Confidence Intervals: Your Shield Against Overconfident ML Models
Applied Statistics
Confidence Intervals
A practical guide to confidence intervals, coverage, bootstrap intervals, and uncertainty-aware interpretation for biostatistics and machine learning.
Published
October 15, 2023
Modified
June 9, 2026
Executive Summary
Point estimates are easy to report and easy to overtrust.
A mean can be written as a single number. A proportion can be written as a percentage. A model performance metric can be summarized with one statistic.
But none of those numbers are exact. They are estimates built from finite data.
and how cautious we should be when drawing conclusions.
This matters in both biostatistics and machine learning.
In biostatistics, confidence intervals help with:
treatment effect interpretation,
outcome rate estimation,
and study reporting.
In AI/ML, they help with:
uncertainty around model performance,
prediction intervals and uncertainty bounds,
calibration of claims,
and avoiding overconfident model communication.
A point estimate tells you what you saw. A confidence interval reminds you what you do not know with certainty.
Confidence Intervals Exist Because Estimates Are Noisy
Any estimate based on a sample is subject to variation.
If we drew a different sample from the same population, we would likely get a slightly different mean, proportion, regression slope, or performance metric.
That is not a flaw in statistics. It is the basic reality of learning from incomplete information.
Confidence intervals give us a structured way to quantify this uncertainty.
They do not eliminate noise. They make it visible.
This is one reason confidence intervals are so useful in applied work.
A result without uncertainty is often more persuasive-looking than it deserves to be.
What a Confidence Interval Actually Means
A confidence interval is commonly misunderstood.
A 95% confidence interval does not mean:
there is a 95% probability that the true parameter lies inside this particular interval.
Under the classical interpretation, the true parameter is fixed and the interval is random.
A 95% confidence interval means that:
if we repeated the sampling process many times and constructed intervals the same way each time, about 95% of those intervals would contain the true parameter.
This is a statement about the long-run behavior of the procedure.
That may feel subtle, but it matters.
Confidence intervals are best understood as properties of an estimation method, not as literal posterior probabilities.
Coverage Probability Is the Core Idea
The key technical idea behind confidence intervals is coverage.
Coverage probability is the proportion of repeated intervals that successfully contain the true parameter (Casella and Berger 2002).
For a nominal 95% confidence interval procedure, we hope the true long-run coverage is close to 0.95.
That does not mean every single interval will work. Some will miss.
This is why confidence intervals are not guarantees. They are uncertainty procedures with known operating characteristics, at least under assumptions.
Coverage is one of the most important concepts to understand if we want to interpret intervals honestly.
Parametric Confidence Intervals Depend on Distributional Assumptions
A parametric confidence interval relies on an assumed probability model.
For example:
a normal-theory interval for a mean,
a Wald-style interval for a proportion,
a t-based interval when the variance is estimated from the data.
These intervals are often efficient and familiar. But their performance depends on assumptions being at least reasonably appropriate.
This is why applied analysts should understand not only how to compute intervals, but also what assumptions support them.
