PCA reduces dimensionality by finding new variables — called principal components — that capture as much variation in the data as possible using fewer dimensions.
This makes PCA useful for:
exploratory data analysis,
preprocessing,
visualization,
noise reduction,
and feature compression before modeling.
This post introduces:
eigenvalues and eigenvectors,
principal components,
loadings and scores,
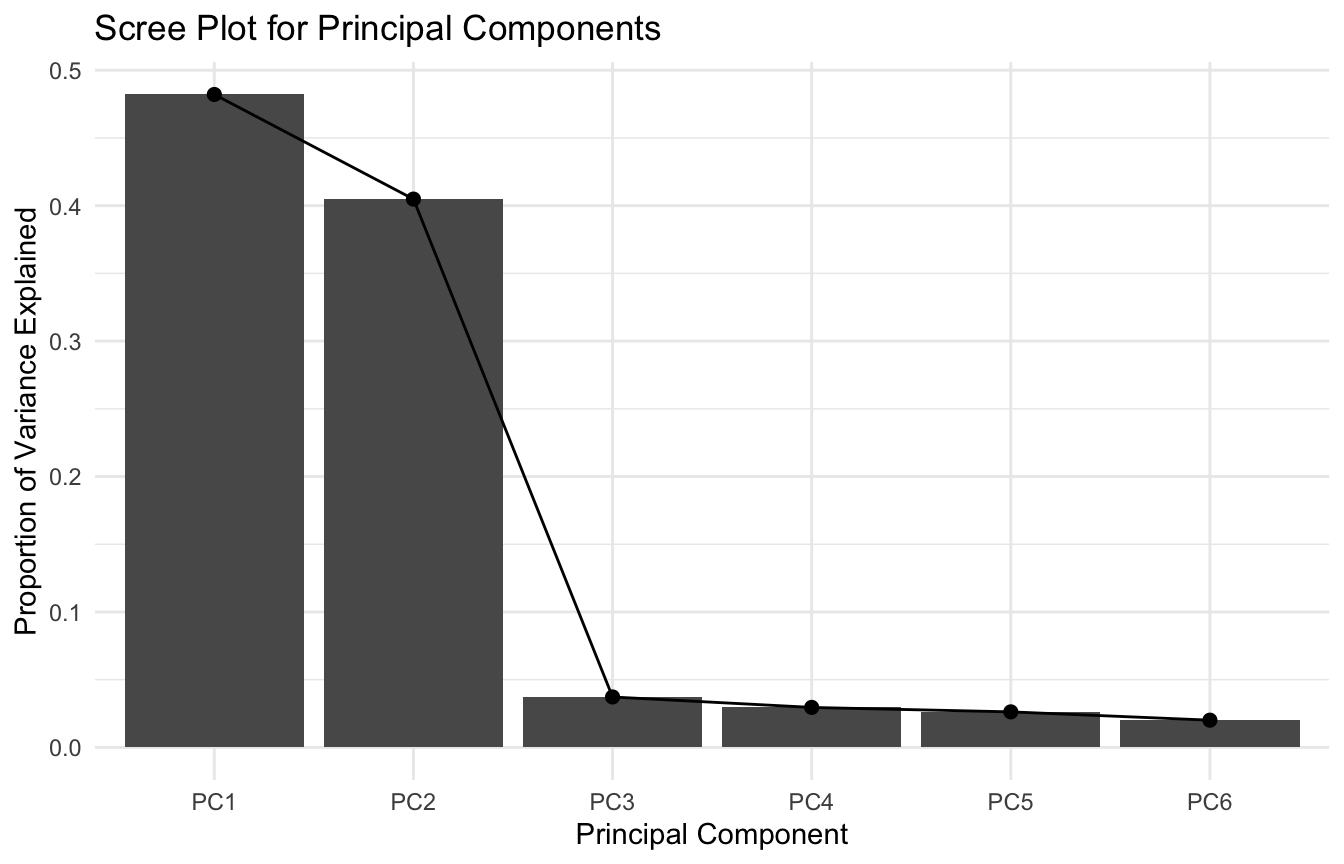
scree plots,
and interpretation in a genomics-style setting.
