n <- 300
df_blind <- tibble(
trt = rbinom(n, 1, 0.5),
# True physiologic effect = 1.5 units
phys = 1.5 * trt + rnorm(n, 0, 3),
# Expectation bias: treated patients report 1.0 additional units if unblinded
bias = ifelse(trt==1, rnorm(n, 1.0, 0.5), 0),
# Observed outcomes
y_blinded = phys,
y_unblinded = phys + bias
)
bind_rows(
broom::tidy(lm(y_blinded ~ trt, df_blind), conf.int=TRUE) |> mutate(Design="Blinded"),
broom::tidy(lm(y_unblinded ~ trt, df_blind), conf.int=TRUE) |> mutate(Design="Unblinded")
) |> filter(term=="trt") |>
ggplot(aes(estimate, Design, color=Design)) +
geom_point(size=5) +
geom_errorbarh(aes(xmin=conf.low, xmax=conf.high), height=0.2, linewidth=1) +
geom_vline(xintercept=1.5, linetype=2, color="#94a3b8") +
scale_color_manual(values=c("#e63946","#0891b2")) +
annotate("text", x=1.65, y=2.4, label="True effect", color="#94a3b8", size=3.5) +
labs(title="Expectation bias inflates the observed effect in unblinded trials",
x="Estimated treatment effect (95% CI)", y=NULL) +
theme_di() + theme(legend.position="none")Trial Integrity: Blinding, Adaptive Designs & Pragmatic Trials
Design of Experiments — Lecture 3 of 4
2026-01-01
Simulating Expectation Bias
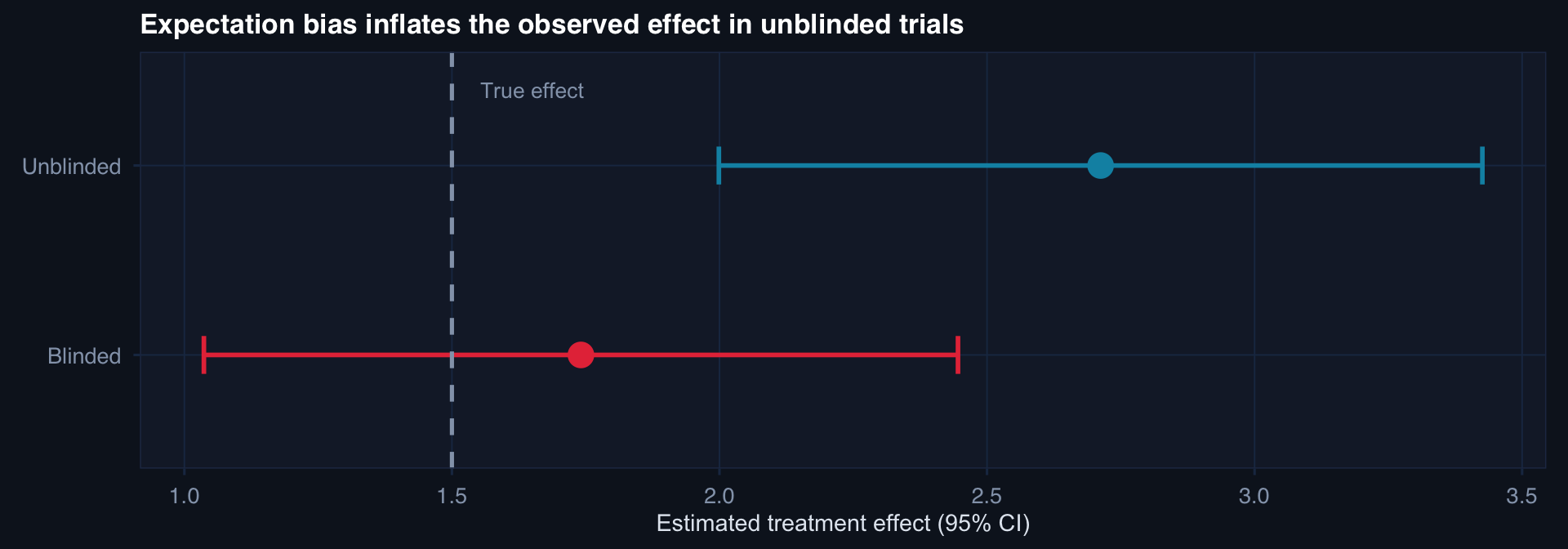
The unblinded estimate overstates the true effect by ~65%. In subjective outcomes (pain, function, quality of life), expectation bias can account for the majority of the observed effect.
