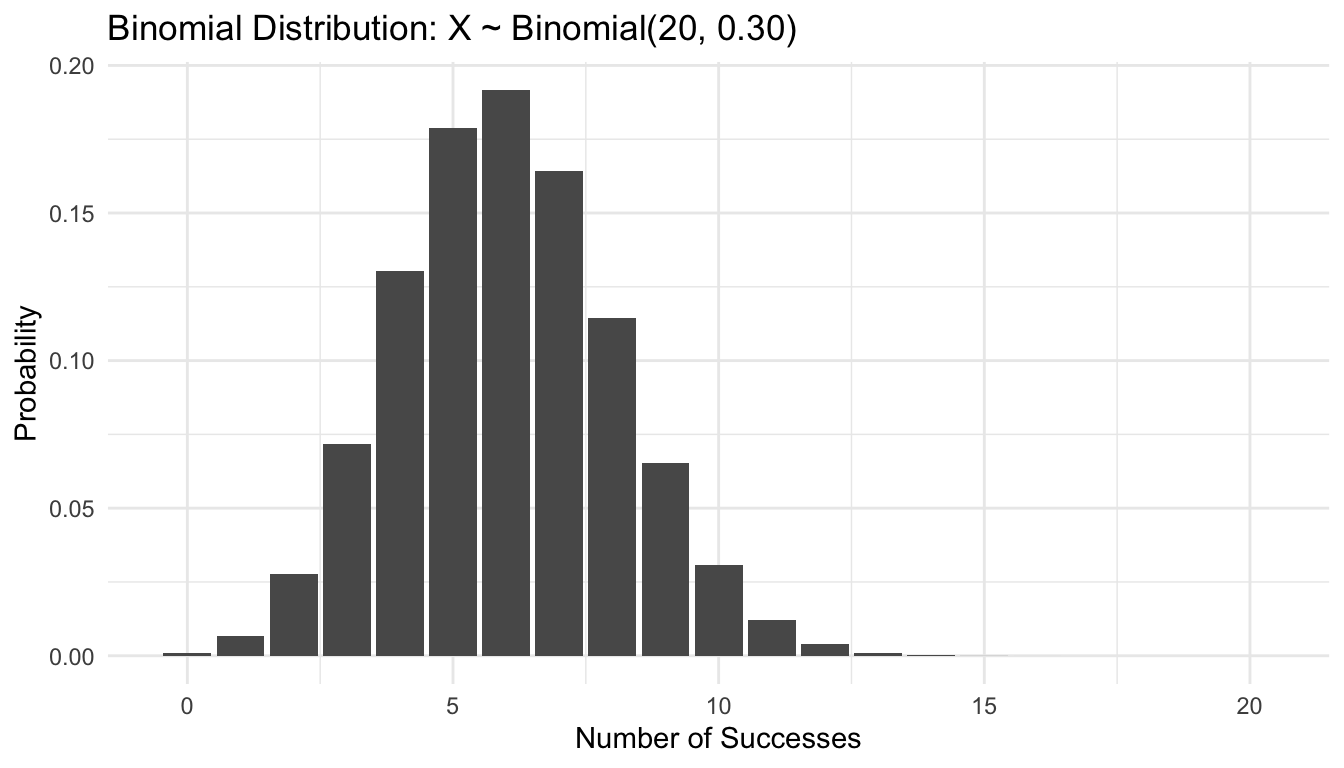
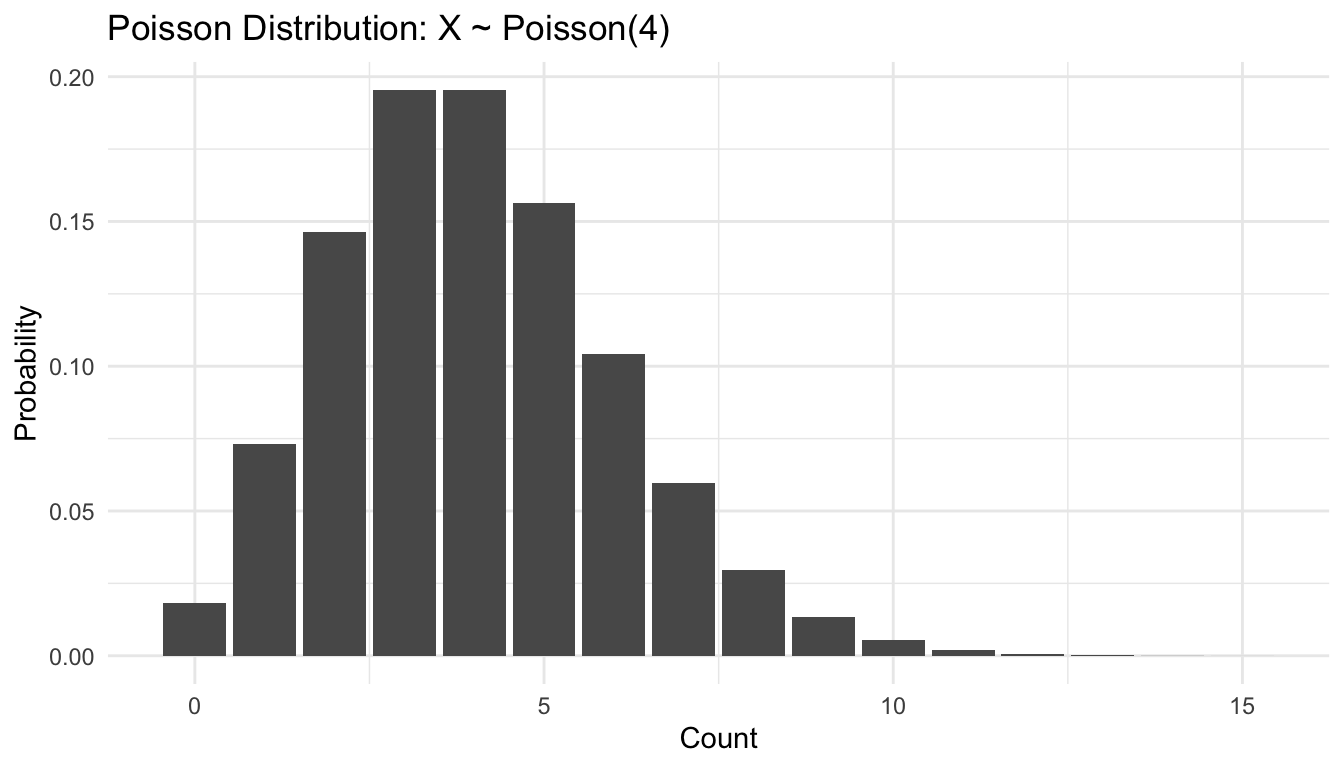
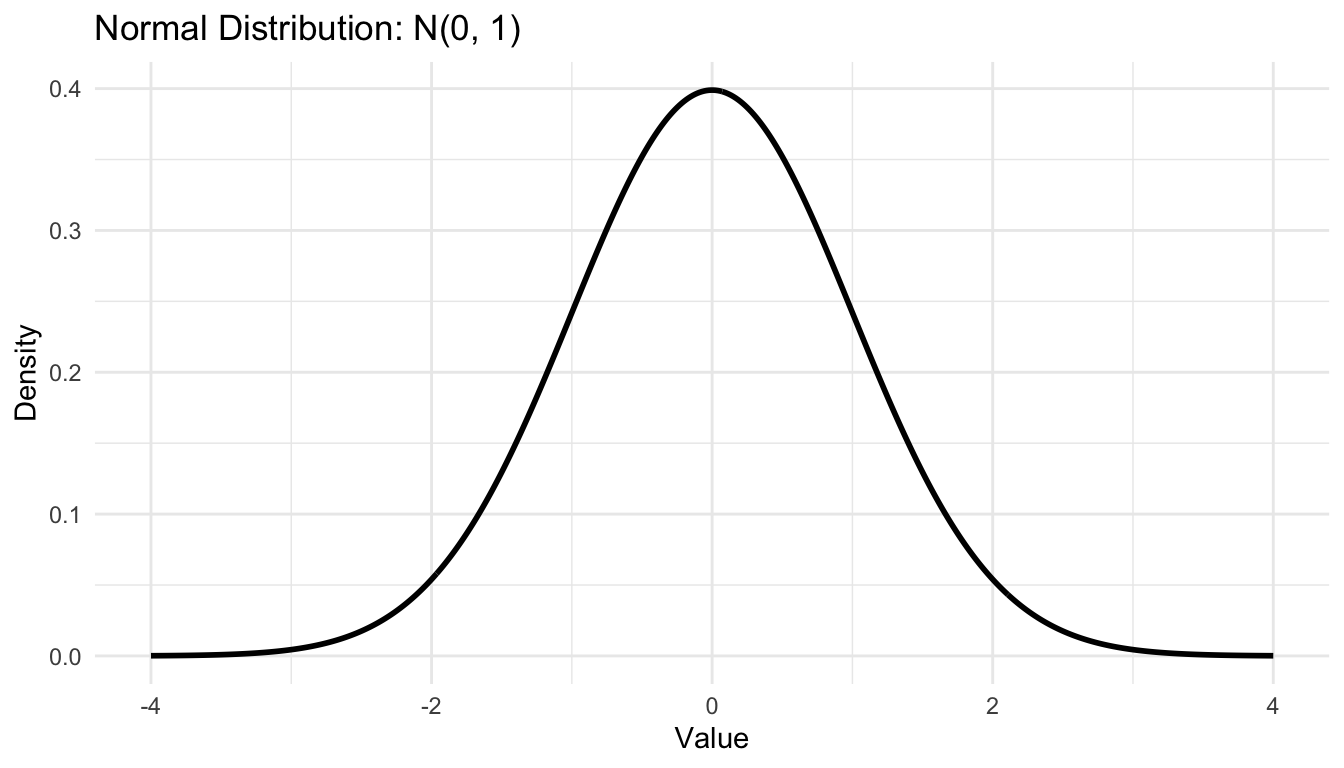
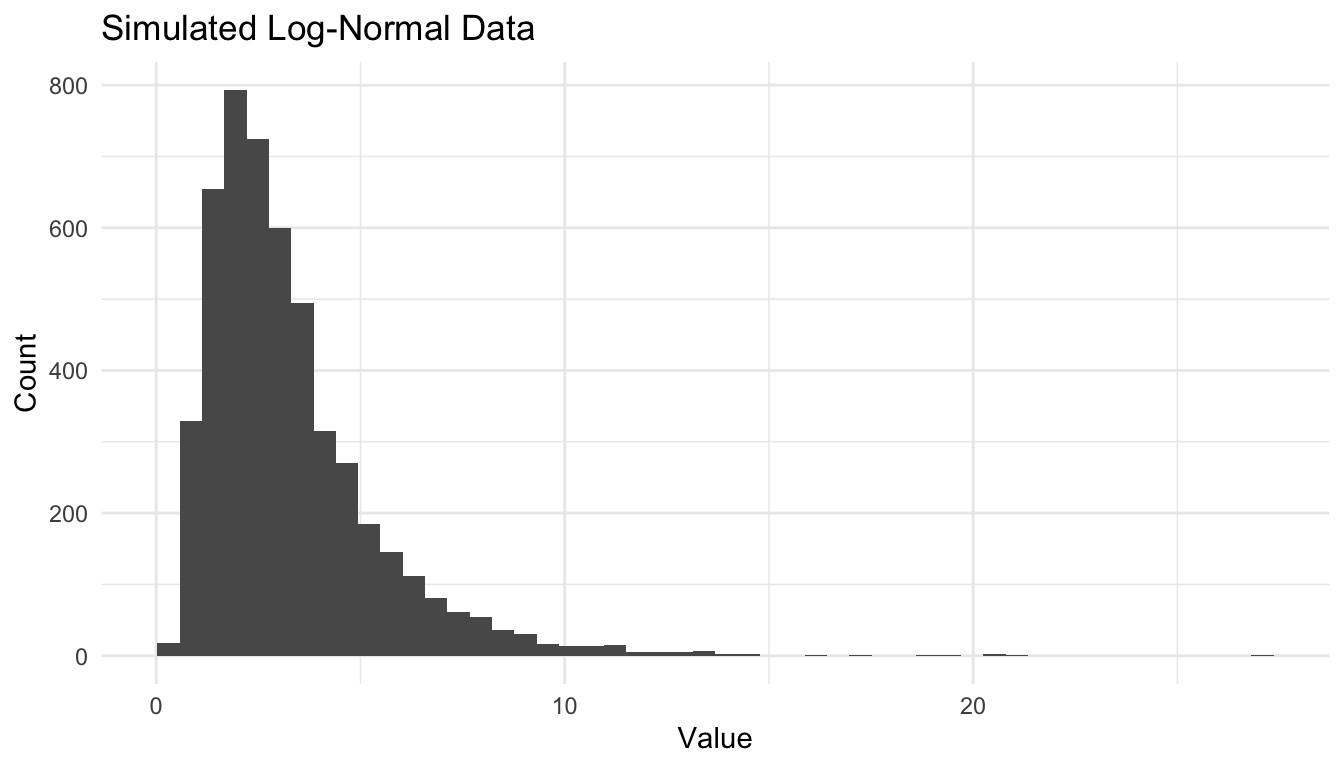
