How Probability Powers Everyday AI: From Spam Filters to Self-Driving Cars
Applied Statistics
Probability
An applied introduction to probability, contingency tables, Bayes’ theorem, and Monte Carlo simulation for AI and clinical decision-making.
Published
March 15, 2023
Modified
June 9, 2026
Executive Summary
Probability is often taught as a mathematical foundation, but in practice it is also the language of uncertainty in artificial intelligence and machine learning.
This matters in trauma care too.
A trauma team never sees the whole truth at once. Prehospital vitals may be incomplete. Mechanism may be wrong. Hemorrhage may be occult. Laboratory data may lag physiology. Decisions still have to be made.
That is why probability matters: it provides a disciplined way to reason under incomplete information (Kolmogorov 1956; Pearl 1988).
This post introduces:
Kolmogorov’s axioms
joint, marginal, and conditional probability
Bayes’ theorem
contingency tables as probability matrices
Monte Carlo simulation
AI does not eliminate uncertainty. It formalizes decisions under uncertainty.
Probability Is the Grammar of Uncertainty
In deterministic systems, inputs map cleanly to outputs. In real-world systems, they rarely do.
Data is noisy. Measurements are incomplete. Labels may be uncertain. Signals may conflict.
Probability gives us a framework for answering questions like:
For trauma clinicians, probability is not abstract.
Marginal probability is the overall mortality in a cohort.
Conditional probability is mortality given shock, penetrating injury, or critical transfusion.
Joint probability is the probability that two clinical features occur together.
Bayesian updating is what happens when suspicion changes after new evidence arrives.
Monte Carlo simulation is what we do when repeated scenarios help estimate operational uncertainty.
In other words, probability is one way to formalize what clinicians already do cognitively: update belief as evidence accumulates.
Kolmogorov’s Axioms Define the Rules
All of probability theory begins with three foundational axioms (Kolmogorov 1956).
Let \(A\) be an event in a sample space \(S\).
Axiom 1: Non-negativity
\[
P(A) \geq 0
\]
Axiom 2: Normalization
\[
P(S) = 1
\]
Axiom 3: Additivity
For mutually exclusive events \(A\) and \(B\),
\[
P(A \cup B) = P(A) + P(B)
\]
These rules prevent contradiction. A model that assigns incoherent probabilities is not merely poorly calibrated. It is mathematically invalid.
Why These Axioms Matter in AI/ML
Probability axioms underpin practical modeling tasks such as:
probabilistic classification,
uncertainty quantification,
Bayesian updating,
ensemble prediction,
anomaly detection,
and sensor fusion.
If a classifier outputs probabilities that do not cohere, downstream decisions can become misleading or unsafe.
A Simple Toy Example
We will begin with a small email spam example because it is easy to understand and compute. Here, contains_free indicates whether an email contains the word "free" (Yes/No), and spam indicates whether the email is spam (Yes/No).
# A tibble: 20 × 3
email_id contains_free spam
<int> <chr> <chr>
1 1 Yes Yes
2 2 Yes Yes
3 3 Yes Yes
4 4 Yes No
5 5 Yes Yes
6 6 No No
7 7 No No
8 8 No Yes
9 9 No No
10 10 No No
11 11 Yes Yes
12 12 Yes No
13 13 No No
14 14 No No
15 15 Yes Yes
16 16 No No
17 17 Yes Yes
18 18 No No
19 19 Yes Yes
20 20 No No
Cross Tabulation as a Probability Engine
A two-way contingency table is one of the simplest and most useful probability objects in applied statistics.
It stores the frequency of every combination of two categorical variables. From that single table, we can obtain:
joint probabilities,
marginal probabilities,
conditional probabilities,
and tests of whether the two variables appear statistically independent.
This is why contingency tables are so foundational in AI, epidemiology, operations research, and clinical data science.
CrossTable of a Simple 2x2
The gmodels::CrossTable() function prints the table in a SAS PROC FREQ-like format and can optionally report inferential tests and diagnostic summaries.
conditional probabilities are row-normalized or column-normalized versions of the matrix.
If rows represent categories of \(X\) and columns represent categories of \(Y\), then:
\[
P(X = x_i) = \sum_j p_{ij}
\]
and
\[
P(Y = y_j) = \sum_i p_{ij}
\]
Then conditional probabilities are obtained by dividing each row or column by its corresponding marginal total.
Conceptually, this is exactly what CrossTable() is helping us visualize.
This connection matters because it scales naturally. A simple 2×2 table is easy to draw, but the same mathematical logic extends to:
a 3×4 table,
a multiway contingency array,
or a joint distribution across 6 variables.
