Bayesian Thinking: From Biostats Priors to Smarter AI
Applied Statistics
Bayesian Inference
An applied introduction to Bayesian inference, priors, posteriors, conjugacy, credible intervals, and Bayesian updating for AI and clinical decision-making.
How should we update what we believe after observing new evidence?
That question matters across biostatistics, clinical reasoning, and machine learning.
In classical frequentist workflows, parameters are usually treated as fixed and unknown. In Bayesian inference, parameters are treated as uncertain quantities, and probability is used to represent that uncertainty directly.
\(P(y)\) is the normalizing constant, often called the marginal likelihood or evidence
In words:
posterior is proportional to likelihood times prior.
That proportionality is the central Bayesian move.
It says the updated belief about the parameter comes from combining:
what we believed before,
with how compatible the observed data are with each parameter value.
Priors Are Not a Flaw — They Are Part of the Model
One reason Bayesian methods are sometimes resisted is discomfort with priors.
But every analysis has assumptions. Bayesian inference simply requires them to be made visible.
A prior distribution reflects information, structure, or constraints before seeing the current dataset.
Priors can be:
informative, when previous knowledge is substantial
weakly informative, when we want regularization without strong claims
diffuse or vague, when we want the data to dominate more strongly
In practice, priors can encode:
historical studies,
biological plausibility,
reasonable parameter ranges,
or skepticism about extreme effects.
The key question is not whether assumptions exist. It is whether they are stated clearly and chosen responsibly.
The Posterior Is the Real Bayesian Object of Interest
The posterior distribution is what makes Bayesian inference especially appealing.
Instead of giving only a point estimate, the posterior gives a full distribution over plausible parameter values after observing the data.
That allows us to answer questions like:
what values of the treatment effect are plausible?
what is the probability the response rate exceeds 0.6?
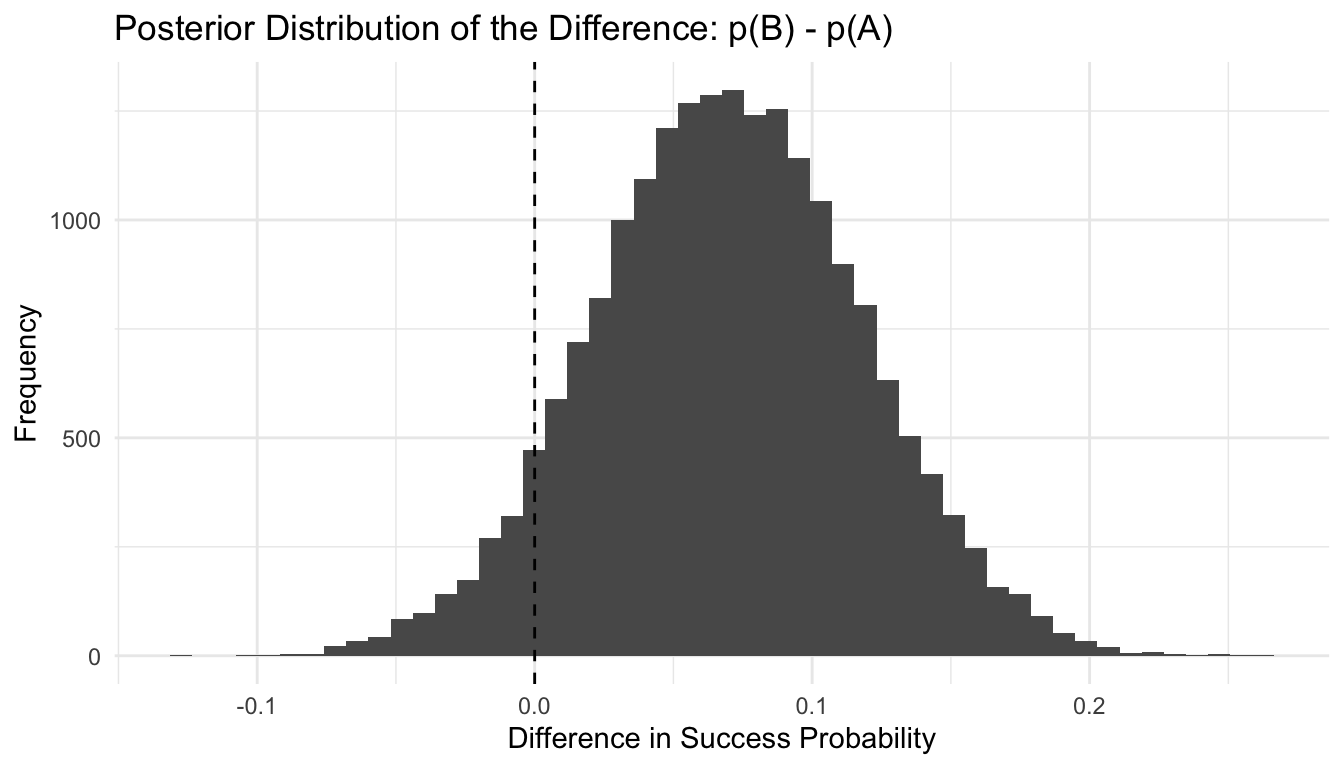
what is the probability model A is better than model B?
how uncertain are we about a slope, risk difference, or calibration parameter?
