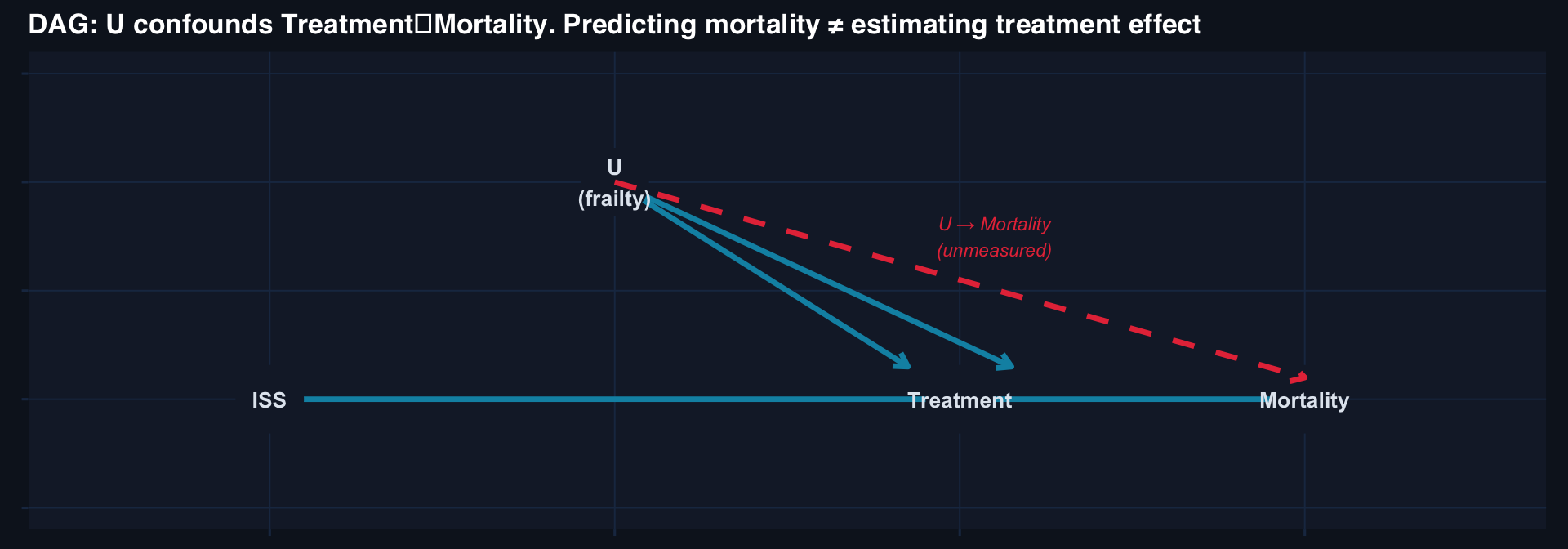
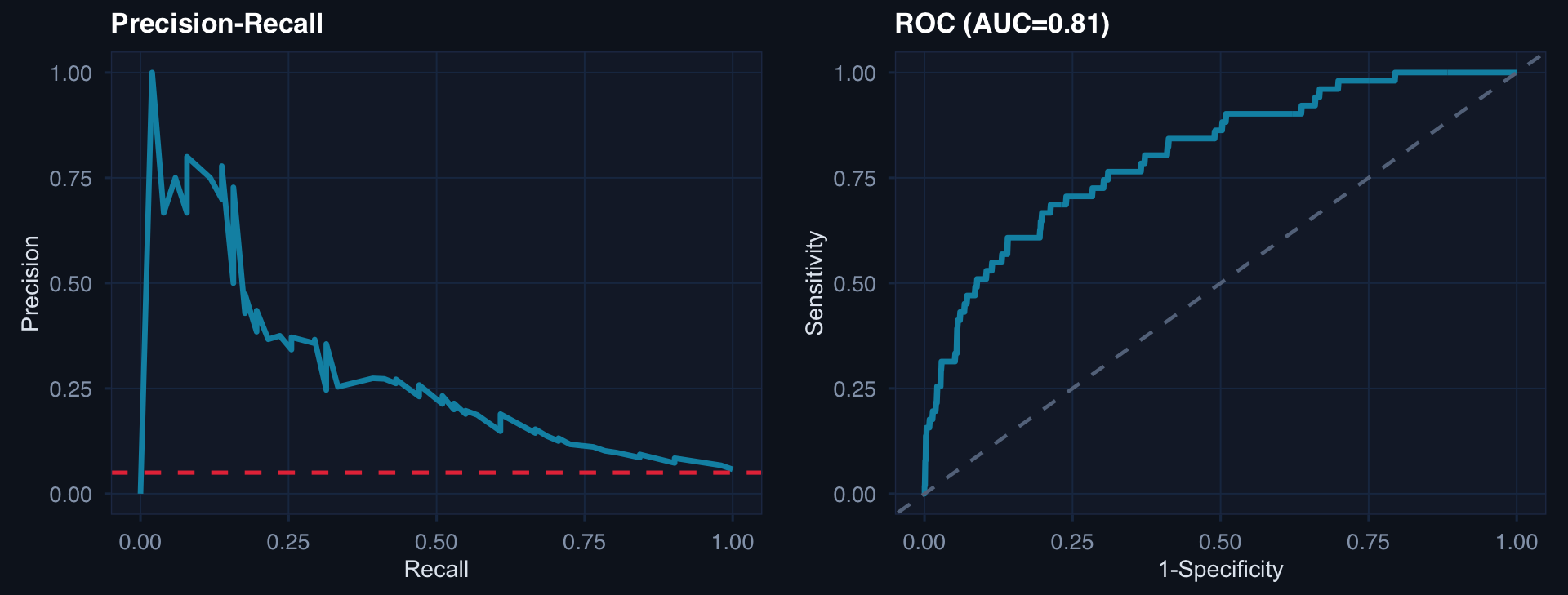
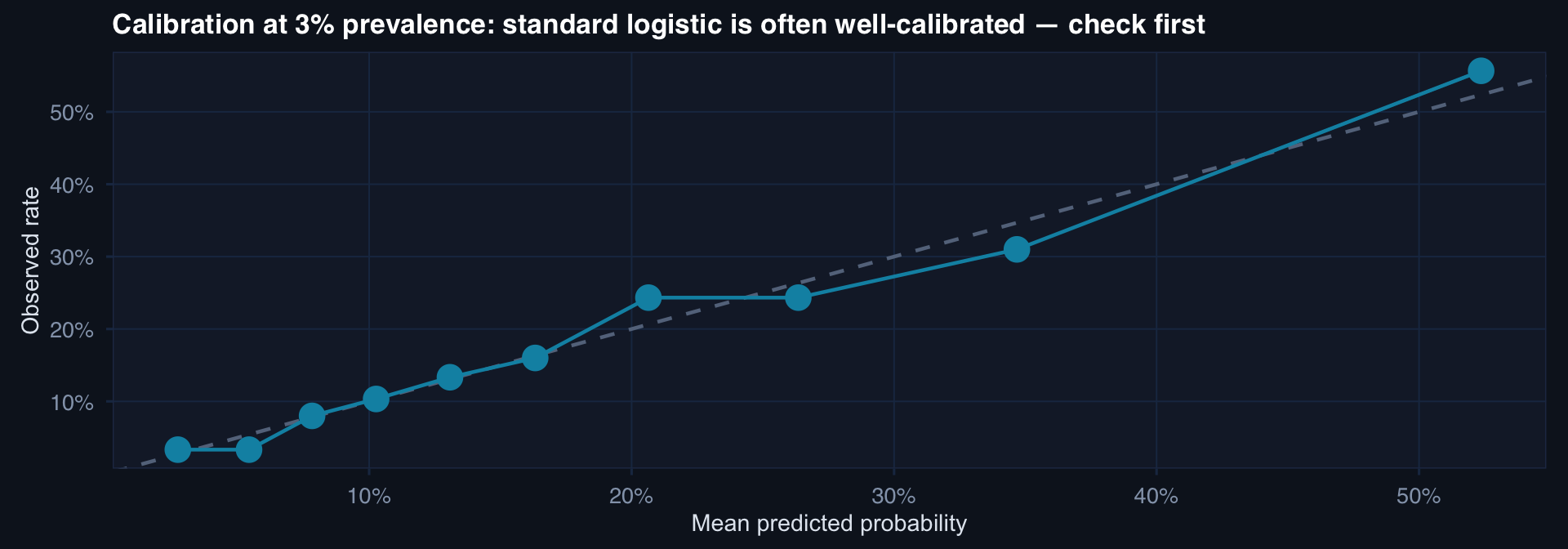
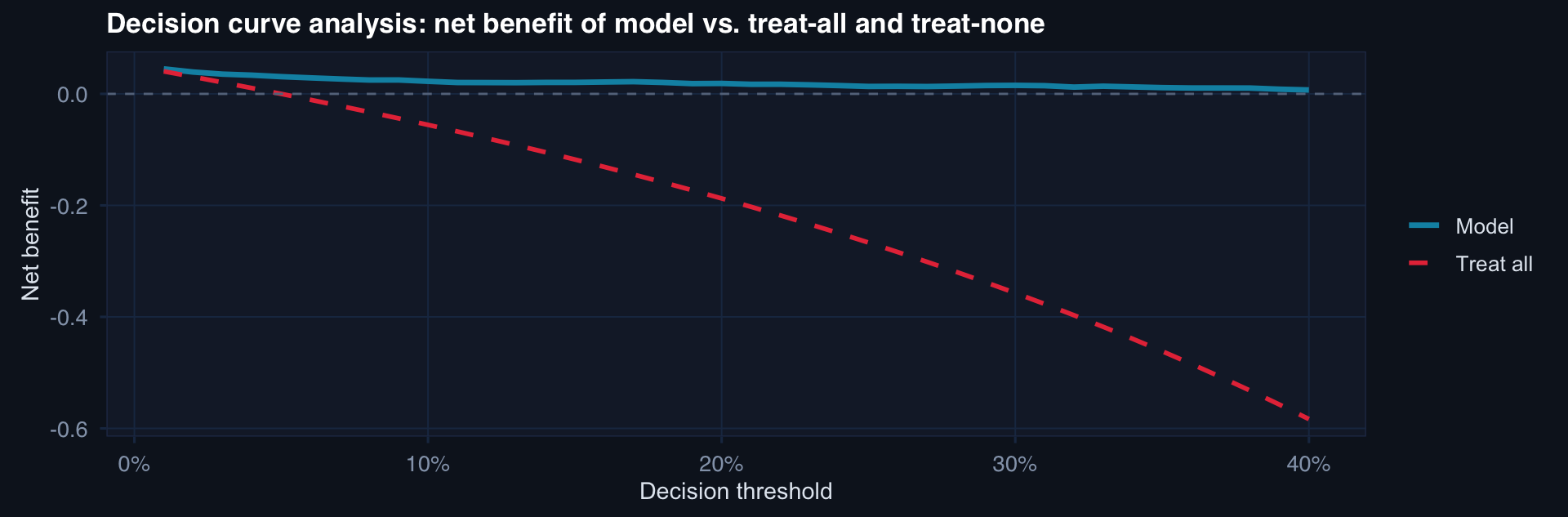
n <- 1000; prev <- 0.05
set.seed(55)
df_pr <- tibble(
truth = rbinom(n, 1, prev),
score = plogis(-3 + rnorm(n, 0, 1.5) + 2*truth)
)
# ROC curve
roc_obj <- roc(df_pr$truth, df_pr$score, quiet=TRUE)
# PR curve
thresholds <- seq(0.01, 0.99, by=0.01)
pr_df <- tibble(thresh=thresholds) |>
mutate(
pred = lapply(thresh, function(t) as.integer(df_pr$score > t)),
tp = sapply(pred, function(p) sum(p==1 & df_pr$truth==1)),
fp = sapply(pred, function(p) sum(p==1 & df_pr$truth==0)),
fn = sapply(pred, function(p) sum(p==0 & df_pr$truth==1)),
prec = tp/(tp+fp+1e-9),
rec = tp/(tp+fn+1e-9)
)
p1 <- ggplot(pr_df, aes(rec, prec)) +
geom_line(color="#0891b2", linewidth=1.2) +
geom_hline(yintercept=prev, linetype=2, color="#e63946") +
labs(title="Precision-Recall", x="Recall", y="Precision") + theme_di()
p2 <- tibble(fpr=1-roc_obj$specificities, tpr=roc_obj$sensitivities) |>
ggplot(aes(fpr, tpr)) +
geom_line(color="#0891b2", linewidth=1.2) +
geom_abline(linetype=2, color="#64748b") +
labs(title=paste0("ROC (AUC=", round(auc(roc_obj),2),")"),
x="1-Specificity", y="Sensitivity") + theme_di()
cowplot::plot_grid(p1, p2, ncol=2)