Once more variables are introduced, the object is no longer just a matrix. It becomes a higher-dimensional array or tensor. But the same ideas remain:
joint distributions store all combinations,
marginals collapse across dimensions,
conditionals normalize along selected dimensions.
That is one reason probability is so central to modern AI and ML. The mathematical ideas scale from a toy spam filter to much more complex multivariable systems.
Why the CrossTable() Tests Are Useful
Descriptive probabilities tell us what the data look like. Statistical tests help us assess whether the observed association is larger than we would expect from random variation alone.
Chi-Square Test
The chi-square test evaluates whether two categorical variables are statistically independent.
In this example, the null hypothesis is that:
whether an email contains the word "free" is independent of whether it is spam.
If the test is statistically significant, that suggests the variables are associated.
This is usually the default large-sample test for contingency tables.
Fisher’s Exact Test
Fisher’s exact test is also a test of independence, but it is especially useful when sample sizes are small or expected cell counts are sparse.
For small 2×2 tables, Fisher’s test is often more appropriate than the chi-square approximation.
McNemar’s Test
McNemar’s test is different. It is designed for paired 2×2 data, not for ordinary independent observations.
For example, it would be useful if the same emails were classified by two different algorithms, or before and after relabeling. It is generally not the right default for a standard cross-sectional spam table.
Cell Chi-Square Contributions and Residuals
The overall chi-square test may tell us that an association exists, but it does not tell us which cells are driving that association.
That is where these diagnostics help:
prop.chisq = TRUE shows how much each cell contributes to the overall chi-square statistic
These are useful because they identify where observed counts differ most from what we would expect under independence.
For example, if the "Contains Free = Yes" and "Spam = Yes" cell has a large positive residual, that suggests more such emails occur than expected if the variables were unrelated.
A More Inferential Version
If you want to teach or demonstrate both description and inference together, this version is useful:
Cell Contents
|-------------------------|
| N |
| Chi-square contribution |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 20
| Spam
Contains 'Free' | No | Yes | Row Total |
----------------|-----------|-----------|-----------|
No | 9 | 1 | 10 |
| 2.227 | 2.722 | |
| 0.900 | 0.100 | 0.500 |
| 0.818 | 0.111 | |
| 0.450 | 0.050 | |
----------------|-----------|-----------|-----------|
Yes | 2 | 8 | 10 |
| 2.227 | 2.722 | |
| 0.200 | 0.800 | 0.500 |
| 0.182 | 0.889 | |
| 0.100 | 0.400 | |
----------------|-----------|-----------|-----------|
Column Total | 11 | 9 | 20 |
| 0.550 | 0.450 | |
----------------|-----------|-----------|-----------|
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 9.89899 d.f. = 1 p = 0.001653695
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 7.272727 d.f. = 1 p = 0.007000942
Fisher's Exact Test for Count Data
------------------------------------------------------------
Sample estimate odds ratio: 27.32632
Alternative hypothesis: true odds ratio is not equal to 1
p = 0.005477495
95% confidence interval: 2.057999 1740.082
Alternative hypothesis: true odds ratio is less than 1
p = 0.9999405
95% confidence interval: 0 864.8687
Alternative hypothesis: true odds ratio is greater than 1
p = 0.002738747
95% confidence interval: 2.732944 Inf
Trauma Parallel
The same logic applies to trauma prediction.
Replace "contains_free" with prehospital hypotension and replace "spam" with early critical transfusion or in-hospital mortality.
Then the question becomes:
What is the probability of a poor outcome, given the evidence currently available?
That is the core logic behind risk models, triage tools, and decision-support systems.
And once more than two variables are involved, the same logic extends to richer joint distributions:
hypotension,
mechanism,
injury severity,
blood product use,
destination role of care,
and mortality.
That is already a six-variable probability problem. In practice, modern models estimate or approximate these high-dimensional relationships rather than print a literal six-way table, but the conceptual foundation is the same.