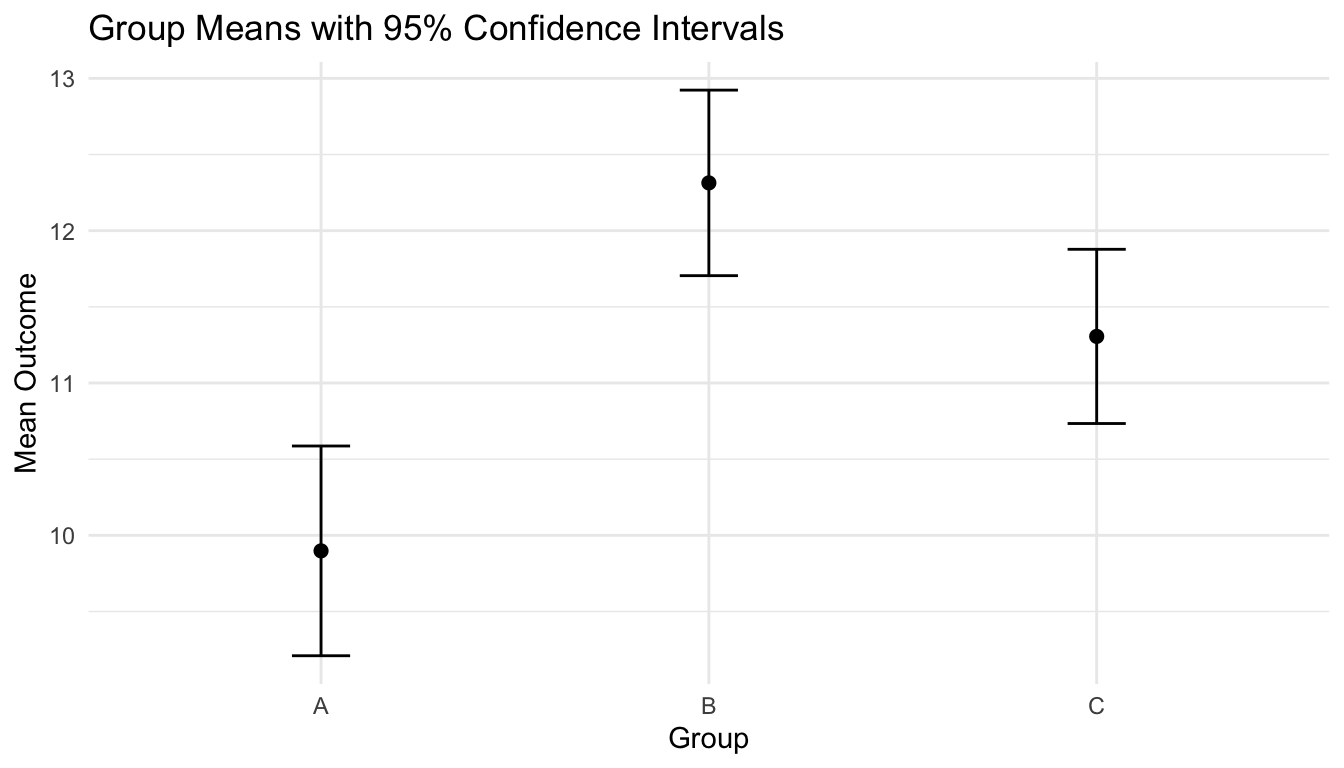
A Parametric Confidence Interval for a Mean
We begin with a simple example: estimating a population mean.
This gives an approximate confidence interval for the response probability.
Intervals for proportions are especially important because raw percentages can look more certain than they really are, particularly in small samples.
Non-Parametric Confidence Intervals Reduce Dependence on Strong Assumptions
A non-parametric confidence interval avoids or reduces reliance on a strict parametric distributional model.
One of the most practical tools here is the bootstrap.
The bootstrap repeatedly resamples from the observed dataset and approximates the sampling distribution of a statistic empirically (Efron and Tibshirani 1993).
This is useful when:
analytic formulas are inconvenient,
assumptions are uncertain,
or the statistic is more complicated than a simple mean.
Non-parametric does not mean assumption-free. But it often means assumption-light.
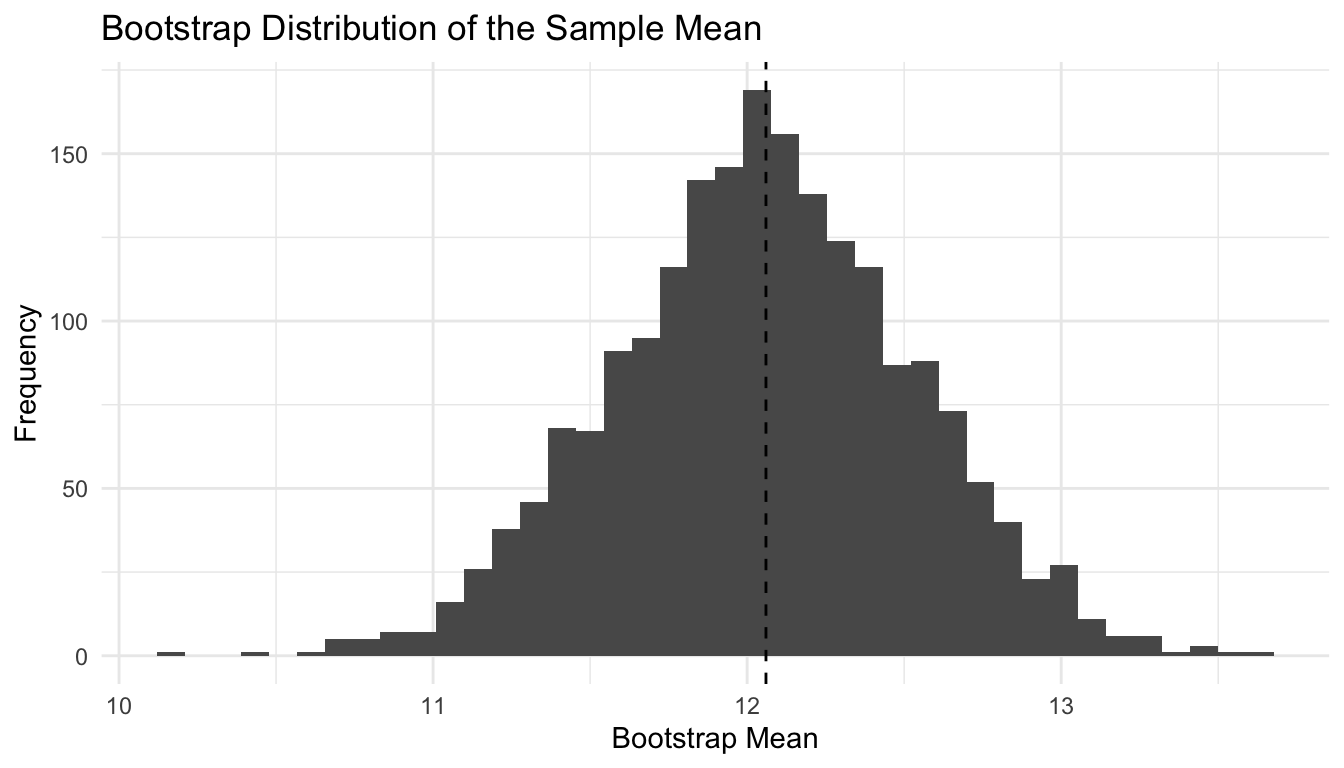
A Bootstrap Confidence Interval for a Mean
We can construct a bootstrap interval for the mean by repeatedly resampling the observed data with replacement.
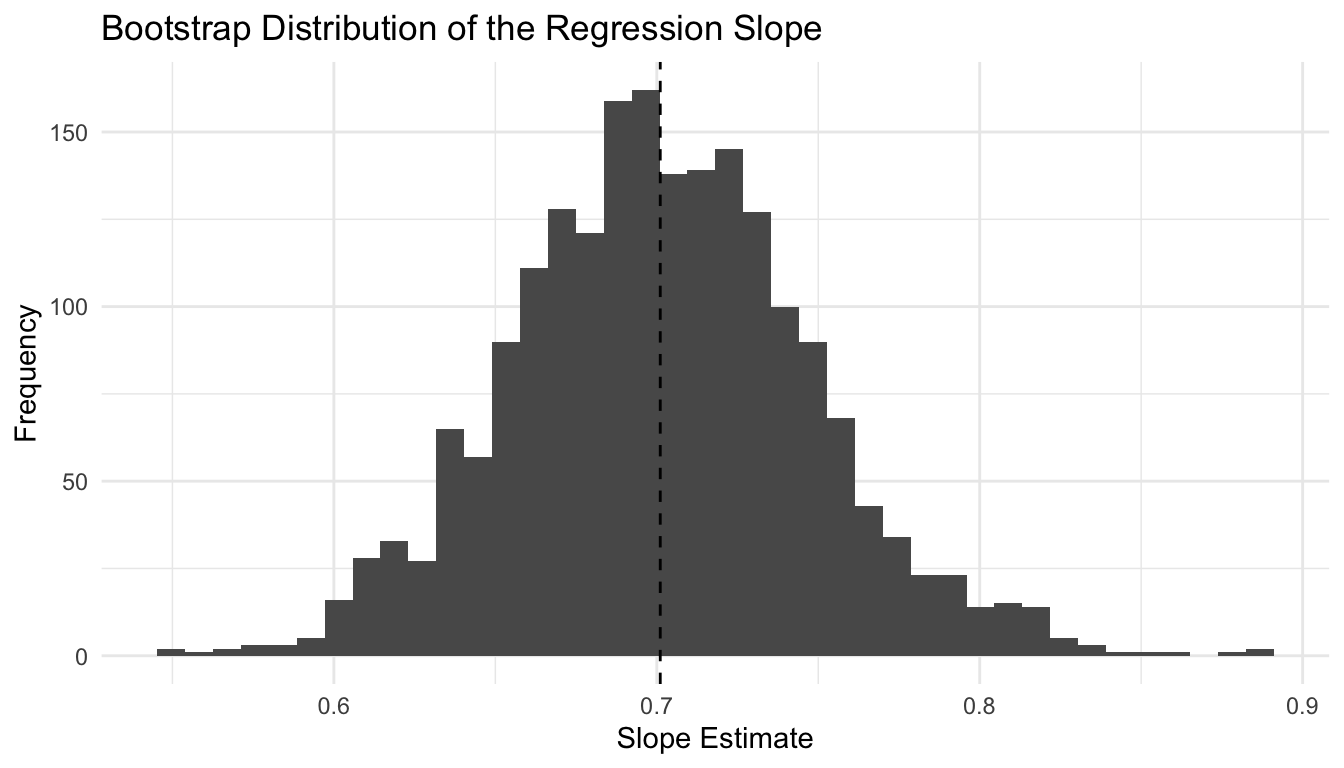
ggplot2::ggplot(boot_slope_df, ggplot2::aes(x = slope)) + ggplot2::geom_histogram(bins =40) + ggplot2::geom_vline(xintercept =coef(fit_lm)[["x"]], linetype =2) + ggplot2::labs(title ="Bootstrap Distribution of the Regression Slope",x ="Slope Estimate",y ="Frequency" ) + ggplot2::theme_minimal()