PCA matters because many datasets contain more dimensions than real signal, and shrinking the data intelligently can make both analysis and modeling clearer.
PCA Starts with a Practical Problem: Too Many Variables
Many datasets include variables that overlap heavily in the information they contain.
For example, in genomics, multiple gene-expression features may move together because they reflect shared pathways, common regulatory programs, or correlated measurement structure.
In those settings, using every variable directly can be inefficient.
Problems include:
redundancy,
instability,
overfitting risk,
and difficulty visualizing patterns.
PCA addresses this by constructing a smaller set of derived variables that summarize the major directions of variation in the data (Hotelling 1933; Jolliffe 2002).
That is why PCA is often one of the first tools analysts reach for in high-dimensional exploratory work.
PCA Finds New Axes That Capture Variation Efficiently
The key idea of PCA is simple:
instead of analyzing the original variables directly, find new orthogonal directions that capture as much variation as possible.
These new directions are the principal components.
The first principal component captures the greatest possible variance. The second captures the greatest remaining variance subject to being orthogonal to the first. The third captures the next greatest remaining variance, and so on.
This means PCA does not merely drop variables. It re-expresses the data in a more efficient coordinate system.
That is one reason PCA is so powerful.
It compresses information without necessarily discarding all structure.
Eigenvalues and Eigenvectors Provide the Mathematics Behind PCA
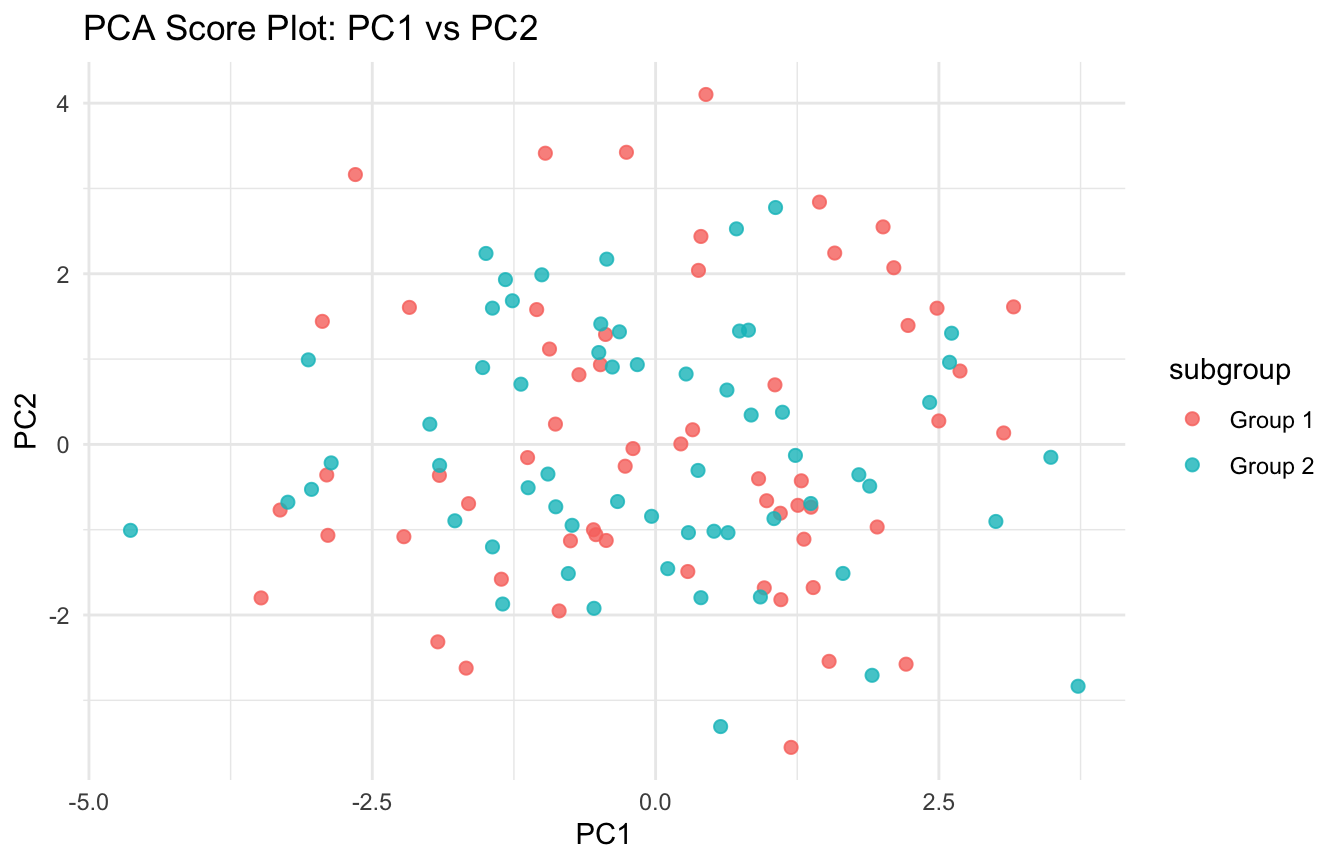
ggplot2::ggplot(plot_df, ggplot2::aes(x = PC1, y = PC2, color = subgroup)) + ggplot2::geom_point(size =2, alpha =0.8) + ggplot2::labs(title ="PCA Score Plot: PC1 vs PC2",x ="PC1",y ="PC2" ) + ggplot2::theme_minimal()
This plot can reveal:
clustering
separation
