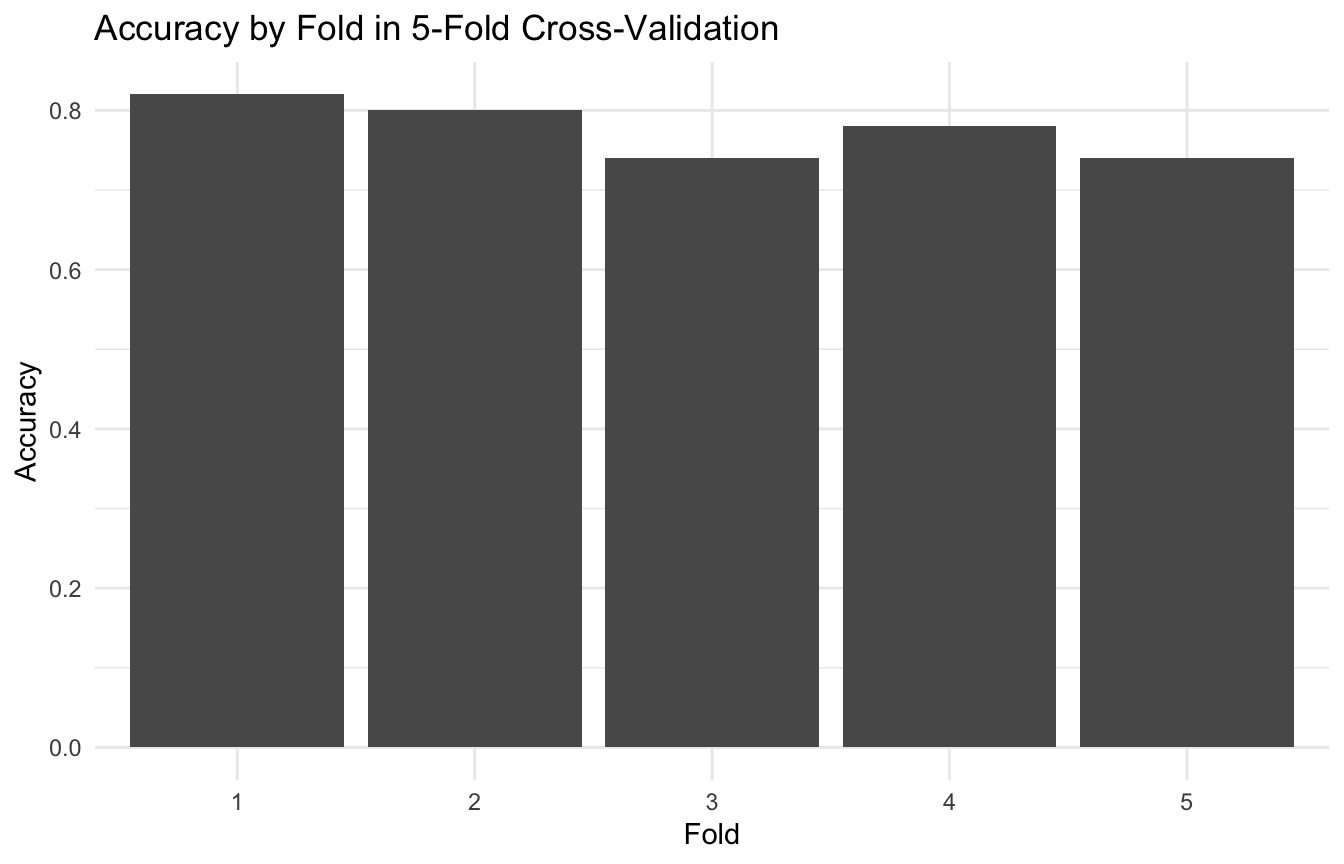
Cross-validation provides a practical way to estimate how well a model is likely to perform on new, unseen data. It does this by repeatedly splitting the data into training and validation subsets, fitting the model on one portion, and evaluating it on another.
This matters in both statistics and machine learning.
In classical modeling, cross-validation helps assess predictive performance. In AI/ML, it is one of the main tools for:
hyperparameter tuning,
model comparison,
generalization error estimation,
and guarding against overfitting.
This post introduces:
why resampling-based validation matters,
K-fold cross-validation,
leave-one-out cross-validation,
stratified sampling,
and practical implementation with R and a scikit-learn style comparison.
Cross-validation matters because good in-sample performance proves very little if the model collapses the moment it sees new data.
Cross-Validation Exists Because Training Error Is Not Enough
A model is usually optimized to fit the training data.
That means training performance is almost always biased upward as an estimate of future performance.
The more flexible the model, the more misleading training error can become.
This is why analysts distinguish between:
in-sample fit
and out-of-sample generalization
Cross-validation is one of the standard tools for estimating the second quantity.
It asks a more honest question:
how well does this model perform on data that were not used to fit it?
That is the central validation question in predictive analytics.
Generalization Error Is the Real Target
The quantity we really care about in predictive modeling is often the generalization error.
This is the expected error the model would make on future observations drawn from the same underlying process.
We cannot observe generalization error directly because we do not have access to all future data.
So we estimate it.
Cross-validation provides one practical way to do that by repeatedly holding out subsets of the observed data and treating them as pseudo-future samples.
That is why cross-validation is so central in modern model assessment.
It is not just a technical convenience. It is a way of approximating the real deployment question.
A Simple Train/Test Split Is Useful, but Limited
A basic train/test split is often the first validation strategy analysts learn.
It is simple:
fit the model on the training set
evaluate it on the test set
That is often much better than reporting training performance alone.
