tibble(
complexity = 1:10,
bias_sq = (5 / (1:10))^2,
variance = (0.3 * (1:10))^2,
) |>
dplyr::mutate(total = bias_sq + variance + 4) |>
tidyr::pivot_longer(-complexity) |>
ggplot(aes(complexity, value, color=name, linewidth=name)) +
geom_line() +
scale_color_manual(values=c("bias_sq"="#e63946","variance"="#2563eb",
"total"="#1b2e4b")) +
scale_linewidth_manual(values=c("bias_sq"=0.9,"variance"=0.9,"total"=1.4)) +
labs(title="Bias² + Variance + noise = total expected error",
x="Model complexity", y="Error", color=NULL, linewidth=NULL) + theme_di()Building Better Models: Bias, Variance & Validation
Applied Statistics for AI & Clinical Decision-Making — Lecture 8 of 10
2026-01-01
The Bias-Variance Curve
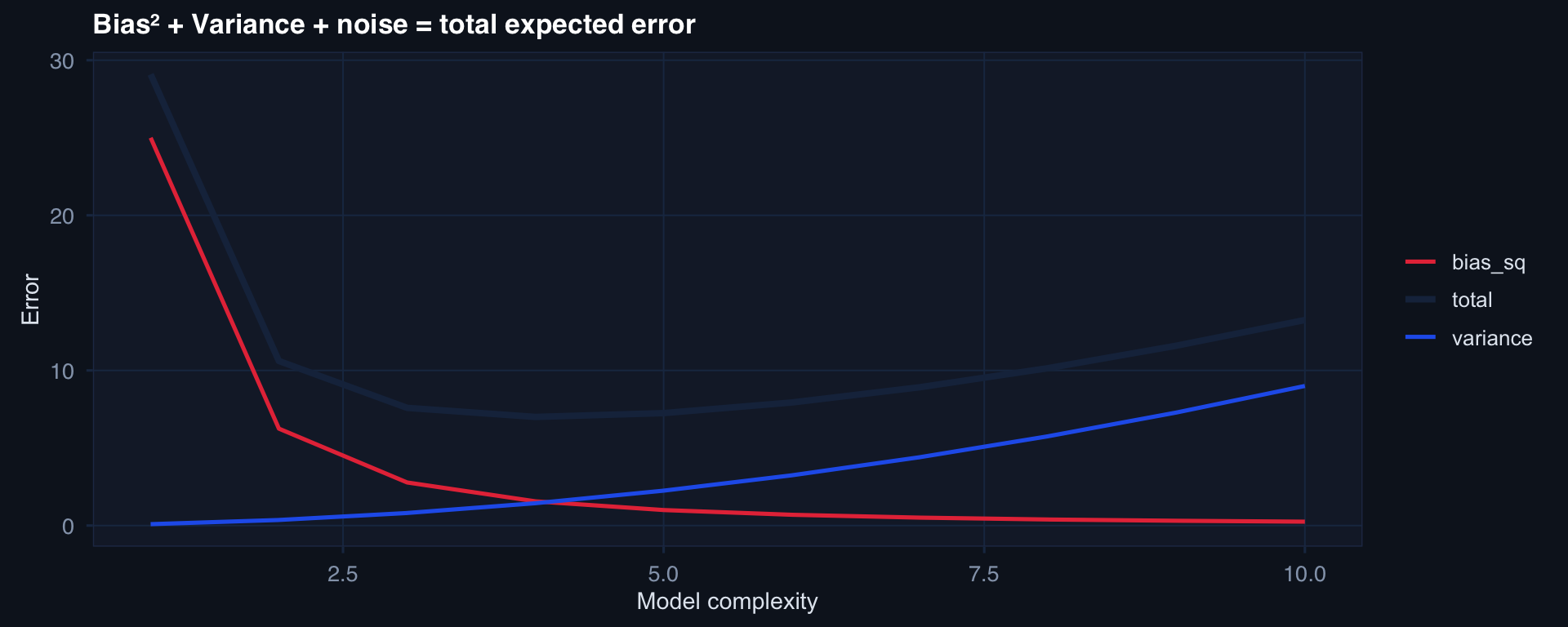
The sweet spot: find the complexity that minimizes total error — not bias alone or variance alone.