outliers
or gradients across samples
That is one reason PCA is so widely used in genomics, omics, and other high-dimensional exploratory workflows.
PCA Is a Dimension Reduction Method, Not a Supervised Model
One of the most important conceptual boundaries is that PCA is unsupervised.
It does not use the outcome variable when constructing components.
That means PCA finds directions of maximal variation, not directions of maximal prediction.
This distinction matters.
A component that explains a lot of variance is not automatically the most predictive of a downstream outcome.
So PCA is often useful for preprocessing or exploration, but not every principal component will necessarily improve predictive performance.
This is an important caution in AI/ML workflows.
PCA Can Help with Speed, Noise Reduction, and Multicollinearity
Despite its limits, PCA is often very useful in practice.
Benefits include:
reducing the number of input dimensions
compressing correlated variables
mitigating multicollinearity
improving computational efficiency
denoising feature space
These benefits are especially relevant when:
predictors are highly correlated
there are more features than are easy to model directly
training time matters
visualization is otherwise impossible
This is why PCA often appears early in high-dimensional workflows.
PCA Loadings Need Interpretation, Not Just Computation
A common mistake is to run PCA, keep the first few components, and stop there.
But PCA only becomes scientifically useful when the components are interpreted thoughtfully.
Questions to ask include:
which variables load strongly on this component?
does the pattern suggest a biological or operational theme?
does the component reflect signal, batch structure, scale artifacts, or noise?
are positive and negative loadings substantively meaningful?
This is especially important in genomics and biomarker work, where latent structure may reflect real biology, but may also reflect preprocessing or measurement effects.