This is often more aligned with how scientists and decision-makers actually think.
They usually care less about a hypothetical repeated-sampling procedure and more about what the current data imply now.
A Medical Diagnosis Framing Makes the Logic Intuitive
A classic way to understand Bayesian thinking is through diagnosis.
Suppose a disease is rare. Even a good test can produce many false positives if the prior prevalence is low.
That means:
the test result alone is not enough,
and the prior probability of disease matters.
This is one of the places where Bayesian thinking is especially natural.
A positive test updates belief. It does not create belief from nothing.
That is also why Bayesian reasoning is so important in clinical decision-making and AI systems that operate in low-prevalence, high-uncertainty environments.
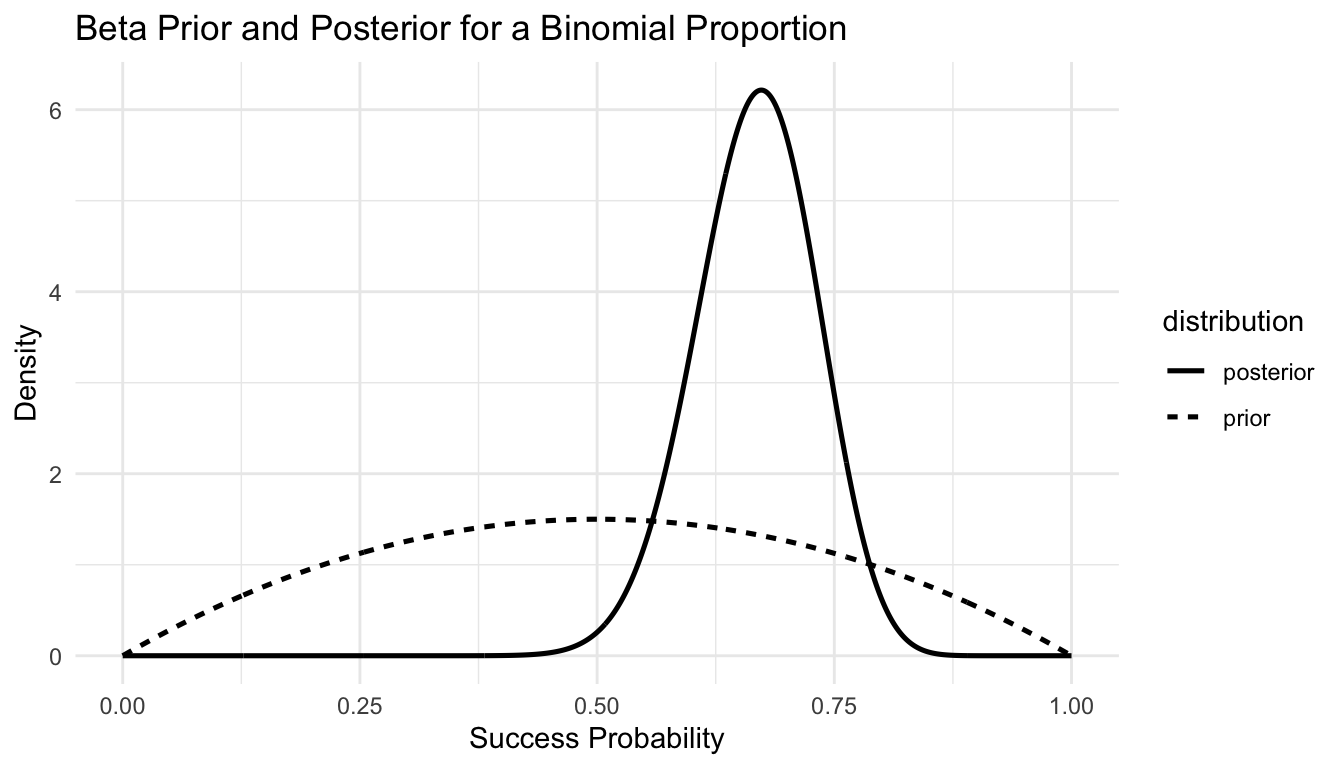
A Simple Beta-Binomial Example Shows Analytic Updating
One of the nicest Bayesian teaching examples is the Beta-Binomial model.
