Clustering Secrets: Grouping Data Like a Pro in ML
Applied Statistics
Clustering
An applied introduction to clustering, K-means, hierarchical clustering, silhouette scores, and subgroup discovery in unsupervised learning.
Published
June 15, 2024
Modified
June 9, 2026
Executive Summary
Many datasets do not arrive with clear labels.
Instead of knowing ahead of time who belongs to which group, analysts are often confronted with a harder question:
Are there natural groupings hidden in the data?
That is the central problem of clustering.
Cluster analysis is one of the core tools of unsupervised learning (MacQueen 1967; Ward 1963; Hastie et al. 2009). It helps identify observations that look similar to one another and different from the rest.
In practice, clustering can be used for:
patient phenotyping,
customer segmentation,
anomaly exploration,
subgroup discovery,
and feature engineering before supervised modeling.
This matters in both biostatistics and AI/ML.
In biostatistics, clustering can reveal clinically meaningful patient profiles. In machine learning, clustering can support exploratory analysis, representation learning, and preprocessing for later predictive tasks.
This post introduces:
K-means clustering,
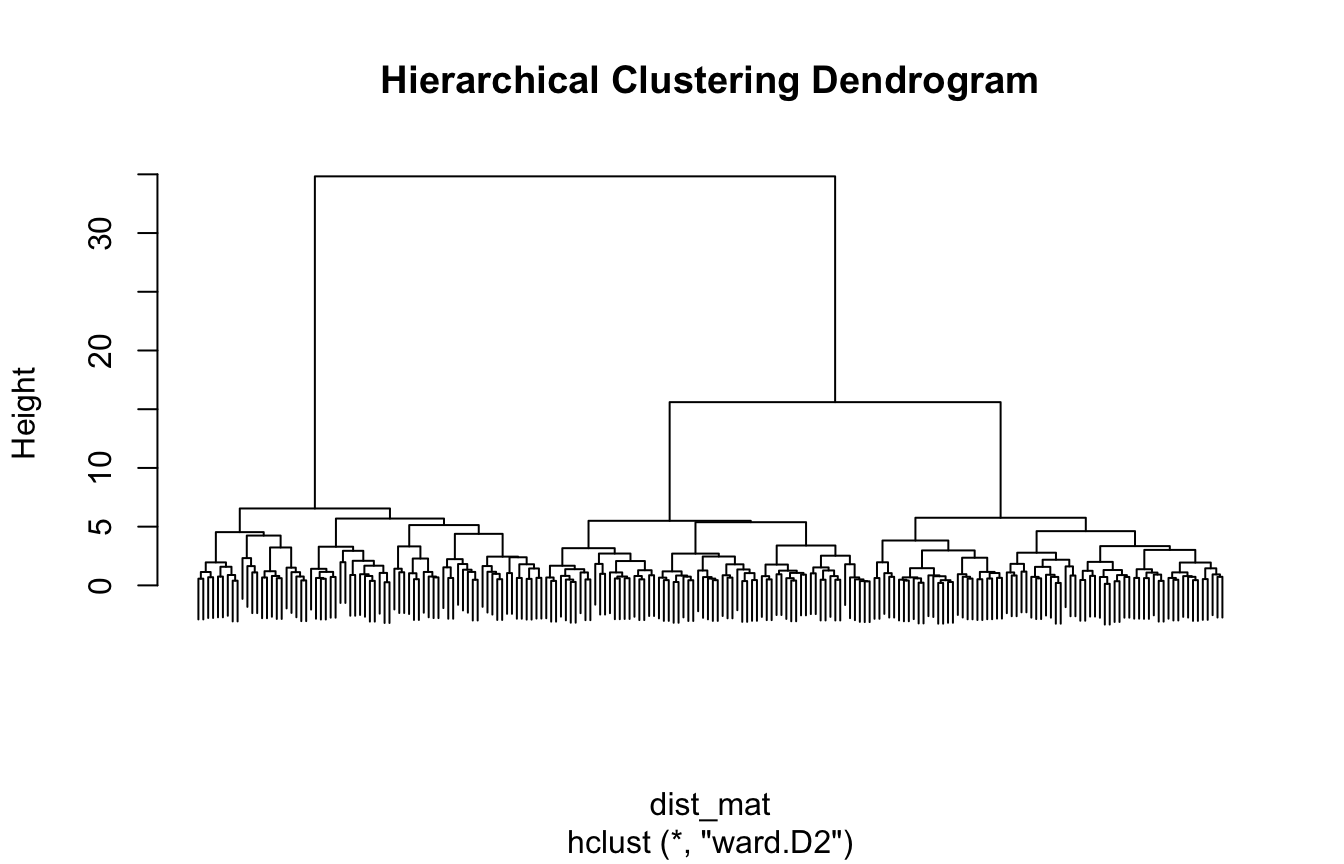
hierarchical clustering,
choosing the number of clusters,
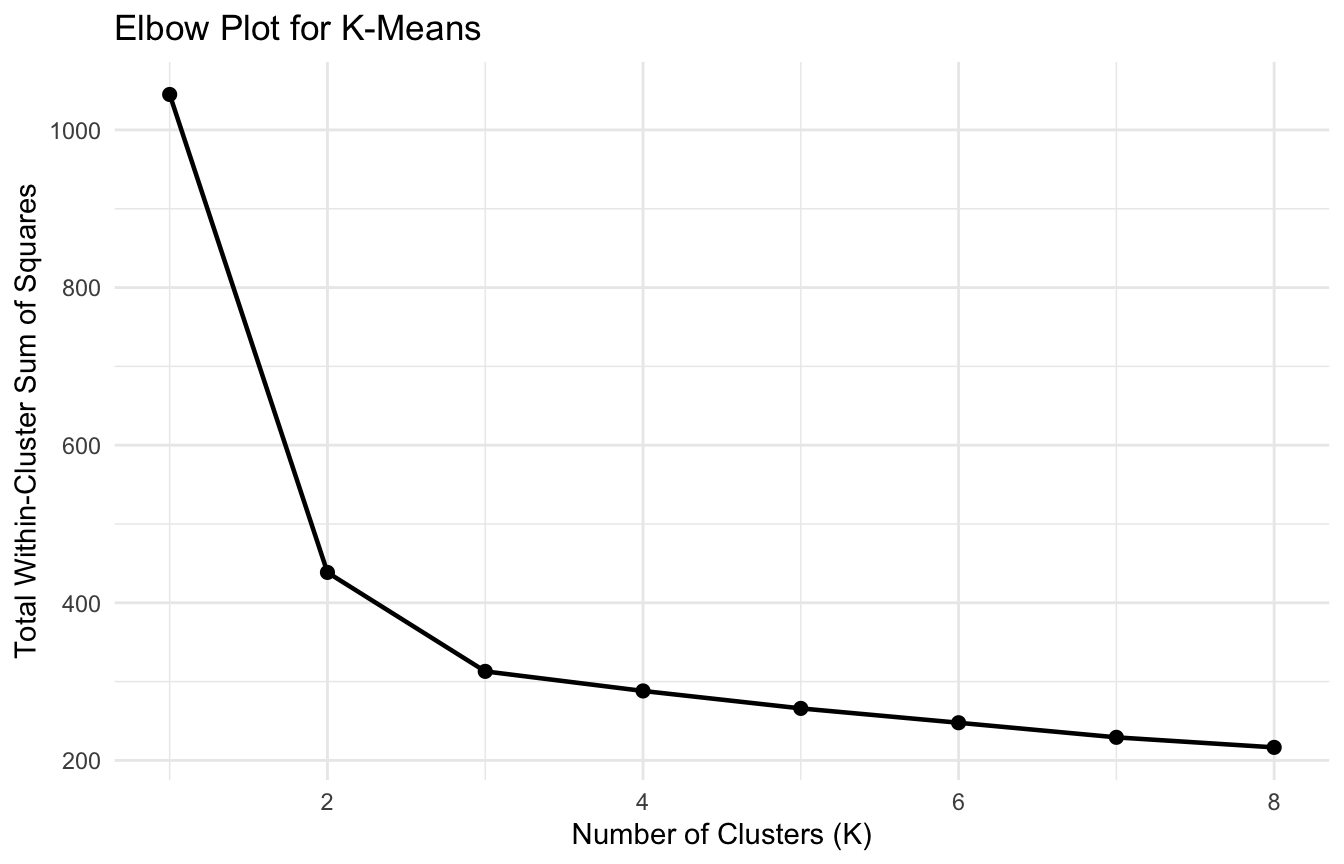
elbow plots,
silhouette scores,
and interpretation using a biostats-style patient-profile dataset.
Clustering matters because not every important pattern comes with a label, and learning to detect structure without supervision is one of the most useful skills in applied analytics.
Clustering Is About Discovering Structure Without Outcomes
Unlike regression or classification, clustering does not start with a known target variable.
There is no outcome to predict.
Instead, clustering asks whether the observations themselves contain meaningful structure.
That makes clustering fundamentally unsupervised.
This is important because many real datasets contain heterogeneity that is not explicitly labeled.
Examples include:
subtypes of patients with different physiologic patterns,
operational workflows that behave differently across contexts,
hidden user groups in digital platforms,
or biologic profiles that reflect distinct latent states.
Clustering is often the first step toward discovering those patterns.
In many applied settings, clustering should be performed on centered and scaled variables unless there is a strong reason not to.
This is especially important in biostats-style patient profiling, where features often come from different physiologic scales.
A Patient-Profile Example Makes the Task Concrete
To illustrate clustering, we will simulate a small patient-profile dataset with several continuous variables.
The example is synthetic, but it reflects a realistic applied idea: patients may cluster into profiles based on physiology and severity-related patterns.
library(dplyr)library(tibble)library(ggplot2)n_per_group <-70cluster_df <- tibble::tibble(patient_id =1:(3* n_per_group),latent_group =rep(c("Profile A", "Profile B", "Profile C"), each = n_per_group),age =c(rnorm(n_per_group, mean =35, sd =6),rnorm(n_per_group, mean =60, sd =8),rnorm(n_per_group, mean =48, sd =7) ),heart_rate =c(rnorm(n_per_group, mean =88, sd =8),rnorm(n_per_group, mean =102, sd =10),rnorm(n_per_group, mean =76, sd =7) ),sbp =c(rnorm(n_per_group, mean =122, sd =10),rnorm(n_per_group, mean =98, sd =12),rnorm(n_per_group, mean =135, sd =9) ),lactate =c(rnorm(n_per_group, mean =1.8, sd =0.4),rnorm(n_per_group, mean =4.5, sd =0.8),rnorm(n_per_group, mean =2.6, sd =0.5) ),severity =c(rnorm(n_per_group, mean =8, sd =2),rnorm(n_per_group, mean =16, sd =3),rnorm(n_per_group, mean =11, sd =2) ))cluster_df |> dplyr::group_by(latent_group) |> dplyr::summarise( dplyr::across(c(age, heart_rate, sbp, lactate, severity), mean ),.groups ="drop" )
# A tibble: 3 × 6
latent_group age heart_rate sbp lactate severity
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Profile A 34.8 89.4 121. 1.79 7.79
2 Profile B 60.0 103. 94.9 4.51 16.0
3 Profile C 46.8 76.6 133. 2.65 11.5
In real analysis, the latent grouping would be unknown. Here it exists only so we can see whether the clustering recovers meaningful structure.
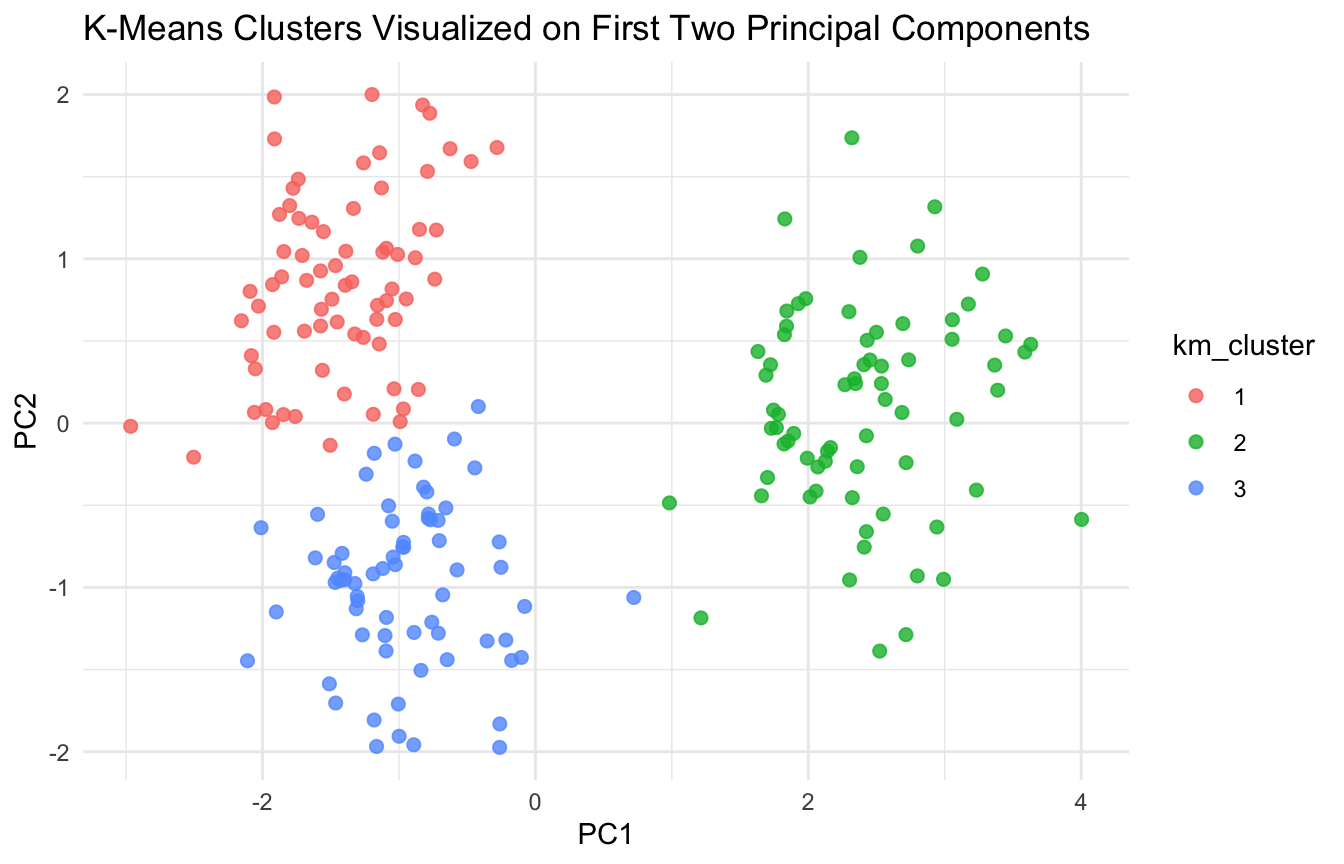
K-Means Clustering Partitions the Data Into K Groups
K-means is one of the most widely used clustering algorithms.