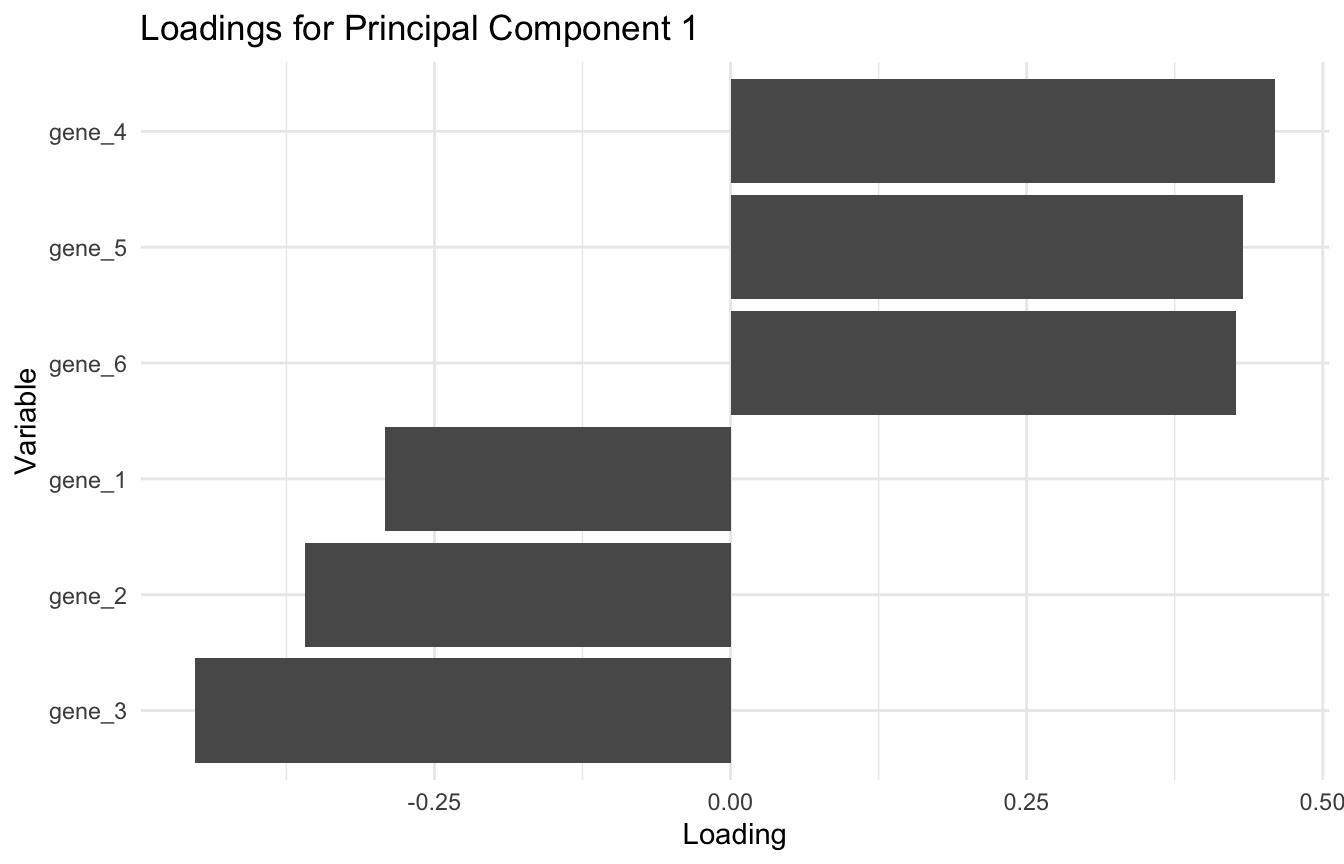
A Simple Loadings Plot Can Help with Interpretation
One helpful way to inspect loadings is with a bar chart.
pc1_loadings_df <- tibble::tibble(variable =rownames(pca_fit$rotation),loading = pca_fit$rotation[, 1])ggplot2::ggplot(pc1_loadings_df, ggplot2::aes(x =reorder(variable, loading), y = loading)) + ggplot2::geom_col() + ggplot2::coord_flip() + ggplot2::labs(title ="Loadings for Principal Component 1",x ="Variable",y ="Loading" ) + ggplot2::theme_minimal()
This helps identify the variables driving the first component and whether the component looks like a shared signal or a contrast between sets of variables.