Group-Sequential Stopping Rules
# Simulate a group sequential trial: 4 interim + 1 final look
# O'Brien-Fleming boundaries (conservative early, lenient late)
n_looks <- 5
info_fractions <- seq(0.2, 1.0, by=0.2)
# O'Brien-Fleming critical values (approximate)
obf_alpha <- c(4.56, 3.23, 2.63, 2.28, 2.04) / sqrt(n_looks)
# Simulate trial data with true treatment effect
n_total <- 200
trt <- rep(0:1, each=n_total/2)
y <- 10 - 1.8*trt + rnorm(n_total, 0, 4)
# Compute running z-statistic at each look
look_n <- floor(n_total * info_fractions)
z_stats <- sapply(look_n, function(k) {
idx <- 1:k
m1 <- mean(y[trt==1 & seq_along(trt) %in% idx])
m0 <- mean(y[trt==0 & seq_along(trt) %in% idx])
s <- sd(y[seq_along(y) %in% idx])
(m1 - m0) / (s * sqrt(2/k))
})
tibble(fraction=info_fractions, z=abs(z_stats), boundary=obf_alpha) |>
ggplot(aes(fraction)) +
geom_ribbon(aes(ymin=0, ymax=boundary), fill="#253554", alpha=0.6) +
geom_line(aes(y=boundary), color="#e63946", linewidth=1.2, linetype=2) +
geom_line(aes(y=z), color="#0891b2", linewidth=1.3) +
geom_point(aes(y=z), color="#22d3ee", size=4) +
annotate("text", x=0.85, y=3.0, label="O'Brien-Fleming\nboundary", color="#e63946", size=3.2) +
annotate("text", x=0.55, y=1.2, label="Observed |Z|", color="#0891b2", size=3.2) +
labs(title="Group-sequential trial: |Z| crosses boundary at final look → stop for efficacy",
x="Information fraction (proportion of data observed)", y="|Z statistic|") +
theme_di()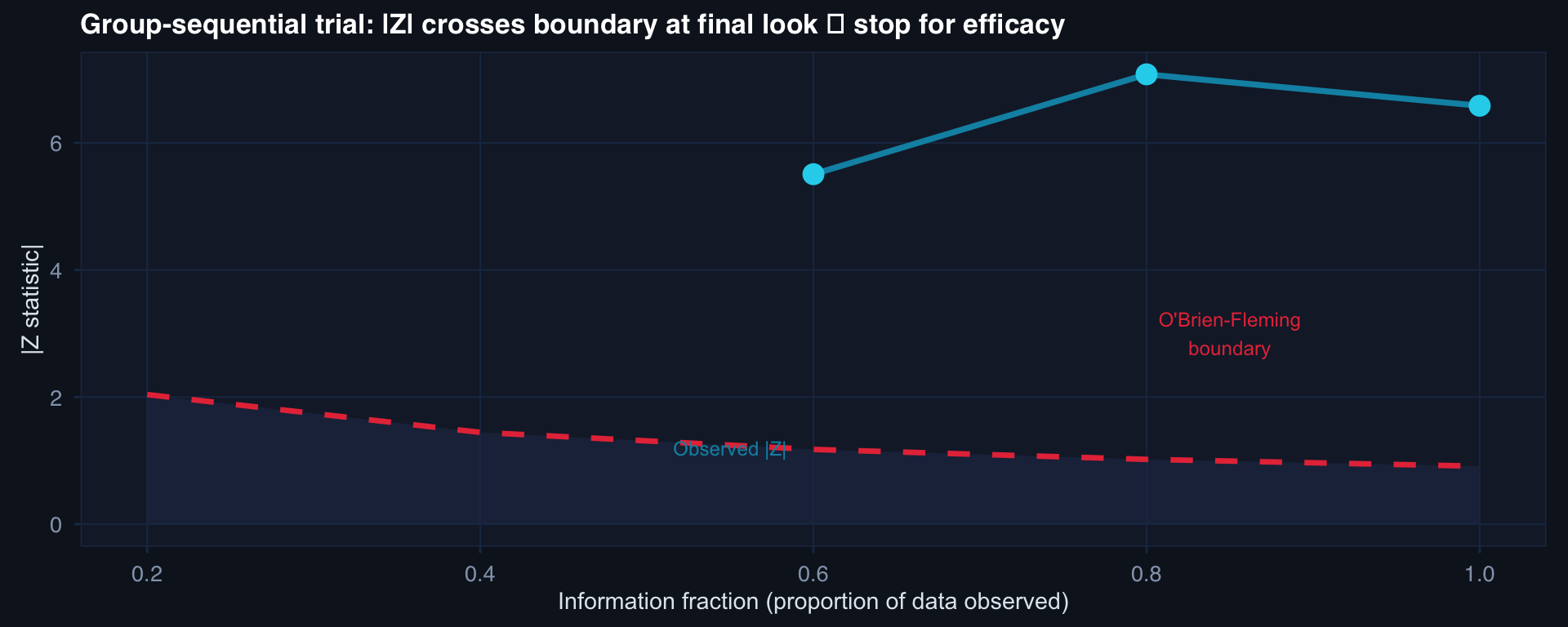
O’Brien-Fleming: boundary is high early (conservative) and converges to ~1.96 at the final look. Preserves type I error at α = 0.05 across all looks.