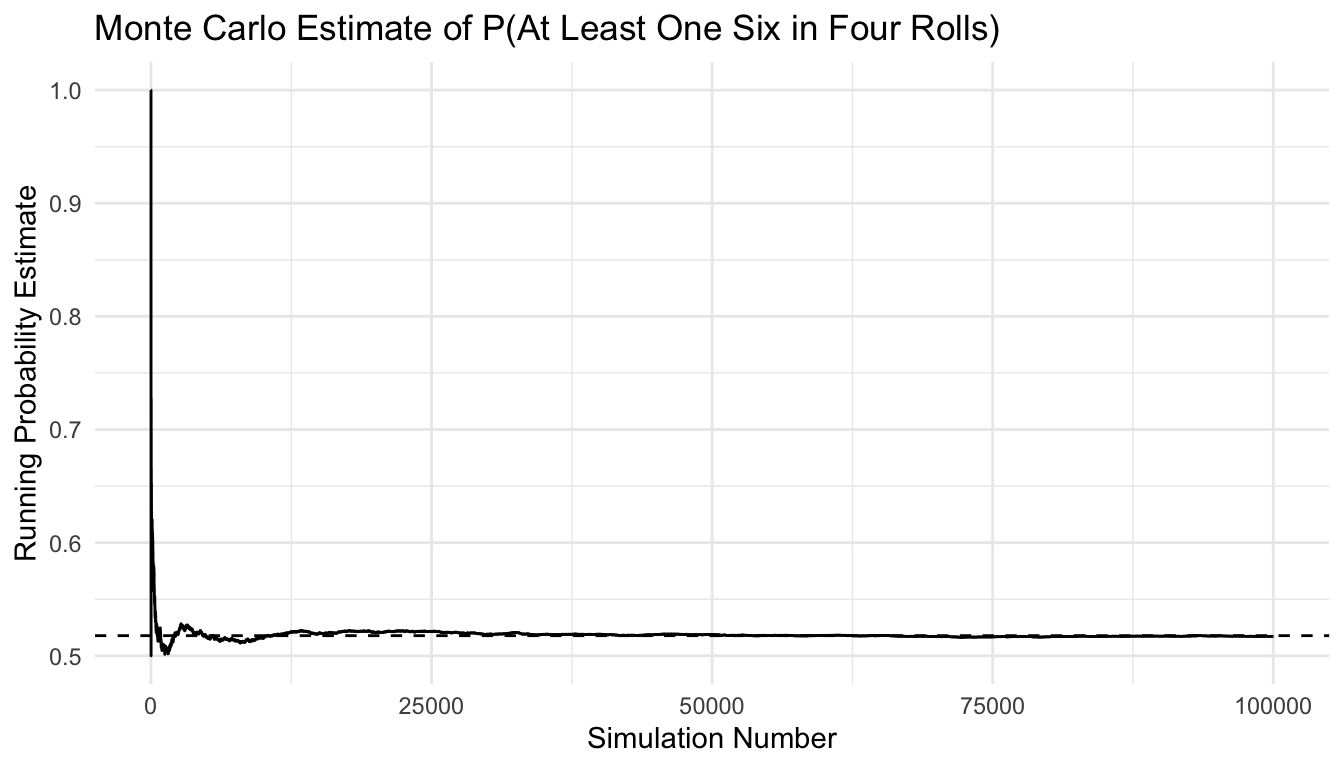
# A tibble: 2 × 2
method probability
<chr> <dbl>
1 Exact 0.518
2 Monte Carlo 0.517
ggplot2::ggplot(sim_df, ggplot2::aes(x = sim, y = running_est)) + ggplot2::geom_line(linewidth =0.5) + ggplot2::geom_hline(yintercept = p_exact, linetype =2) + ggplot2::labs(title ="Monte Carlo Estimate of P(At Least One Six in Four Rolls)",x ="Simulation Number",y ="Running Probability Estimate" ) + ggplot2::theme_minimal()
Why This Matters Operationally
Monte Carlo thinking is useful far beyond classroom probability.
It helps analysts explain:
uncertainty in outcomes,
variability across repeated scenarios,
sensitivity to assumptions,
and why point estimates can hide operational risk.
That is useful in trauma systems, clinical forecasting, and AI-enabled decision support.
Common Mistakes
Common probability mistakes include:
confusing marginal risk with conditional risk,
ignoring base rates,
overinterpreting rare predictions,
and treating model outputs as certainty rather than uncertainty.
These are not just statistical mistakes. They are decision-making mistakes.
NoteWhere This Shows Up in AI/ML
Epic’s sepsis prediction model (Sepsis Watch) outputs a probability score derived from Bayesian updating over sequential vital signs and lab values — the score only makes sense if clinicians understand that it reflects a posterior probability conditioned on the patient’s current trajectory, not a binary alarm. When base rates are ignored — as when the model is deployed in a low-acuity ward where sepsis prevalence is 2% rather than the 20% seen in the ICU training population — the positive predictive value collapses, generating relentless false alarms that erode clinician trust and lead to alert fatigue, the documented failure mode behind several high-profile AI withdrawal decisions in military treatment facilities.
Closing
Probability is central in machine learning. It is the conceptual infrastructure for reasoning under uncertainty (Cover and Thomas 2006; Wasserman 2004).
For clinicians, analysts, and modelers, the core lesson is the same:
Good AI does not remove uncertainty. It represents uncertainty honestly and uses it well.
Series Callout
Note
This post is part of a broader Applied Statistics for AI and Clinical Decision-Making Series: