# A tibble: 6 × 4
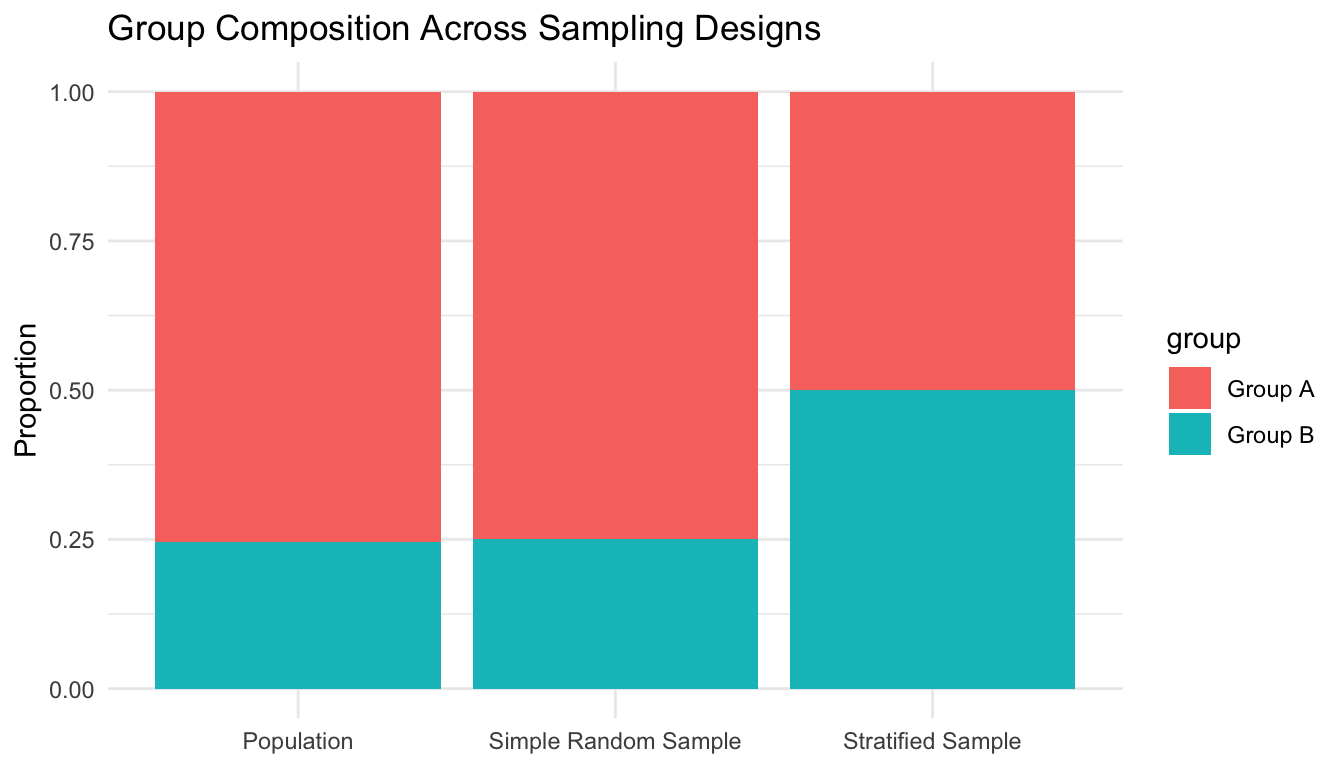
group n source pct
<chr> <int> <chr> <dbl>
1 Group A 7538 Population 0.754
2 Group B 2462 Population 0.246
3 Group A 300 Simple Random Sample 0.75
4 Group B 100 Simple Random Sample 0.25
5 Group A 200 Stratified Sample 0.5
6 Group B 200 Stratified Sample 0.5
ggplot2::ggplot(composition_df, ggplot2::aes(x = source, y = pct, fill = group)) + ggplot2::geom_col(position ="stack") + ggplot2::labs(title ="Group Composition Across Sampling Designs",x =NULL,y ="Proportion" ) + ggplot2::theme_minimal()
This is especially relevant when rare subgroups matter scientifically or operationally.
Sampling Design Affects Bias and Variance
Sampling is not only about representation. It also influences bias and variance.
At a high level:
bias reflects systematic deviation from the truth,
variance reflects instability across repeated samples.
A poor sampling strategy can produce biased estimates. A small but unbiased sampling design may still have high variance.
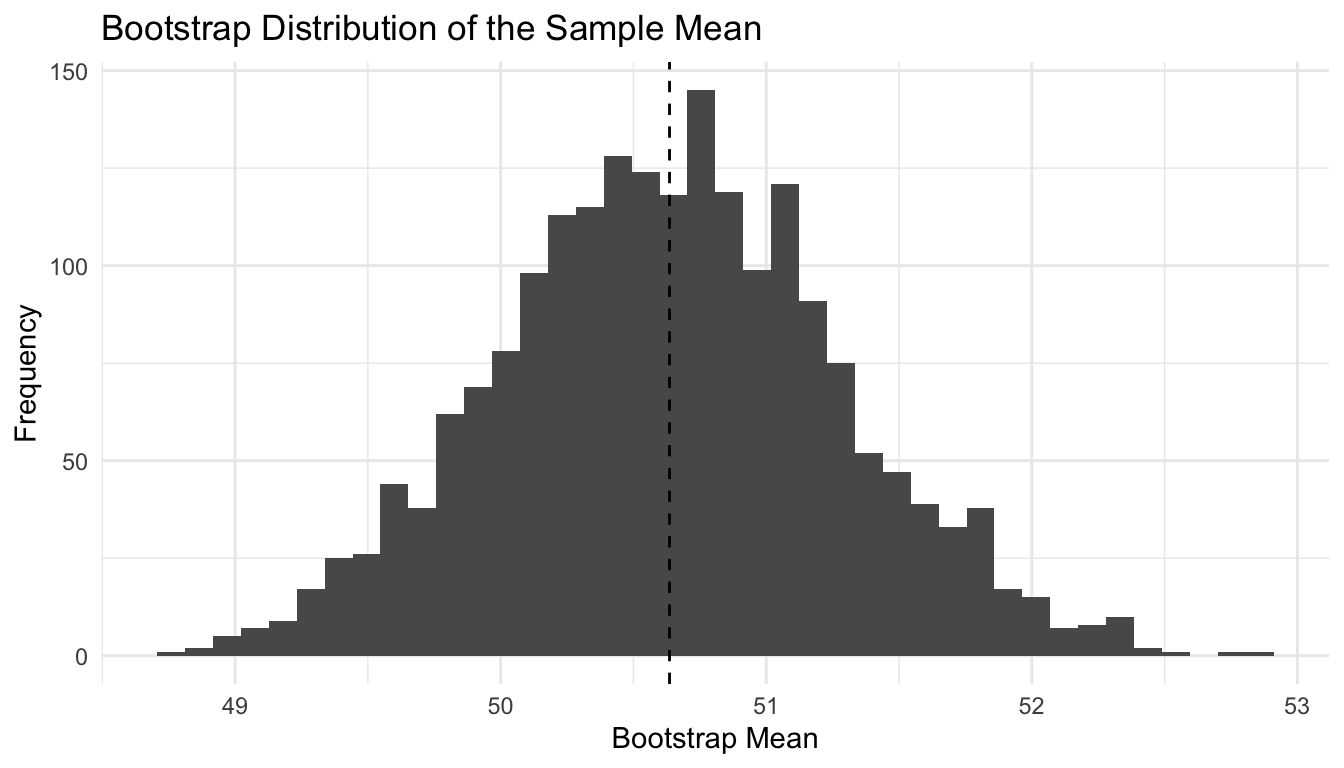
We can compare repeated simple random samples and repeated stratified samples for estimating the population mean of y.
Instead, it repeatedly samples with replacement from the observed dataset (Efron and Tibshirani 1993).
The key idea is:
if the observed sample is a reasonable stand-in for the underlying population, then repeated resampling from it can approximate the sampling distribution of a statistic.
This is one of the most useful tools in modern applied statistics.
It helps estimate:
standard errors,
confidence intervals,
optimism in model performance,
uncertainty in regression coefficients,
and stability of predictive metrics.
We will start with a bootstrap estimate for the mean.
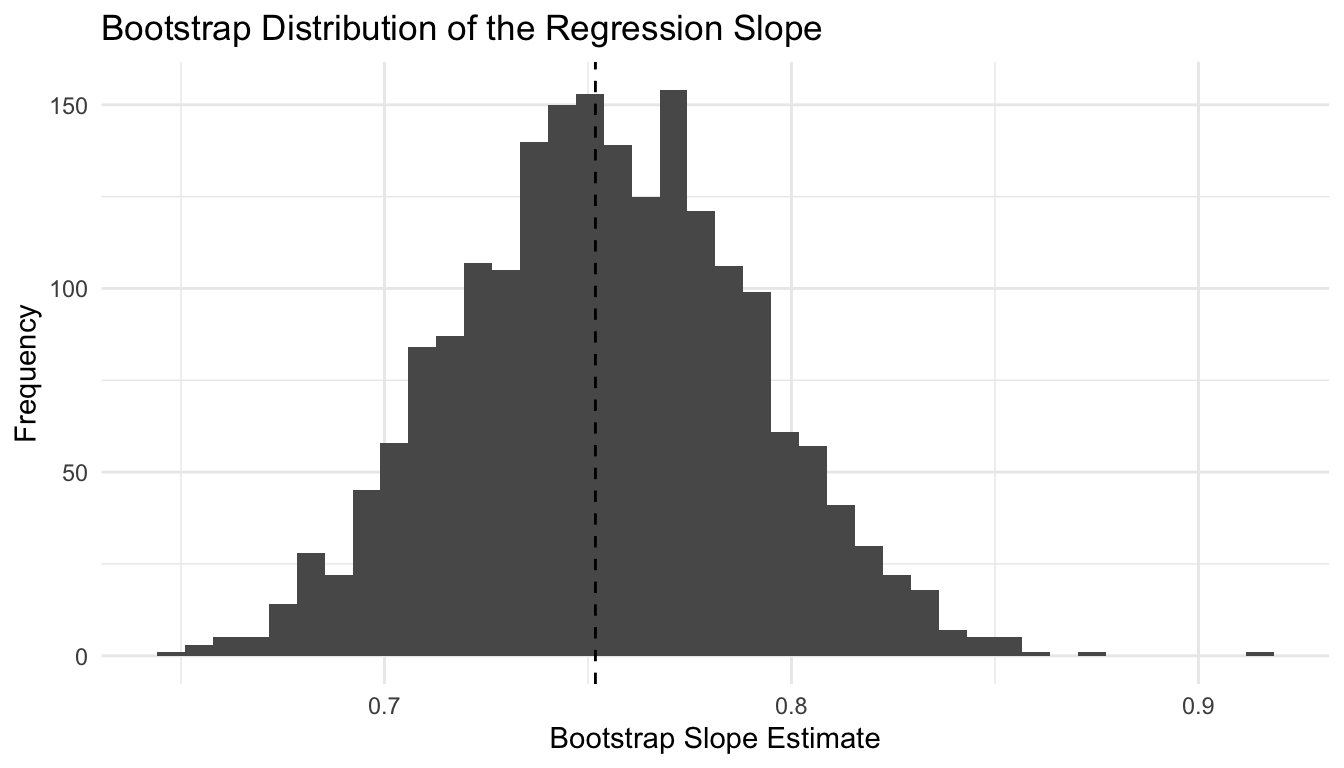
ggplot2::ggplot(boot_slopes, ggplot2::aes(x = slope)) + ggplot2::geom_histogram(bins =40) + ggplot2::geom_vline(xintercept =coef(fit_lm)[["x"]], linetype =2) + ggplot2::labs(title ="Bootstrap Distribution of the Regression Slope",x ="Bootstrap Slope Estimate",y ="Frequency" ) + ggplot2::theme_minimal()
This gives a bootstrap-based confidence interval for the slope without relying only on model-based normal theory.
Why Bootstrapping Matters for ML
Bootstrapping is deeply connected to machine learning practice.
It helps with:
uncertainty quantification,
model stability assessment,
optimism correction,
ensemble learning,
bagging,
and repeated performance estimation.
Random forests, for example, rely on bootstrap-like resampling of training data for tree construction.
More generally, resampling gives analysts a way to ask:
how much would this result change if the sample had been slightly different?
That is a powerful question in any predictive workflow.
Sampling Also Matters for Class Imbalance
Many ML problems involve rare outcomes.
Examples include:
fraud detection,
adverse event prediction,
rare disease classification,
mortality prediction,
equipment failure.
In those settings, naive random sampling can create distorted training sets or unstable validation results.
Common responses include:
stratified splitting,
oversampling minority classes,
undersampling majority classes,
weighted losses,
synthetic resampling approaches.
Not all of these are “sampling” in the classical survey sense, but they are all part of the broader problem of how data are selected, balanced, and presented to the model.
Cross-Validation Is Also a Sampling Workflow
Cross-validation is often described as a model evaluation strategy, but it is also a sampling design.
Each split selects:
a training subset,
a validation subset,
and a repeated structure for averaging performance.
That means cross-validation inherits many of the same concerns:
representativeness,
fold stability,
outcome balance,
dependence,
and estimator variability.
Seen this way, cross-validation is not separate from sampling theory. It is one of its modern applied extensions.
Bias-Variance Tradeoffs Often Show Up Through Resampling
Resampling methods also help analysts reason about bias and variance.
For example:
a small training sample may yield high-variance model estimates,
an imbalanced split may bias evaluation,
bootstrap distributions can reveal estimator instability,
repeated folds can expose sensitivity to data partitioning.
This is one reason resampling is so important in model governance.
It helps move beyond a single-number estimate toward a distributional understanding of performance.
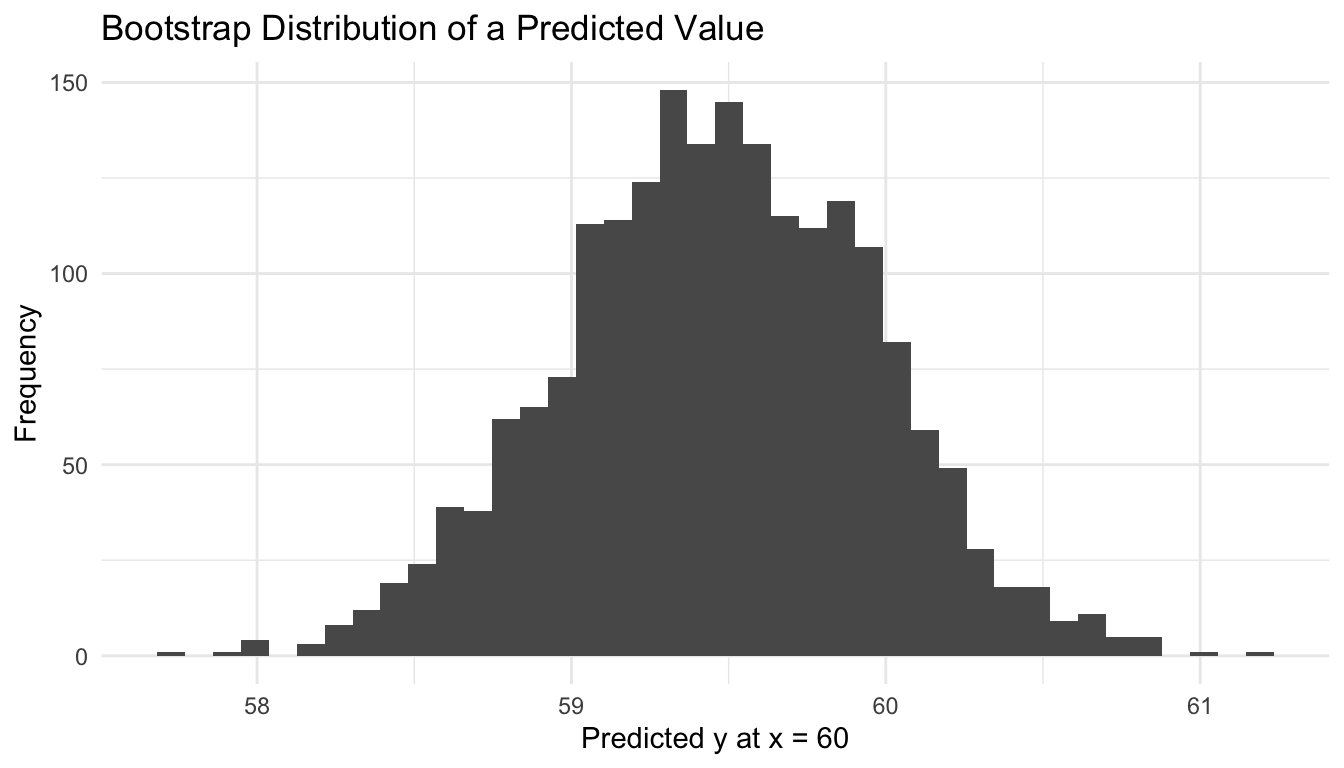
A Simple Bootstrap Prediction Example
We can push the regression example one step further by generating predicted values at a fixed x and bootstrapping that prediction.
ggplot2::ggplot(boot_preds, ggplot2::aes(x = pred)) + ggplot2::geom_histogram(bins =40) + ggplot2::labs(title ="Bootstrap Distribution of a Predicted Value",x ="Predicted y at x = 60",y ="Frequency" ) + ggplot2::theme_minimal()
This is often more tangible for readers because it connects uncertainty directly to an estimated model output.
Sampling Does Not Fix Bad Data
It is important not to romanticize resampling.
No sampling method can fully rescue:
systematic measurement error,
unmeasured confounding,
selection bias,
severe distribution shift,
or poor variable definitions.
Bootstrap intervals, for example, quantify uncertainty conditional on the observed sample. They do not automatically correct structural flaws in the data-generating process.
This is especially important in clinical and operational settings.
More resampling does not equal more truth if the source data are fundamentally biased.
A Practical Checklist for Applied Work
Before choosing a sampling strategy, ask:
Am I trying to estimate a population quantity, preserve subgroup structure, or quantify uncertainty?
Is subgroup representation important?
Is the outcome imbalanced?
Do I need analytic standard errors, or would bootstrap intervals be more useful?
Is my evaluation sensitive to how I split the data?
Am I using resampling to understand instability, or pretending it solves bias?
These questions usually matter as much as the model itself.
NoteWhere This Shows Up in AI/ML
Bootstrap resampling is the standard method for constructing confidence intervals around AUC, Brier score, and calibration slope for clinical prediction models — the FDA’s guidance on AI/ML-based software as a medical device explicitly recommends reporting these interval estimates rather than point metrics, because point AUC alone cannot support a deployment decision. The DoDTR suffers from systematic sampling bias toward patients who survived long enough to reach a trauma center with registry infrastructure, meaning any model trained on DoDTR without correcting for this survivorship bias will underestimate mortality risk for the most severely injured casualties — exactly the patients where decision support matters most.
Closing: Sampling Is Part of the Model, Not Just the Data Prep
Sampling methods shape what we learn from data.
Simple random sampling gives a clean baseline. Stratified sampling protects representation where subgroup structure matters. Bootstrap resampling helps quantify uncertainty when closed-form answers are difficult or unavailable.
In both biostatistics and machine learning, these are not side topics.
They affect:
estimation,
fairness,
model evaluation,
uncertainty quantification,
and how confidently we communicate results.
Reliable models do not come only from clever algorithms. They also come from thoughtful sampling, careful resampling, and honest uncertainty assessment.
This post is part of the Real-World Evidence Toolkit — a companion reference with sampling scheme templates, bootstrap confidence interval code, and survey-weighted analysis scaffolds.