PCA Connects Naturally to AI/ML Preprocessing
PCA remains important in AI/ML because it is one of the classic tools for reducing feature space before modeling.
Common uses include:
preprocessing before clustering
reducing predictors before regression or classification
improving runtime
reducing noise in correlated features
creating compact latent representations
Even though more advanced methods now exist, PCA still matters because it is:
fast
interpretable
stable
and easy to explain
That makes it a valuable baseline dimensionality reduction method.
PCA Is Also a Gateway to More Advanced Representation Learning
Conceptually, PCA is important because it introduces the broader idea of representation learning.
Instead of working directly with raw variables, we learn a transformed representation of the data.
This connects naturally to later topics such as:
factor analysis
singular value decomposition
manifold learning
t-SNE and UMAP
autoencoders
latent embedding methods
PCA is simpler than these methods, but it teaches the central logic clearly:
find a lower-dimensional representation that preserves useful structure.
That is one reason it remains such an important teaching tool.
PCA Has Limits and Should Not Be Overinterpreted
PCA is useful, but it is not magic.
Important limitations include:
components may be hard to interpret
variance is not the same as predictive importance
PCA is sensitive to scaling choices
strong outliers can distort components
linear components may miss nonlinear structure
This means PCA should be used thoughtfully.
It is a powerful exploratory and preprocessing tool, but not always the final modeling answer.
In some problems, nonlinear manifold methods or supervised dimension reduction may be more appropriate.
A Practical Checklist for Applied Work
Before using PCA, ask:
Are the variables on comparable scales, or do they need standardization?
Is the goal visualization, denoising, compression, or preprocessing?
How much variance do the first few components actually explain?
Are the component loadings interpretable?
Could batch effects or outliers be driving the dominant components?
Does the reduced representation preserve structure that matters for the downstream task?
Am I mistaking high variance for predictive relevance?
These questions greatly improve how PCA is used and explained.
NoteWhere This Shows Up in AI/ML
In EHR-based clinical risk modeling, PCA is routinely used to compress correlated lab values — sodium, chloride, and bicarbonate rarely carry independent predictive signal — before fitting logistic or Cox models, reducing effective dimensionality and multicollinearity simultaneously. The word embeddings in large language models like GPT-4 are a learned, nonlinear generalization of exactly this idea: high-dimensional token co-occurrence space is compressed into a dense lower-dimensional representation that preserves semantic structure. The failure mode comes from skipping PCA when it matters: in DoDTR injury-severity feature sets with 40+ correlated anatomic and physiologic variables, analysts who feed all raw features directly into a logistic model often produce unstable coefficients and inflated variance estimates that make replication across deployment cohorts unreliable. PCA-derived components do not replace clinical interpretation — a component that explains 30% of variance may reflect a documentation artifact rather than a real injury phenotype.
Closing: PCA Makes High-Dimensional Data More Manageable
Principal Component Analysis remains important because it provides one of the clearest and most practical ways to reduce dimensionality.
It helps analysts:
summarize correlated variables
visualize large feature spaces
reduce noise
and build more efficient preprocessing pipelines
It also teaches deeper ideas about representation, variance, and latent structure that carry forward into more advanced AI/ML methods.
PCA matters because not every variable deserves its own dimension, and learning how to compress data without losing too much structure is one of the core skills of modern analytics.
This post is part of the Prediction Modeling Toolkit — a companion reference with PCA pre-processing templates, scree plot diagnostics, and dimensionality reduction scaffolds for clinical prediction models.
Hotelling, Harold. 1933. “Analysis of a Complex of Statistical Variables into Principal Components.”Journal of Educational Psychology 24 (6): 417–41.
Jolliffe, Ian T. 2002. Principal Component Analysis. 2nd ed. Springer.
Pearson, Karl. 1901. “On Lines and Planes of Closest Fit to Systems of Points in Space.”The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 2 (11): 559–72. https://doi.org/10.1080/14786440109462720.