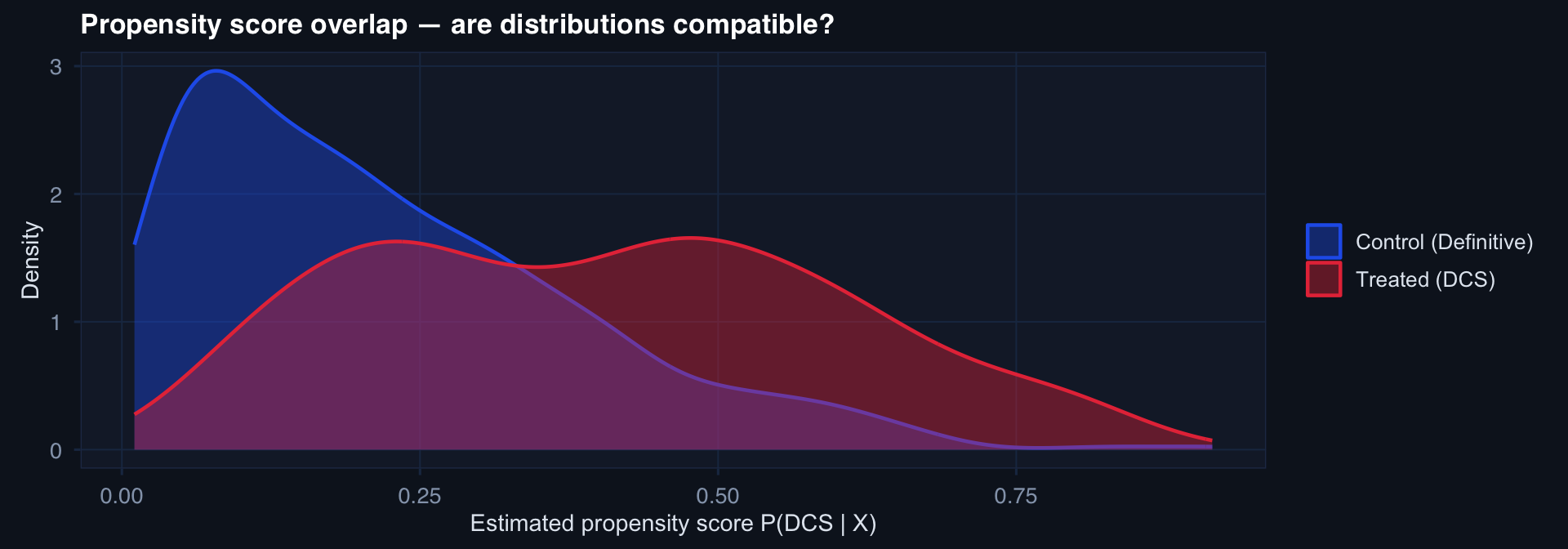
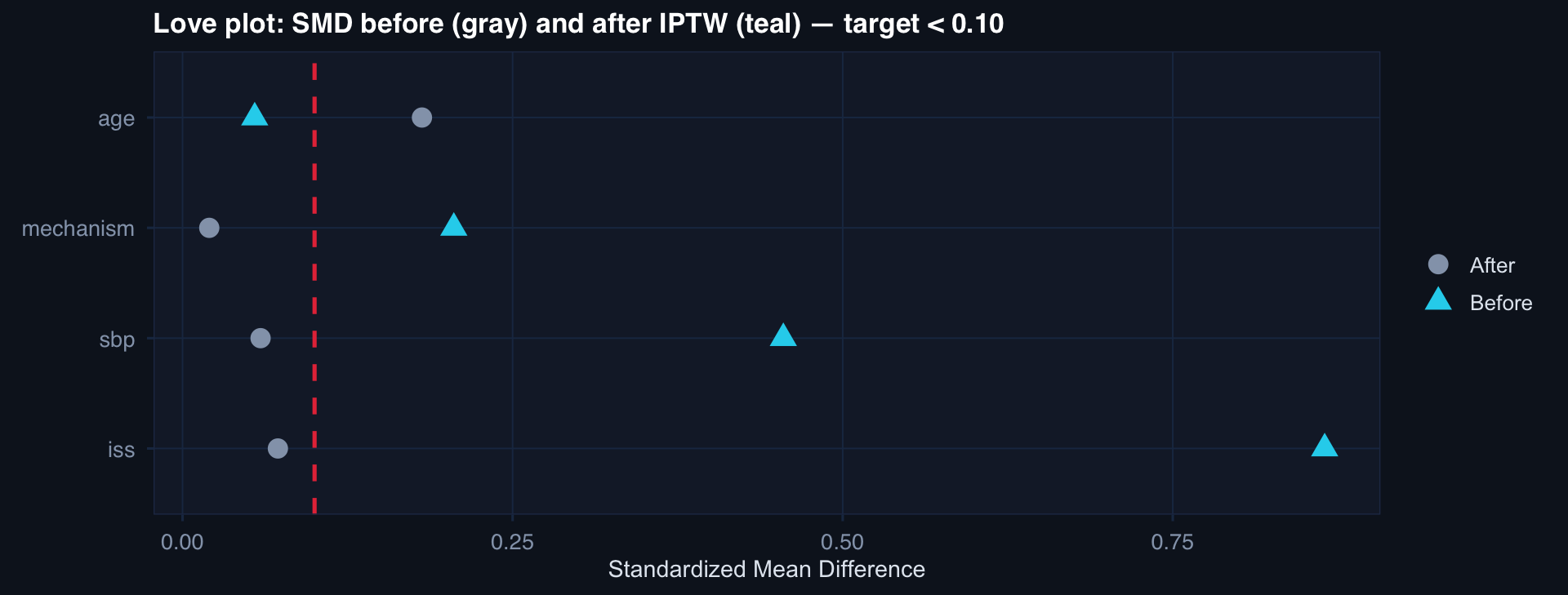
# IPTW weights
df_ps <- df_ps |> mutate(
iptw = ifelse(treated==1, 1/ps_hat, 1/(1-ps_hat))
)
# Compute SMD before and after
smd <- function(x, trt, w=NULL) {
if (is.null(w)) w <- rep(1, length(x))
m1 <- weighted.mean(x[trt==1], w[trt==1])
m0 <- weighted.mean(x[trt==0], w[trt==0])
s <- sqrt((var(x[trt==1]) + var(x[trt==0]))/2)
abs(m1 - m0) / s
}
vars <- c("age","iss","sbp","mechanism")
before <- sapply(vars, function(v) smd(df_ps[[v]], df_ps$treated))
after <- sapply(vars, function(v) smd(df_ps[[v]], df_ps$treated, df_ps$iptw))
smd_wide <- tibble(Variable=vars, Before=before, After=after)
smd_wide |>
pivot_longer(-Variable) |>
left_join(select(smd_wide, Variable, Before), by="Variable") |>
ggplot(aes(value, reorder(Variable, -Before), color=name, shape=name)) +
geom_point(size=4) +
geom_vline(xintercept=0.1, linetype=2, color="#e63946") +
scale_color_manual(values=c("#94a3b8","#22d3ee")) +
labs(title="Love plot: SMD before (gray) and after IPTW (teal) — target < 0.10",
x="Standardized Mean Difference", y=NULL, color=NULL, shape=NULL) +
theme_di()