Cluster Randomization: When Individual Randomization Is Impossible
# Demonstrate ICC and design effect in cluster-randomized data
n_clusters <- 20; n_per <- 25
ICC <- 0.12 # within-facility correlation
# Simulate clustered binary outcomes
cluster_effects <- rnorm(n_clusters, 0, sqrt(ICC))
df_cluster <- expand_grid(cluster=1:n_clusters, patient=1:n_per) |>
mutate(
trt = ifelse(cluster <= n_clusters/2, 1, 0),
u_clust = cluster_effects[cluster],
y = rbinom(n(), 1, plogis(-1.5 + 0.6*trt + u_clust))
)
# Show within-cluster similarity
df_cluster |>
group_by(cluster, trt) |>
summarise(rate=mean(y), .groups="drop") |>
ggplot(aes(factor(cluster), rate, fill=factor(trt))) +
geom_col(alpha=0.85) +
scale_fill_manual(values=c("#2563eb","#e63946"),
labels=c("Control facility","Treatment facility")) +
labs(title=paste0("Cluster-randomized trial: ICC = ", ICC,
" → design effect ≈ ", round(1 + (n_per-1)*ICC, 2),
"× larger required n"),
x="Facility (cluster)", y="Outcome rate", fill=NULL) +
theme_di() + theme(axis.text.x=element_blank())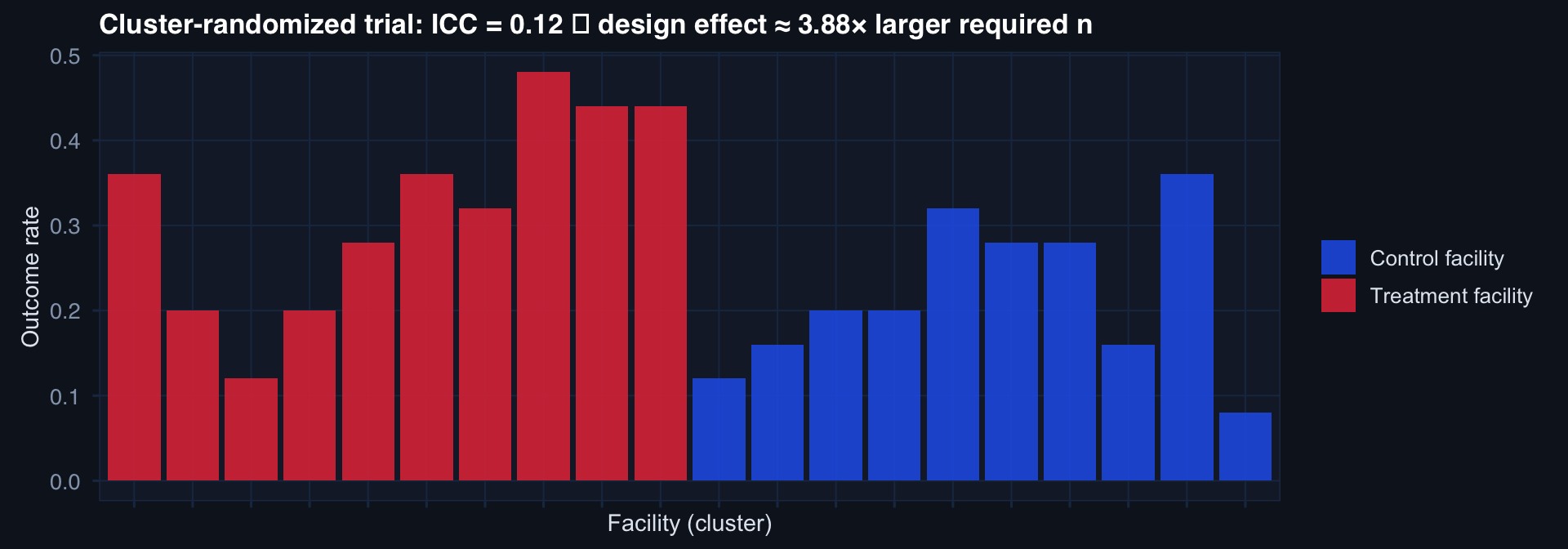
Design effect (DEFF) = \(1 + (m-1) \cdot \text{ICC}\) where \(m\) = cluster size.
ICC = 0.12, m = 25 → DEFF ≈ 4.0 → need 4× as many patients as individual randomization would require. Underestimating ICC is the most common power error in cluster trials.