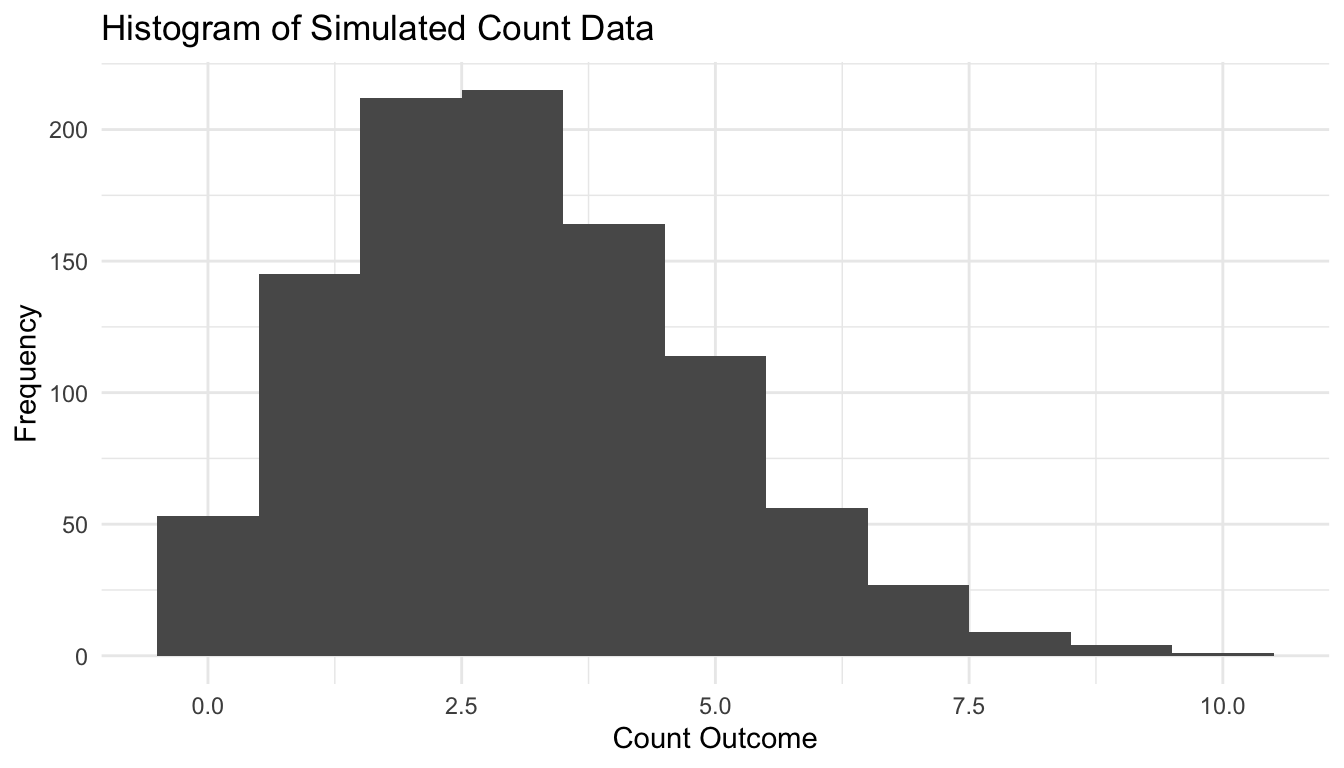
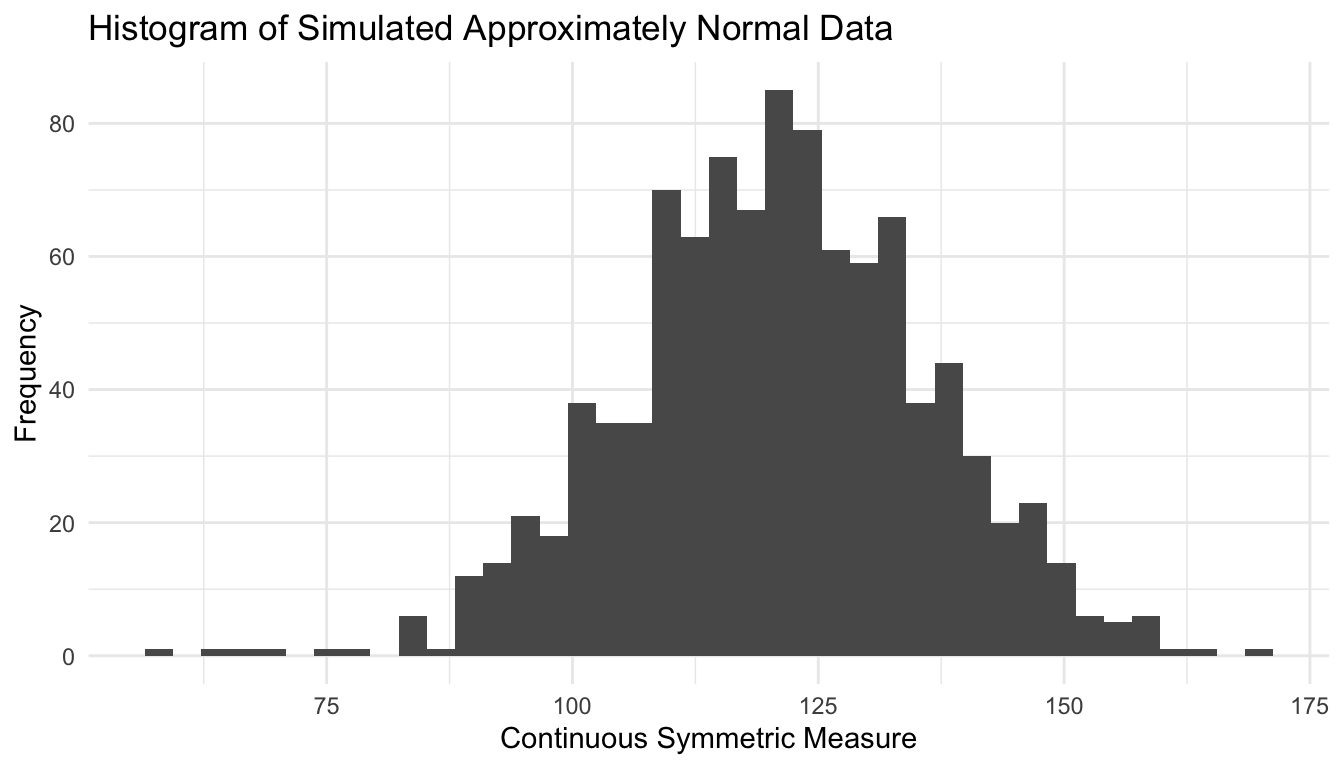
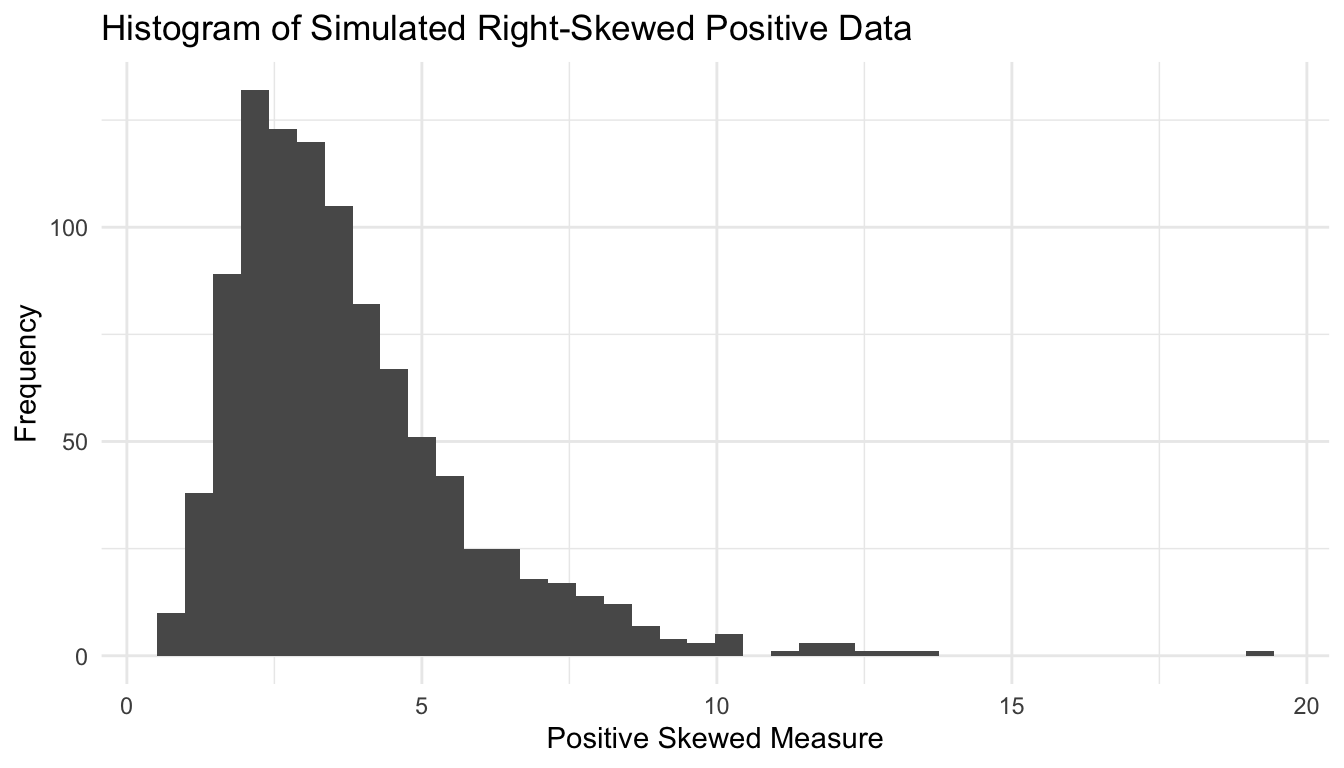
This kind of visual screening is not a substitute for formal modeling, but it is often the first step in deciding which probability family is reasonable.
Maximum Likelihood Estimation Connects Distributions to Data
Once we choose a probability family, we usually need to estimate its parameters from observed data.
This is where maximum likelihood estimation (MLE) comes in.
The basic idea is simple:
choose the parameter values that make the observed data most plausible under the model.
For example, if data are assumed normal, MLE estimates the mean and variance.
If data are assumed Poisson, MLE estimates the rate parameter \(\lambda\).
If data are assumed Binomial with known \(n\), MLE estimates the success probability \(p\).
Here is a simple example using simulated Poisson data.
# A tibble: 2 × 2
parameter estimate
<chr> <dbl>
1 mu 10.0
2 sigma 1.91
MLE is a major bridge between classical statistics and machine learning because many training algorithms can be interpreted as likelihood-based optimization.
Transformations Help When Raw Data Do Not Fit Simple Assumptions
Real data do not always match textbook distributions.
One common response is transformation.
For example, a strongly right-skewed variable may become approximately symmetric after log transformation.
This matters because many modeling methods perform better when assumptions about symmetry, variance stability, or linear structure are more reasonable after transformation.
Simulation Is One of the Best Ways to Learn Distributions
One of the fastest ways to understand a distribution is to simulate from it.
Simulation makes abstract formulas concrete.
Here is a comparison of repeated samples from several common distributions.
Simulation is useful not only for learning, but also for:
checking analytic expectations,
stress-testing assumptions,
explaining uncertainty to stakeholders,
and generating synthetic datasets for workflow development.
Distribution Choice Affects Model Fit, Interpretation, and Error Behavior
A poor distributional assumption can distort:
parameter estimates,
standard errors,
prediction intervals,
calibration,
and interpretation.
For example:
fitting a Normal model to highly skewed positive data may yield misleading summaries,
fitting a Poisson model to overdispersed counts may underestimate variability,
treating bounded probabilities as unbounded continuous outcomes can create incoherent predictions.
This is why distribution choice is not a minor technicality. It is part of responsible modeling.
These Distributions Reappear Throughout AI/ML
Probability distributions are not confined to introductory statistics (Murphy 2012; Wasserman 2004).
They reappear across machine learning in practical ways.
Binomial / Bernoulli
Used in:
binary classification,
logistic regression,
probabilistic calibration,
yes/no outcomes.
Poisson
Used in:
count regression,
rate prediction,
event modeling,
queueing and operational forecasts.
Normal
Used in:
linear regression assumptions,
Gaussian generative models,
latent variable methods,
neural activation approximations.
Log-normal
Used in:
positive skewed outcomes,
multiplicative processes,
time and cost modeling,
transformed regression settings.
The details differ, but the core idea remains the same:
a distribution is a statement about uncertainty structure.
A Practical Checklist for Distributional Thinking
Before fitting a model, ask:
Is the outcome discrete or continuous?
Is it bounded, unbounded, or strictly positive?
Is the distribution symmetric or skewed?
Are zeros common?
Does the variance appear tied to the mean?
Would a transformation improve interpretability or fit?
Does the chosen distribution match the real data-generating story?
These questions often matter as much as the algorithm itself.
NoteWhere This Shows Up in AI/ML
Distribution shift — the mismatch between the distribution of training data and the distribution encountered at deployment — is the single most common cause of clinical AI failure in real-world settings; a sepsis model trained on a tertiary academic medical center’s patient population follows a very different joint distribution of vitals, labs, and comorbidities than the combat casualty population seen at a deployed Role 2E, and applying it without revalidation produces systematically miscalibrated probabilities. The DoDTR trauma registry captures a distribution of injury patterns, physiologic derangement, and time-to-care that is categorically unlike civilian trauma center data, so any model trained on NTDB and deployed in a military context is operating outside its training distribution from the first patient.
Closing: Data Science Requires More Than Algorithms
It is tempting to think of modeling as mainly an algorithmic exercise.
But before an algorithm can learn, someone must decide what kind of uncertainty the data represent.
That is what probability distributions do.
Binomial, Poisson, Normal, and Log-normal models are not just textbook objects. They are recurring templates for reasoning about proportions, counts, symmetric measurements, and skewed positive outcomes.
Understanding these distributions improves more than technical accuracy. It improves model choice, interpretation, diagnostics, and communication.
Strong data science depends not only on fitting models well, but on choosing the right distributional language for the problem.
This post is part of the Prediction Modeling Toolkit — a companion reference with distributional assumption checks, goodness-of-fit templates, and simulation code for common statistical distributions.