Suppose (y) successes are observed out of (n) trials, and the success probability is (p).
The likelihood is Binomial:
\[
y \mid p \sim \text{Binomial}(n, p)
\]
Choose a Beta prior:
\[
p \sim \text{Beta}(\alpha, \beta)
\]
Then the posterior is also Beta:
\[
p \mid y \sim \text{Beta}(\alpha + y, \beta + n - y)
\]
This is called conjugacy.
The prior and posterior belong to the same family, which makes updating analytically simple.
This is a natural bridge from conjugate examples into full posterior computation.
Bayesian Thinking Also Matters in Modern AI/ML
Bayesian ideas extend far beyond classical data analysis.
They power or influence:
Bayesian optimization,
probabilistic deep learning,
variational inference,
uncertainty-aware prediction,
Gaussian processes,
and regularized small-data modeling.
Even when a method is not fully Bayesian, Bayesian thinking often shapes how uncertainty and prior structure are handled.
This matters because many AI systems still struggle with overconfidence.
Bayesian approaches are one route toward making predictive systems more honest about uncertainty.
Bayesian Inference Is Powerful, but Not Automatic
Bayesian methods are powerful, but they still require judgment.
Important considerations include:
prior choice,
model specification,
likelihood adequacy,
posterior sensitivity,
and computational diagnostics.
A Bayesian model can still be misleading if:
the prior is poorly chosen,
the likelihood is unrealistic,
or the computation has not converged properly.
So Bayesian inference should not be treated as a magic upgrade. It is a principled framework, but still one that depends on careful modeling.
A Practical Checklist for Applied Work
Before using or reporting a Bayesian analysis, ask:
What prior did I choose, and why?
Is the prior weakly informative, informative, or diffuse?
What is the likelihood model?
Is the posterior available analytically, or do I need MCMC?
How sensitive are the conclusions to the prior?
Would a frequentist summary tell a materially different story?
Is the Bayesian output more aligned with the real decision I need to make?
These questions often improve both transparency and interpretation.
NoteWhere This Shows Up in AI/ML
Bayesian neural networks — used in systems like the UK’s ACHD cardiac risk tool and in research trauma triage models — replace point-weight estimates with posterior distributions over weights, enabling the model to output a posterior predictive distribution for each patient rather than a single probability score; this means the model can communicate “I’m confident this patient is high-risk” versus “this patient’s risk is genuinely uncertain and you should not rely on this score alone.” When a trauma outcome model is deployed to a new operational environment (say, moving from CONUS hospital data to deployed DoDTR cases) without updating the prior, the posterior predictive distribution will be miscalibrated in proportion to how far the new population sits from the training population — a failure that Bayesian framing makes explicit and that purely frequentist models hide entirely.
Closing: Bayesian Inference Makes Uncertainty Explicit
Bayesian inference remains compelling because it treats learning as updating.
It gives a coherent structure for combining prior knowledge with observed data. It yields full posterior distributions rather than only point estimates. And it often speaks more directly to the real questions analysts and decision-makers want answered.
That is true in:
medical diagnosis,
A/B testing,
small-sample biostatistics,
and modern AI systems that need better uncertainty handling.
Bayesian inference matters because it turns uncertainty from an inconvenience into a first-class part of the model.
This post is part of the Bayesian Workflow Toolkit — a companion reference with prior justification templates, posterior predictive check code, credible interval reporting, and audit-ready Bayesian workflow scaffolds.
Bayes, Thomas, and Richard Price. 1763. “An Essay Towards Solving a Problem in the Doctrine of Chances.”Philosophical Transactions of the Royal Society of London 53: 370–418. https://doi.org/10.1098/rstl.1763.0053.
Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis. 3rd ed. Chapman; Hall/CRC.
Kruschke, John K. 2015. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan. 2nd ed. Academic Press.
McElreath, Richard. 2020. Statistical Rethinking: A Bayesian Course with Examples in R and Stan. 2nd ed. CRC Press. https://doi.org/10.1201/9780429029608.
Morey, Richard D., Rink Hoekstra, Jeffrey N. Rouder, Michael D. Lee, and Eric-Jan Wagenmakers. 2016. “The Fallacy of Placing Confidence in Confidence Intervals.”Psychonomic Bulletin & Review 23 (1): 103–23. https://doi.org/10.3758/s13423-015-0947-8.