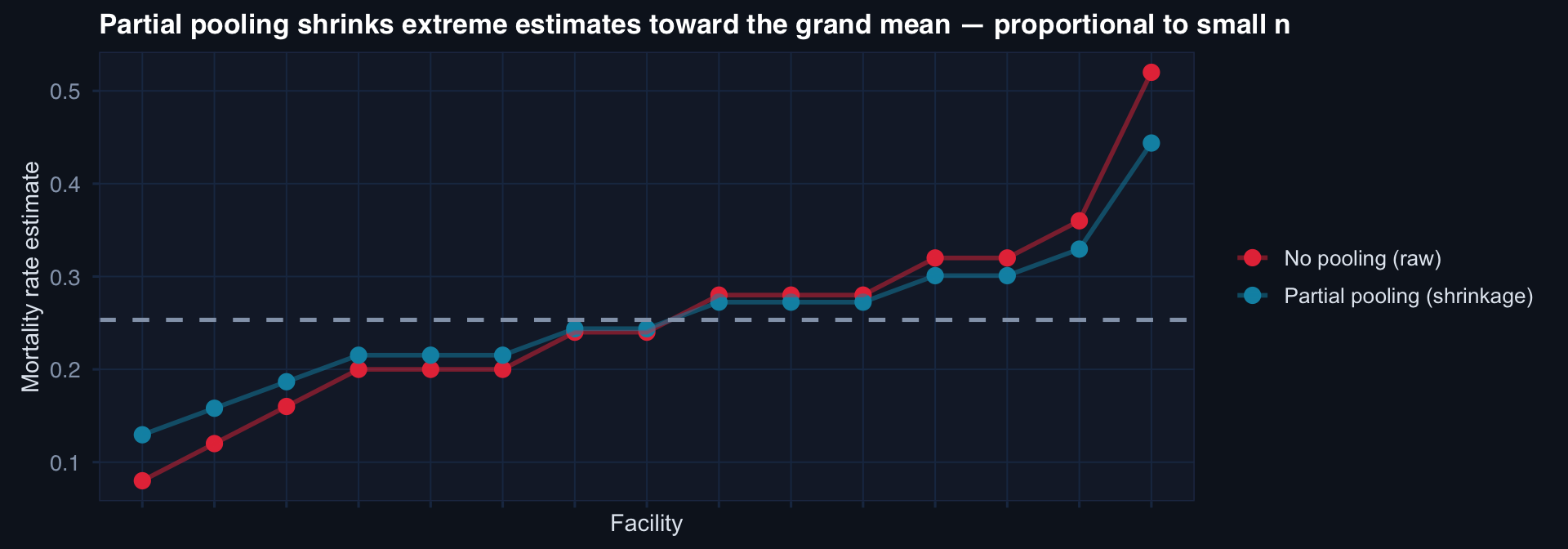
Small facilities get shrunk more — their estimates are less stable. Large facilities stay near their raw rate — their data is informative. This is automatically appropriate weighting, not ad hoc adjustment.