Lasso Path: Automatic Feature Selection
n <- 200; p <- 20
X <- matrix(rnorm(n*p), n, p)
# Only first 4 features truly predict outcome
beta_true <- c(2,-1.5,1,-0.8, rep(0,16))
y <- X %*% beta_true + rnorm(n)
fit_lasso <- glmnet(X, y, alpha=1)
plot(fit_lasso, xvar="lambda", label=TRUE,
main="Lasso coefficient paths — features shrink to zero")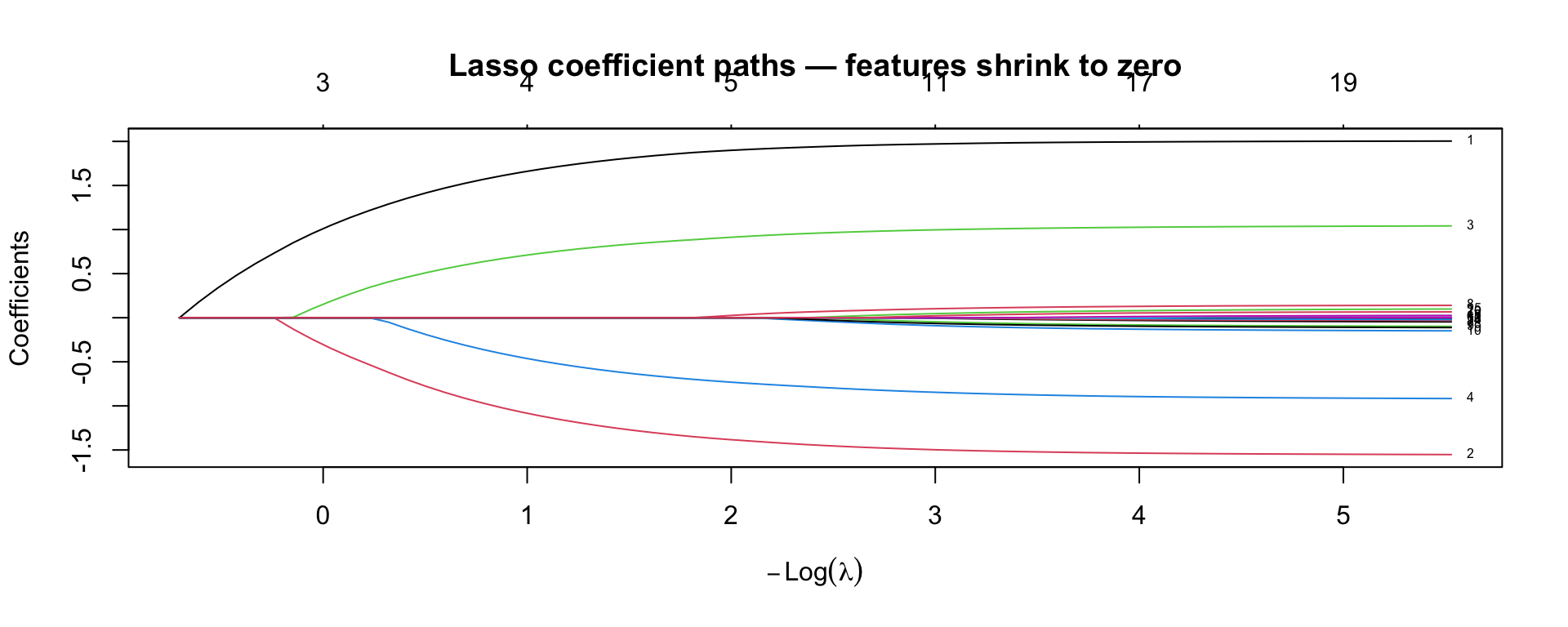
As λ increases (more regularization), coefficients are forced to zero. The 4 true predictors (1–4) survive longest.
Choosing λ with Cross-Validation
Optimal λ: 0.0489
λ 1-SE rule: 0.1495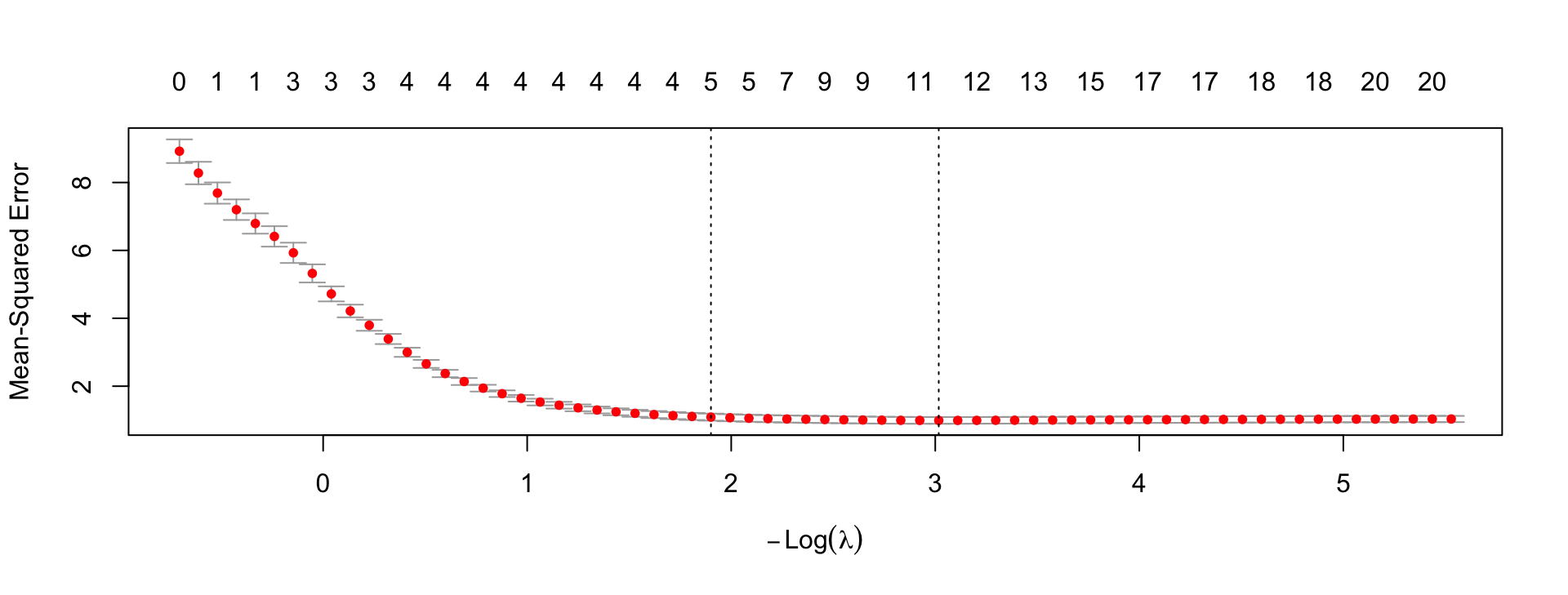
1-SE rule: prefer the simplest model within 1 standard error of the minimum CV error — favors parsimony.