This is often an intuitive way to show uncertainty in model parameters without depending exclusively on asymptotic formulas.
Confidence Intervals Can Be Misused Too
Confidence intervals are often better than single p-values, but they can still be misread.
Common mistakes include:
treating them as probability statements about a fixed interval,
focusing only on whether the null value is included,
ignoring assumptions behind the interval,
mistaking narrowness for correctness,
forgetting that biased data can produce misleadingly precise intervals.
An interval can be narrow and still be wrong if the design, sampling, or measurement process is flawed.
So intervals improve communication, but they do not rescue bad data.
A Practical Checklist for Applied Work
Before reporting a confidence interval, ask:
What parameter does this interval refer to?
Is it parametric or non-parametric?
What assumptions support it?
Is the interval estimating a mean, a proportion, a regression effect, or a future prediction?
Does the interval show uncertainty clearly enough for the real decision?
Am I confusing confidence intervals with prediction intervals?
Does the width of the interval meaningfully affect interpretation?
These questions improve both rigor and clarity.
NoteWhere This Shows Up in AI/ML
Prediction intervals — not confidence intervals — are the correct output for individual-level clinical AI decisions: a model predicting 72-hour mortality for a specific trauma patient should report a prediction interval communicating the range of plausible outcomes for that individual, not a confidence