Which parameter values make the observed data most plausible under the model?
That question is both mathematically elegant and practically powerful.
It drives estimation in many familiar statistical models, and it also sits underneath much of modern AI/ML, including:
logistic regression,
probabilistic classifiers,
latent-variable models,
and the EM algorithm used in unsupervised learning.
MLE matters because it turns model fitting into an optimization problem.
Instead of guessing parameters, we define a probability model for the data and then choose the parameter values that maximize the likelihood of what we actually observed.
This post introduces:
the intuition behind likelihood,
MLE for common distributions,
custom likelihood coding in R,
numerical optimization,
and comparison with method of moments.
MLE is one of the clearest examples of statistics and machine learning speaking the same language: model the data-generating process, write the objective function, and optimize.
Likelihood Turns Model Fitting into an Optimization Problem
In probability, we often think forward:
given a parameter value,
what is the probability of the data?
Likelihood reverses the emphasis.
In likelihood-based inference, the data are treated as fixed and the parameter is treated as unknown.
We ask:
for the observed data, which parameter values make them most plausible?
This shift is subtle but fundamental.
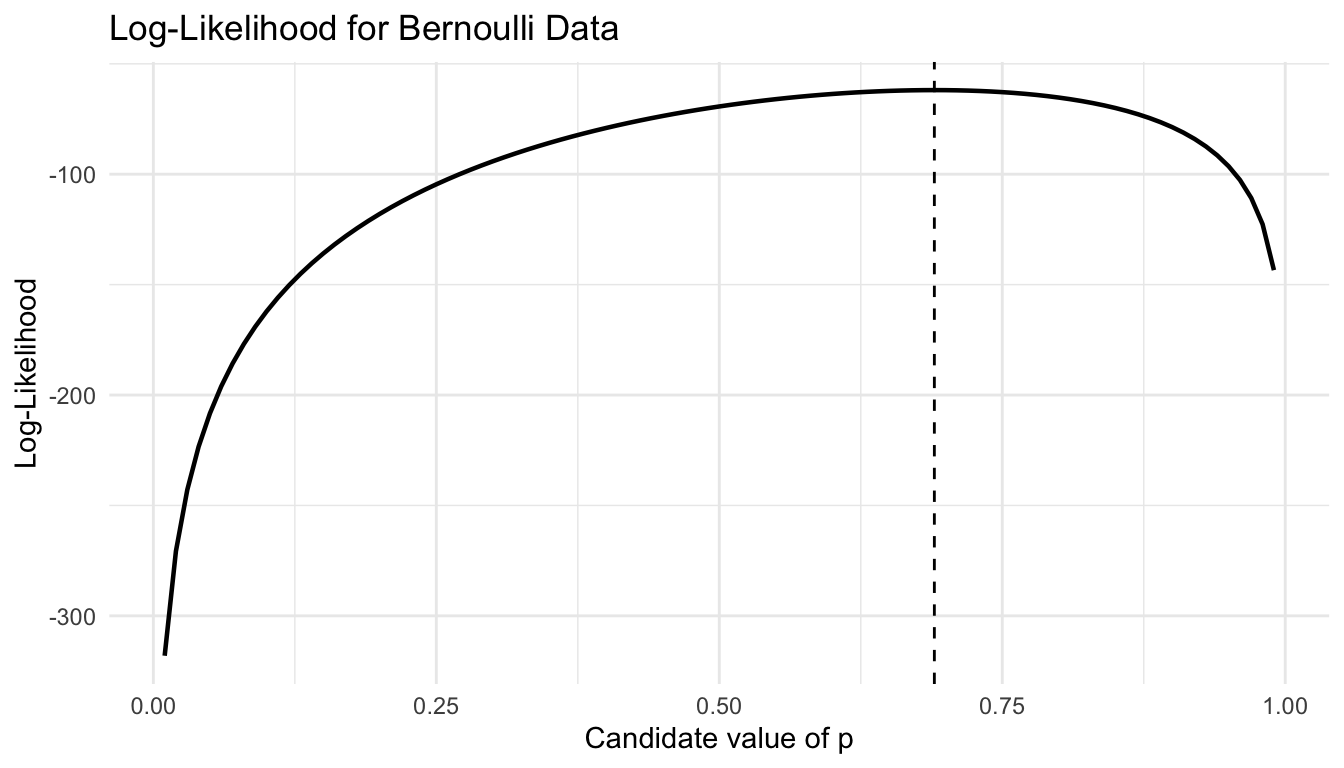
A likelihood function is not a probability distribution over the parameter in the classical sense. It is a function of the parameter, indexed by the observed data.