But it has limitations.
A single split can be unstable because results depend on exactly which observations happened to land in train versus test.
That is especially problematic when:
the dataset is small
class balance matters
or the outcome is noisy
Cross-validation improves on this by repeating the train/validation process across multiple splits.
K-Fold Cross-Validation Is the Standard Workhorse
The most common version of cross-validation is K-fold cross-validation.
The data are divided into (K) roughly equal parts, or folds.
Then the model is fit (K) times:
each time using (K-1) folds for training
and the remaining fold for validation
The validation performance is averaged across all folds.
This produces a more stable estimate than a single train/test split because every observation gets a turn in the validation set.
Typical choices include:
5-fold CV
10-fold CV
These are popular because they often strike a reasonable balance between computation and stability.
A Small Example Makes the Workflow Concrete
To illustrate, we will simulate a binary classification problem with a few predictors.
# A tibble: 2 × 3
model mean_accuracy sd_accuracy
<chr> <dbl> <dbl>
1 Full 0.772 0.0335
2 Simple 0.772 0.0576
This is a simple example of how cross-validation supports model selection.
Cross-Validation Should Be Nested When Tuning and Evaluating
Once hyperparameters are tuned inside the same resampling loop used for performance estimation, optimism can leak back into the reported results. Nested resampling helps separate model selection from final evaluation (Hastie et al. 2009; James et al. 2021).
One common mistake is to use the same cross-validation procedure both to choose hyperparameters and to report final performance as if that were unbiased.
That can still produce overly optimistic estimates.
When hyperparameters are tuned, truly honest performance assessment often requires nested cross-validation or an external test set.
The logic is simple:
inner resampling chooses the model settings
outer resampling evaluates the tuned workflow
This distinction is important because model selection itself can overfit the resampling process.
That is one of the more subtle ways analysts fool themselves.
Cross-Validation Is Powerful, but It Is Not Magic
Cross-validation is extremely useful, but it does not fix everything.
It cannot rescue:
data leakage
poor outcome definition
nonrepresentative sampling
temporal leakage in time series
clustering dependence ignored in grouped data
or causal confounding
For example, in time series settings, ordinary random CV can be inappropriate because it breaks temporal structure.
In grouped data, subjects from the same cluster may leak information across folds.
This is why cross-validation must match the structure of the data-generating problem.
Scikit-Learn Style Thinking Maps Directly to the Same Principles
Although this post uses R, the same logic carries directly into Python and scikit-learn.
In scikit-learn, common tools include:
KFold
StratifiedKFold
cross_val_score
GridSearchCV
Pipeline
Conceptually, these do the same things:
split the data
fit models repeatedly
evaluate out-of-sample
and average results
So the statistical principle does not depend on the software language. What changes is only the implementation style.
Cross-Validation Is One of the Main Defenses Against Overfitting
In modern AI/ML, overfitting is often not obvious by inspection alone.
A highly flexible model may look impressive on the training set while performing poorly in deployment.
Cross-validation helps defend against that by forcing the model to prove itself repeatedly on held-out data.
This is why CV remains such a standard tool.
It does not guarantee that the model will succeed in the wild, but it is one of the best practical checks available before deployment.
A Practical Checklist for Applied Work
Before reporting cross-validated performance, ask:
Is the resampling strategy appropriate for the data structure?
Is stratification needed for class imbalance?
Is there any leakage across folds?
Am I tuning hyperparameters and evaluating honestly?
Would nested CV or a final test set be more appropriate?
Am I reporting only the mean, or also the variability across folds?
Would a simpler baseline perform just as well?
These questions usually improve both rigor and credibility.
NoteWhere This Shows Up in AI/ML
Temporal cross-validation — where training folds always precede validation folds in calendar time — is the required standard for clinical AI models trained on longitudinal EHR data, because random k-fold splitting allows the model to train on future data and inflate AUC by 5–15 percentage points in sepsis and deterioration prediction tasks. The Joint Pathology Center’s DoDTR-based mortality models have historically been evaluated using random splits across deployment sites, which masks the performance drop when a model trained on peacetime MTF caseloads is applied to combat casualty data with a different injury profile and care-interval distribution. When CV results from a single institution are presented as evidence of generalizability, the model has passed an exam it wrote for itself — and the failure shows up operationally, not in the development notebook.
Cross-validation remains one of the most important tools in modern predictive analytics because it forces a simple but essential discipline:
do not judge a model only by how well it explains the data it already saw.
K-fold CV provides a practical and stable way to estimate generalization error (Arlot and Celisse 2010). LOOCV shows the full resampling idea in its most exhaustive form. Stratified cross-validation improves classification assessment when class balance matters. And nested approaches help keep tuning from contaminating evaluation.
Cross-validation matters because predictive performance is only meaningful if it survives contact with data the model did not get to memorize.
This post is part of the Prediction Modeling Toolkit — a companion reference with K-fold cross-validation scaffolds, stratified splitting templates, nested CV code, and hyperparameter tuning workflows.
Arlot, Sylvain, and Alain Celisse. 2010. “A Survey of Cross-Validation Procedures for Model Selection.”Statistics Surveys 4: 40–79.
Harrell, Jr., Frank E. 2015. Regression Modeling Strategies. 2nd ed. Springer.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. Springer.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer.
Steyerberg, Ewout W. 2019. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. 2nd ed. Springer.
Stone, Mervyn. 1974. “Cross-Validatory Choice and Assessment of Statistical Predictions.”Journal of the Royal Statistical Society: Series B 36 (2): 111–47.