interval around the mean prediction across similar patients. The FDA’s guidance on AI/ML-based medical devices now treats prediction interval width as a deployment readiness criterion, recognizing that a model with a point AUC of 0.84 but 95% prediction intervals spanning 0.3–0.95 across individual patients offers false precision that can mislead clinicians into overconfident action at the bedside.
Closing: Confidence Intervals Protect Against False Precision
Confidence intervals are one of the most useful tools in applied statistics because they resist the false certainty of point estimates.
They remind us that every estimate is conditional on finite data, variability, and assumptions.
That is true in biostatistics. It is equally true in AI and machine learning.
Confidence intervals help us:
communicate uncertainty,
compare estimates more honestly,
understand precision,
and resist overconfident claims from models or analysts.
Confidence intervals are not just a technical add-on. They are one of the simplest ways to force humility back into quantitative analysis.
This post is part of the Prediction Modeling Toolkit — a companion reference with interval estimation templates, bootstrap CI code, and reporting language for clinical prediction uncertainty.
Wasserman, Larry. 2004. All of Statistics: A Concise Course in Statistical Inference. Springer.
Wasserstein, Ronald L., and Nicole A. Lazar. 2016. “The ASA Statement on p-Values: Context, Process, and Purpose.”The American Statistician 70 (2): 129–33. https://doi.org/10.1080/00031305.2016.1154108.