Its goal is simple:
partition the observations into (K) clusters so that observations within a cluster are as similar as possible, and observations across clusters are as different as possible.
K-means works by minimizing the within-cluster sum of squares.
That means it is trying to create compact clusters around cluster centroids.
Before fitting K-means, we standardize the features.
older, more severe, tachycardic, hypotensive, high lactate
That kind of profile interpretation is often the real analytic payoff.
Clustering Has Limits and Should Not Be Overclaimed
Clustering is useful, but it is easy to oversell.
Important cautions include:
not every dataset has meaningful clusters
clusters may be unstable across methods
apparent groups may reflect continuous gradients rather than true subtypes
high-dimensional noise can create misleading structure
cluster membership is not causal explanation
This means clustering outputs should usually be treated as hypotheses, profiles, or exploratory structures rather than final truths.
That is especially important in biomedical settings where subgroup labels may sound more definitive than the data justify.
A Practical Checklist for Applied Work
Before reporting a clustering analysis, ask:
Were the variables standardized appropriately?
Does the chosen distance metric make sense?
Why was K chosen the way it was?
Do elbow and silhouette diagnostics support the solution?
Are the clusters stable across methods or random starts?
Are the resulting groups clinically or operationally interpretable?
Could the structure reflect artifacts, missingness, or preprocessing choices?
Am I presenting clusters as exploratory profiles rather than fixed truths?
These questions usually improve both rigor and communication.
NoteWhere This Shows Up in AI/ML
Patient phenotyping pipelines in large EHR systems — including work done on OMOP-standardized data at major VA and DoD health systems — use k-means or hierarchical clustering to identify clinically distinct subpopulations before fitting subgroup-specific prediction models. In precision medicine oncology pipelines, clustering on genomic and proteomic features drives treatment stratification decisions that are downstream of unsupervised structure, not direct labels. The failure mode is cluster instability: when cluster assignments change substantially across algorithm runs, random seeds, or minor feature variations, any clinical protocol tied to those subgroups becomes operationally unreliable. In DoDTR phenotyping work, this manifests when an analyst reports “three physiologic injury profiles” that do not replicate in a validation cohort because the original cluster solution was driven by missingness patterns or site-level documentation differences rather than true biologic heterogeneity.
Closing: Clustering Helps Reveal Structure Before Labels Exist
Cluster analysis remains important because many real-world datasets contain latent structure that is not directly labeled.
K-means provides a fast and practical way to partition observations into compact groups. Hierarchical clustering provides a nested view of structure across resolutions. Diagnostics such as elbow plots and silhouette scores help guide the analysis. Interpretation turns the output into something useful.
In both biostatistics and AI/ML, clustering is valuable because it helps transform raw heterogeneity into candidate structure.
Clustering matters because some of the most interesting patterns in data are not pre-labeled, and good analysts need tools for discovering those patterns before prediction even begins.
This post is part of the Real-World Evidence Toolkit — a companion reference with patient phenotyping templates, cluster stability diagnostics, and clinical profile summary scaffolds.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. Springer.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer.
Kaufman, Leonard, and Peter J. Rousseeuw. 1990. Finding Groups in Data: An Introduction to Cluster Analysis. Wiley.
MacQueen, J. 1967. “Some Methods for Classification and Analysis of Multivariate Observations.”Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability 1: 281–97.
Ward, Joe H. 1963. “Hierarchical Grouping to Optimize an Objective Function.”Journal of the American Statistical Association 58 (301): 236–44. https://doi.org/10.1080/01621459.1963.10500845.