The parameters are estimated by maximizing the Bernoulli likelihood across all observations.
That means logistic regression is fundamentally an MLE problem.
The same general logic extends to:
multinomial regression,
Poisson regression,
Gaussian models,
and many latent-variable models.
In other words, MLE is not a niche statistical trick. It is one of the engines of predictive modeling.
MLE Connects Naturally to Loss Functions in ML
Machine learning practitioners often think in terms of minimizing loss, not maximizing likelihood.
But the two are often equivalent.
For many probabilistic models:
maximizing the log-likelihood
is the same as minimizing the negative log-likelihood
This is why so many ML training objectives look like:
cross-entropy loss,
log loss,
negative log-likelihood,
deviance.
They are all variations on the same principle.
That is one of the reasons MLE is such an important bridge between classical inference and modern ML training.
The EM Algorithm Extends MLE to Incomplete or Latent Data Settings
MLE becomes more complicated when the data are incomplete or when the model contains latent variables.
That is where the Expectation-Maximization (EM) algorithm becomes useful.
The EM idea is:
E-step: compute expected sufficient quantities given current parameter values,
M-step: maximize the expected complete-data log-likelihood.
This appears in settings such as:
Gaussian mixture models,
latent class models,
missing-data problems,
clustering and unsupervised learning.
You do not need the full EM derivation to appreciate the connection: it is still an MLE problem, but solved iteratively when direct optimization is harder.
MLE Has Strengths, but It Also Has Assumptions
MLE is powerful, but it is not assumption-free.
Its quality depends on:
whether the model family is sensible,
whether observations are appropriately modeled,
whether independence assumptions are reasonable,
whether the optimizer behaves well,
and whether the likelihood surface is well behaved.
A beautifully optimized likelihood under the wrong model can still produce misleading answers.
This is an important lesson in both biostatistics and AI.
Optimization is not the same as truth. It is only as good as the model being optimized.
A Small Regression-Style Example Using Negative Log-Likelihood
To make the ML connection even more explicit, here is a simple binary outcome example with a custom Bernoulli negative log-likelihood for an intercept-only model.
even a simple classifier can be understood as a likelihood optimization problem.
That is the core MLE idea appearing in ML language.
A Practical Checklist for Applied Work
Before using or reporting an MLE-based fit, ask:
What probability model am I assuming for the data?
What is the likelihood function?
Do I have a closed-form estimator or do I need optimization?
Does the estimate make sense relative to the data?
How sensitive is the result to assumptions or starting values?
Would method of moments give a similar answer?
Am I optimizing a sensible model, or only optimizing efficiently?
These questions usually improve both understanding and interpretation.
NoteWhere This Shows Up in AI/ML
Cross-entropy loss — the objective function used to train virtually every neural network classifier, including clinical NLP models that extract injury severity from trauma notes and sepsis prediction models that consume EHR time series — is the negative log-likelihood under a Bernoulli or categorical distribution, making MLE the literal mechanism by which these models learn from data. When the training data is class-imbalanced (as it always is in trauma: severe TBI is rare even in the DoDTR), the MLE objective is dominated by the majority class and the resulting model is optimized to predict “no severe outcome” almost always — a failure that emerges directly from what MLE maximizes and can only be fixed by modifying the likelihood (weighted loss, focal loss) or the sampling strategy.
Closing: MLE Is One of the Main Languages Shared by Statistics and ML
Maximum likelihood estimation is powerful because it gives a general recipe for learning from data.
It says:
define a probability model,
quantify how plausible the observed data are under candidate parameters,
and choose the parameter values that maximize that plausibility.
That logic is elegant enough for theory and practical enough for real model training.
It appears in:
Bernoulli models,
normal models,
logistic regression,
count models,
and iterative procedures like EM.
MLE matters because it turns model fitting into a coherent, general-purpose optimization problem — one that sits at the heart of both statistical inference and machine learning.
This post is part of the Bayesian Workflow Toolkit — a companion reference with likelihood specification templates, MLE-to-Bayesian bridge examples, and numerical optimization scaffolds.
Casella, George, and Roger L. Berger. 2002. Statistical Inference. 2nd ed. Duxbury.
DeGroot, Morris H., and Mark J. Schervish. 2012. Probability and Statistics. 4th ed. Pearson.
Fisher, Ronald A. 1922. “On the Mathematical Foundations of Theoretical Statistics.”Philosophical Transactions of the Royal Society of London. Series A 222 (594–604): 309–68. https://doi.org/10.1098/rsta.1922.0009.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. Springer.
Murphy, Kevin P. 2012. Machine Learning: A Probabilistic Perspective. MIT Press.