n <- 400
df_full <- tibble(
severity = rnorm(n, 30, 12), # ISS proxy
outcome = 5 + 0.4 * severity + rnorm(n, 0, 5)
)
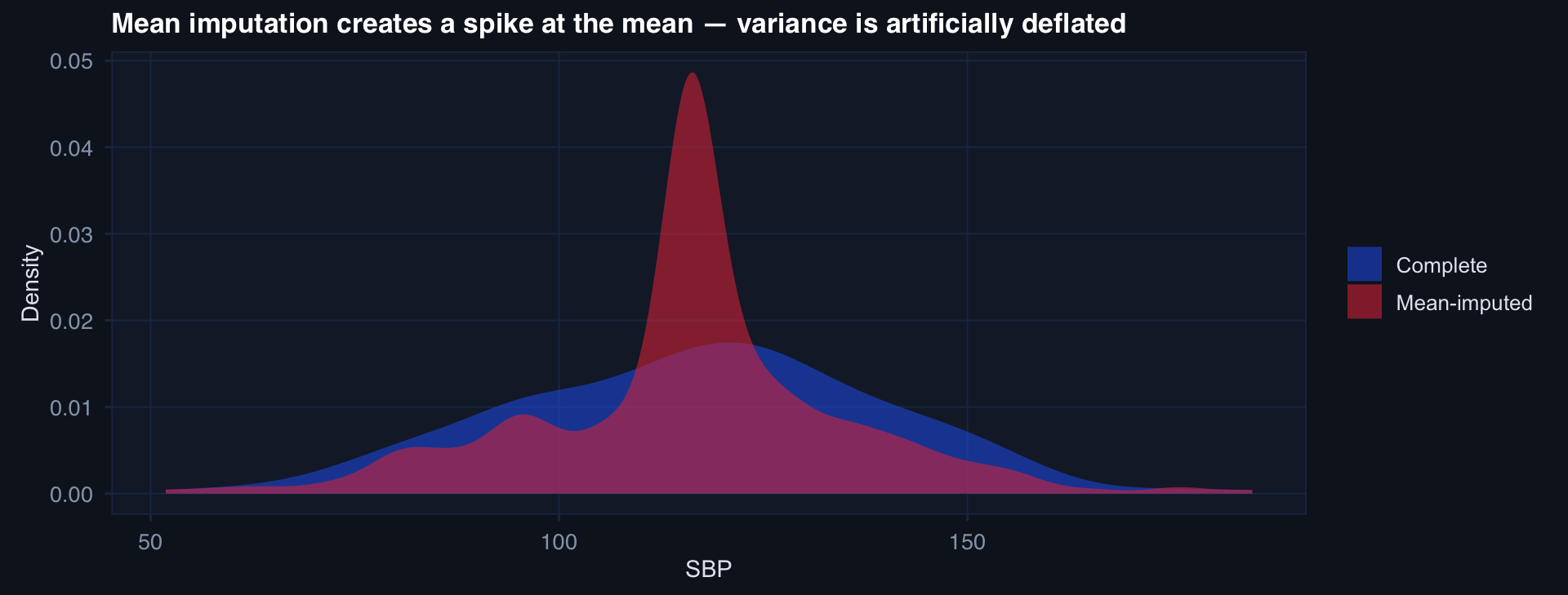
df_mcar <- df_full |> mutate(obs = ifelse(runif(n) > 0.3, outcome, NA))
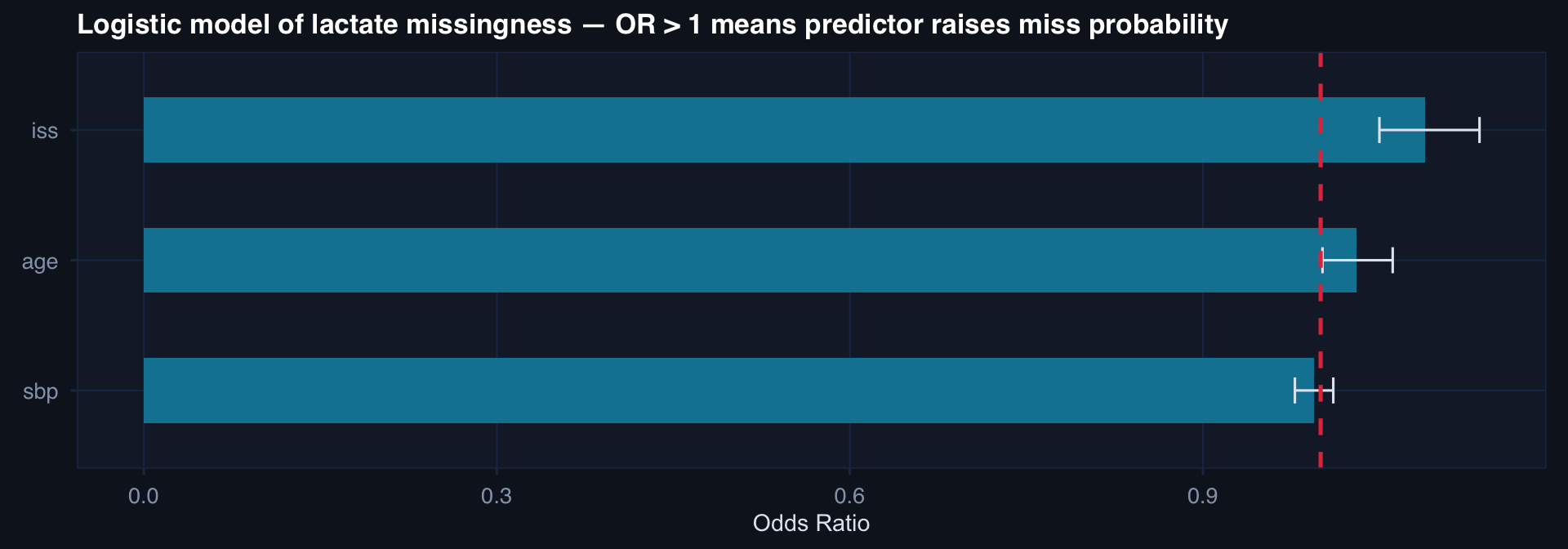
df_mar <- df_full |> mutate(obs = ifelse(severity < 35 | runif(n) > 0.5, outcome, NA))
df_mnar <- df_full |> mutate(obs = ifelse(outcome < 20 | runif(n) > 0.4, outcome, NA))
