fit_logit <-glm( event ~ age + severity,data = logit_df,family =binomial())summary(fit_logit)
Call:
glm(formula = event ~ age + severity, family = binomial(), data = logit_df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.62678 0.97782 -6.777 1.23e-11 ***
age 0.05255 0.01187 4.427 9.56e-06 ***
severity 0.40365 0.05745 7.026 2.12e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 413.63 on 299 degrees of freedom
Residual deviance: 329.28 on 297 degrees of freedom
AIC: 335.28
Number of Fisher Scoring iterations: 4
This output provides:
regression coefficients on the log-odds scale,
standard errors,
z-statistics,
and p-values.
But interpreting coefficients directly on the log-odds scale can feel abstract.
That is why odds ratios are often used.
Coefficients Are Interpreted Through Odds Ratios
Each logistic regression coefficient represents the expected change in the log-odds of the outcome per one-unit increase in the predictor, holding other predictors constant.
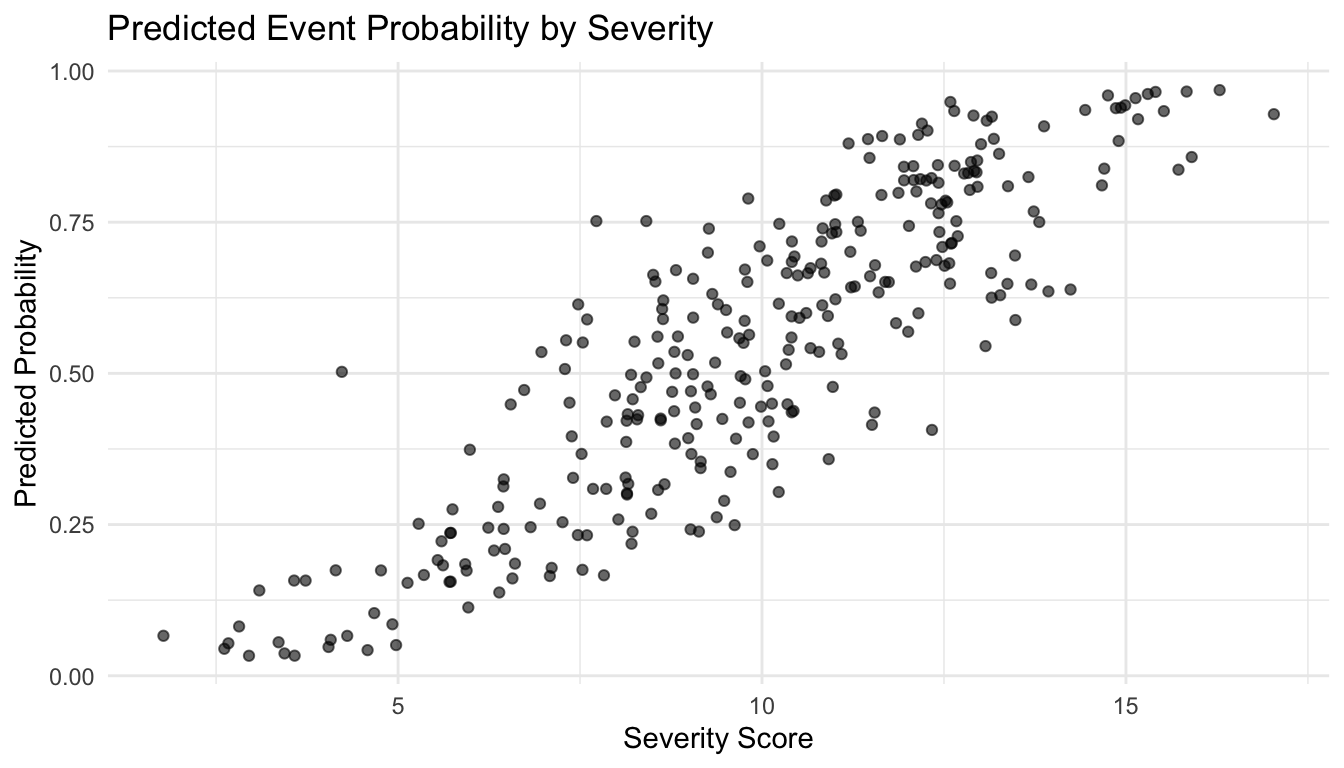
We can also visualize how predicted probability changes with severity while holding age roughly constant through a simple plot.
ggplot2::ggplot(logit_df, ggplot2::aes(x = severity, y = pred_prob)) + ggplot2::geom_point(alpha =0.6) + ggplot2::labs(title ="Predicted Event Probability by Severity",x ="Severity Score",y ="Predicted Probability" ) + ggplot2::theme_minimal()
This helps connect model coefficients to clinical or operational risk.