# True mean
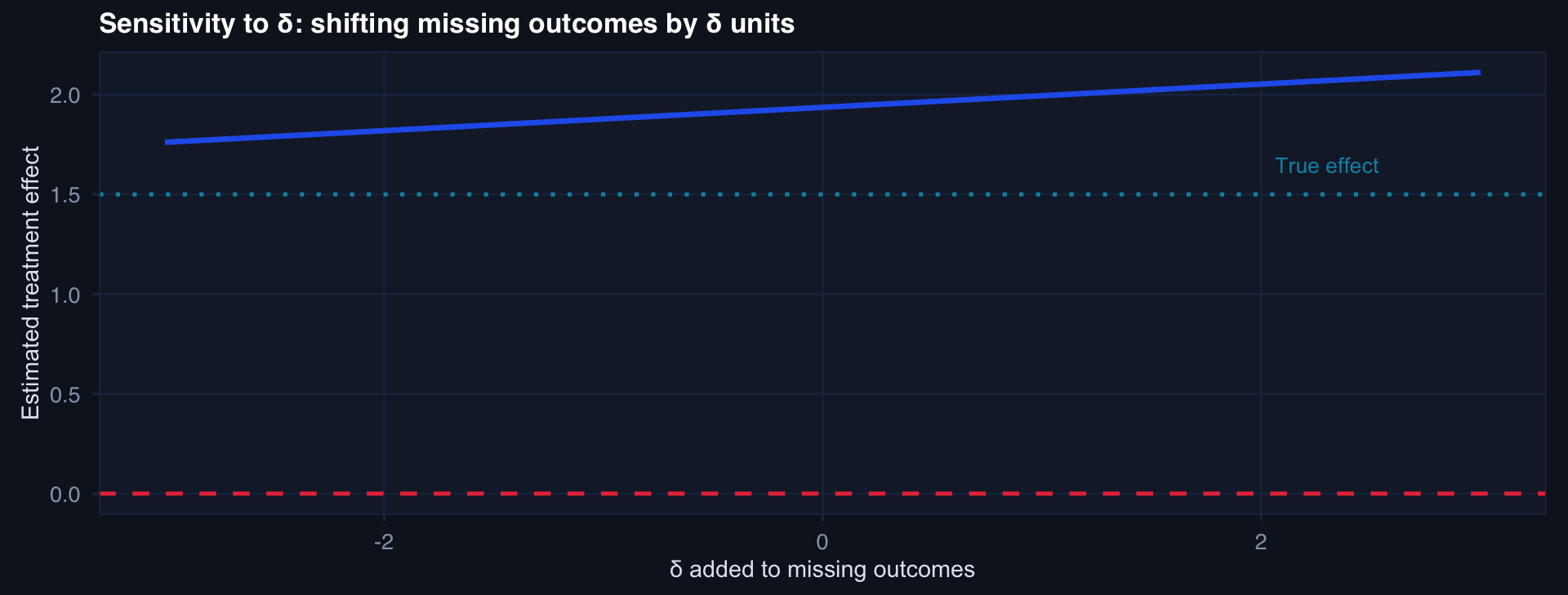
true_mean <- mean(df_full$outcome)
tibble(
Mechanism = c("MCAR", "MAR", "MNAR"),
`Observed mean` = c(mean(df_mcar$obs, na.rm=TRUE),
mean(df_mar$obs, na.rm=TRUE),
mean(df_mnar$obs, na.rm=TRUE)),
`True mean` = true_mean,
`% missing` = c(mean(is.na(df_mcar$obs)),
mean(is.na(df_mar$obs)),
mean(is.na(df_mnar$obs))) * 100
) |>
mutate(Bias = round(`Observed mean` - `True mean`, 2),
across(where(is.numeric), round, 2))