Logistic Regression Is Trained by Maximum Likelihood
Logistic regression is not fit by ordinary least squares.
It is estimated by maximum likelihood.
That is important because it links logistic regression directly to the broader ML idea of optimizing an objective function (Murphy 2012; Hastie et al. 2009).
The model parameters are chosen to maximize the likelihood of the observed binary outcomes under the Bernoulli model.
Equivalently, many ML workflows describe this as minimizing log loss or cross-entropy loss.
That is one reason logistic regression is such an important bridge between statistical modeling and machine learning.
Classification Requires a Threshold, Not Just a Probability Model
A logistic regression model outputs probabilities. To turn those into class labels, we need a threshold.
A common default is 0.50:
predict 1 if predicted probability >= 0.50
predict 0 otherwise
But that threshold is not always optimal.
In clinical or operational settings, the best threshold depends on:
class imbalance,
false positive cost,
false negative cost,
and decision context.
We can start with a 0.50 threshold to illustrate classification.
This is a natural bridge from classical logistic regression into modern ML practice.
Logistic Regression Remains a Strong Baseline Classifier
In AI/ML, logistic regression is often used as a baseline model.
That is not because it is primitive. It is because it is:
interpretable,
fast,
probabilistic,
and surprisingly strong in many structured-data problems.
If a much more complex model cannot clearly outperform a logistic baseline, that is meaningful.
This is one reason logistic regression remains central in applied classification work, even in the era of deep learning.
Logistic Regression Also Generalizes Beyond Binary Outcomes
The importance of logistic regression extends further than yes/no classification.
It connects naturally to:
multinomial logistic regression for multi-class outcomes,
ordinal logistic models,
softmax classifiers in NLP and deep learning,
and output layers in neural network architectures.
So even when the specific model changes, the core idea remains familiar:
model class probabilities,
connect predictors through a link,
optimize a probabilistic loss.
That is why logistic regression is such a durable conceptual anchor.
A Practical Checklist for Applied Work
Before reporting or deploying a logistic regression model, ask:
Is the outcome truly binary and clearly defined?
Are the coefficients being interpreted on the correct scale?
Would predicted probabilities be more useful than odds ratios?
Is the threshold appropriate for the decision context?
Have I examined confusion-matrix behavior, not just coefficients?
Have I assessed ROC/AUC with appropriate restraint?
Is regularization needed because of predictor count or collinearity?
Am I using logistic regression as a baseline, an explanatory model, or both?
These questions often matter more than whether the model “ran successfully.”
NoteWhere This Shows Up in AI/ML
The Epic Deterioration Index is a logistic regression model at its core: it outputs a probability that a patient will deteriorate within 24 hours, trained on EHR vitals, labs, and nursing flowsheet data. The threshold selection problem is where this gets clinically consequential — in military trauma triage, a threshold tuned to minimize false negatives in a Level I trauma center may flood a far-forward surgical team with low-acuity alerts, degrading trust and causing alert fatigue. AUC alone is insufficient here: a model with AUC of 0.82 can still be operationally useless if its calibration is poor or its sensitivity at the operationally relevant threshold is unacceptable. Models deployed in TCCC or en route care contexts must be validated against the specific threshold performance the operational scenario demands, not just ranked discrimination.
Closing: Logistic Regression Still Teaches the Core Logic of Classification
Logistic regression remains one of the best ways to learn binary classification properly.
It shows how to:
model probabilities,
connect predictors to risk,
interpret coefficients conditionally,
evaluate threshold-based decisions,
and stabilize models through regularization.
It is useful in biostatistics because it is interpretable and principled. It is useful in machine learning because it is a core classifier and a gateway to broader predictive systems.
Logistic regression endures because it is simple enough to understand clearly, yet rich enough to teach the essential logic of classification in modern analytics.
This post is part of the Prediction Modeling Toolkit — a companion reference with logistic regression templates, calibration plots, ROC curve code, and clinical prediction model reporting scaffolds.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. Springer.
Hosmer, David W., Stanley Lemeshow, and Rodney X. Sturdivant. 2013. Applied Logistic Regression. 3rd ed. Wiley.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer.
McCullagh, Peter, and John A. Nelder. 1989. Generalized Linear Models. 2nd ed. Chapman; Hall.
Murphy, Kevin P. 2012. Machine Learning: A Probabilistic Perspective. MIT Press.
Steyerberg, Ewout W. 2019. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. 2nd ed. Springer.