A practical introduction to Monte Carlo integration, importance sampling, and MCMC for uncertainty quantification, Bayesian inference, and AI.
Published
May 15, 2025
Modified
June 9, 2026
Executive Summary
Some of the most important questions in statistics and machine learning do not have neat closed-form answers.
For example:
what is the expected loss under a complicated posterior?
what is the uncertainty around a treatment effect in a hierarchical model?
how likely is a rare but high-cost event?
how do we approximate an integral in high dimensions when exact calculation is impossible?
This is where Monte Carlo methods become essential.
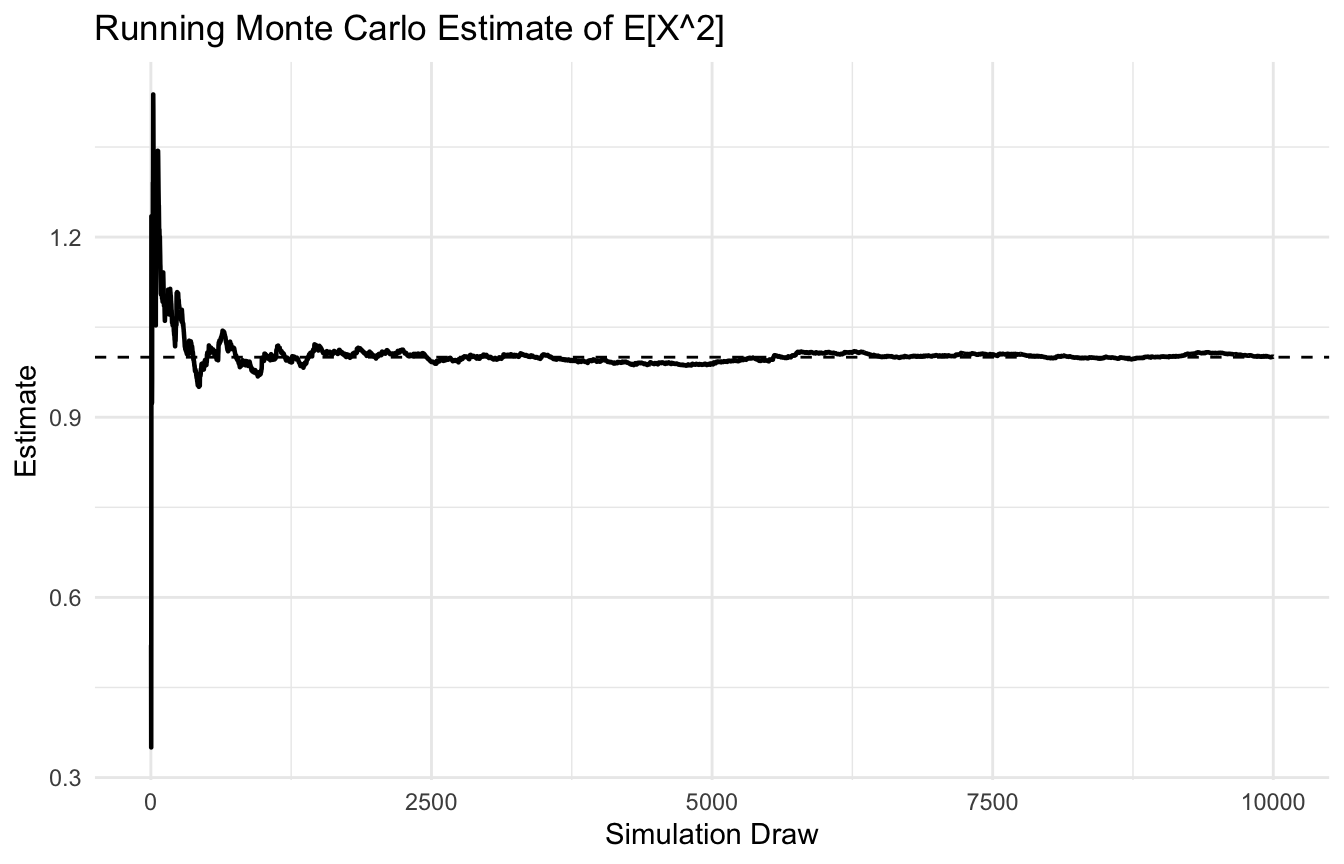
Monte Carlo methods use random sampling to approximate quantities that are difficult to compute analytically (Robert and Casella 2004; Owen 2013). They are especially useful for:
The weights correct for the fact that we sampled from the wrong distribution.
A Small Importance Sampling Example Shows the Logic
Suppose we want to estimate the mean of a standard normal target distribution using draws from a wider normal proposal.
This is not necessary here, but it illustrates the method.
n_sims <-10000x_prop <-rnorm(n_sims, mean =0, sd =2)target_density <-dnorm(x_prop, mean =0, sd =1)proposal_density <-dnorm(x_prop, mean =0, sd =2)weights <- target_density / proposal_densityis_estimate <-sum(x_prop * weights) /sum(weights)tibble::tibble(importance_sampling_estimate = is_estimate)
# A tibble: 1 × 1
importance_sampling_estimate
<dbl>
1 0.00371
Since the true mean is 0, the estimate should be close to 0.
The key lesson is not the specific result. It is the idea that weighted simulation can approximate quantities under a target distribution without direct target sampling.
Importance Sampling Can Work Very Well or Very Badly
Importance sampling is elegant, but it can become unstable when the proposal distribution is poorly chosen.
Problems arise when:
the proposal puts too little mass where the target is large
the weights become highly variable
a few samples dominate the estimate
This is one reason importance sampling can struggle in high dimensions.
A good proposal distribution should resemble the target reasonably well.
That is one of the main practical lessons: importance sampling is powerful, but sensitive to proposal design.
MCMC Solves a Different Sampling Problem
When direct sampling is hard and importance sampling becomes unstable, another strategy is to construct a Markov chain whose long-run distribution is the target distribution.
This is the idea of Markov chain Monte Carlo, or MCMC.
Instead of drawing independent samples directly from the target, MCMC builds a dependent sequence of samples that eventually behaves like draws from the target.
This is extremely useful in Bayesian inference, where posterior distributions are often known only up to a proportionality constant.
MCMC lets us sample from such distributions without needing full analytic normalization.
Markov Chains Introduce Dependence Across Draws
A Markov chain is a stochastic process where the next state depends only on the current state, not the full past history.
That means MCMC samples are usually not independent.
This is a major difference from ordinary Monte Carlo or importance sampling.
The dependence does not make MCMC invalid. But it does mean we have to think about:
convergence,
mixing,
autocorrelation,
and effective sample size.
These are central practical concerns in MCMC-based inference.
Metropolis-Hastings Is One of the Classic MCMC Algorithms
One of the foundational MCMC algorithms is Metropolis-Hastings.
Its logic is:
start at a current parameter value
propose a new value from a proposal distribution
compare how plausible the proposed value is relative to the current value
accept or reject the proposal based on an acceptance probability
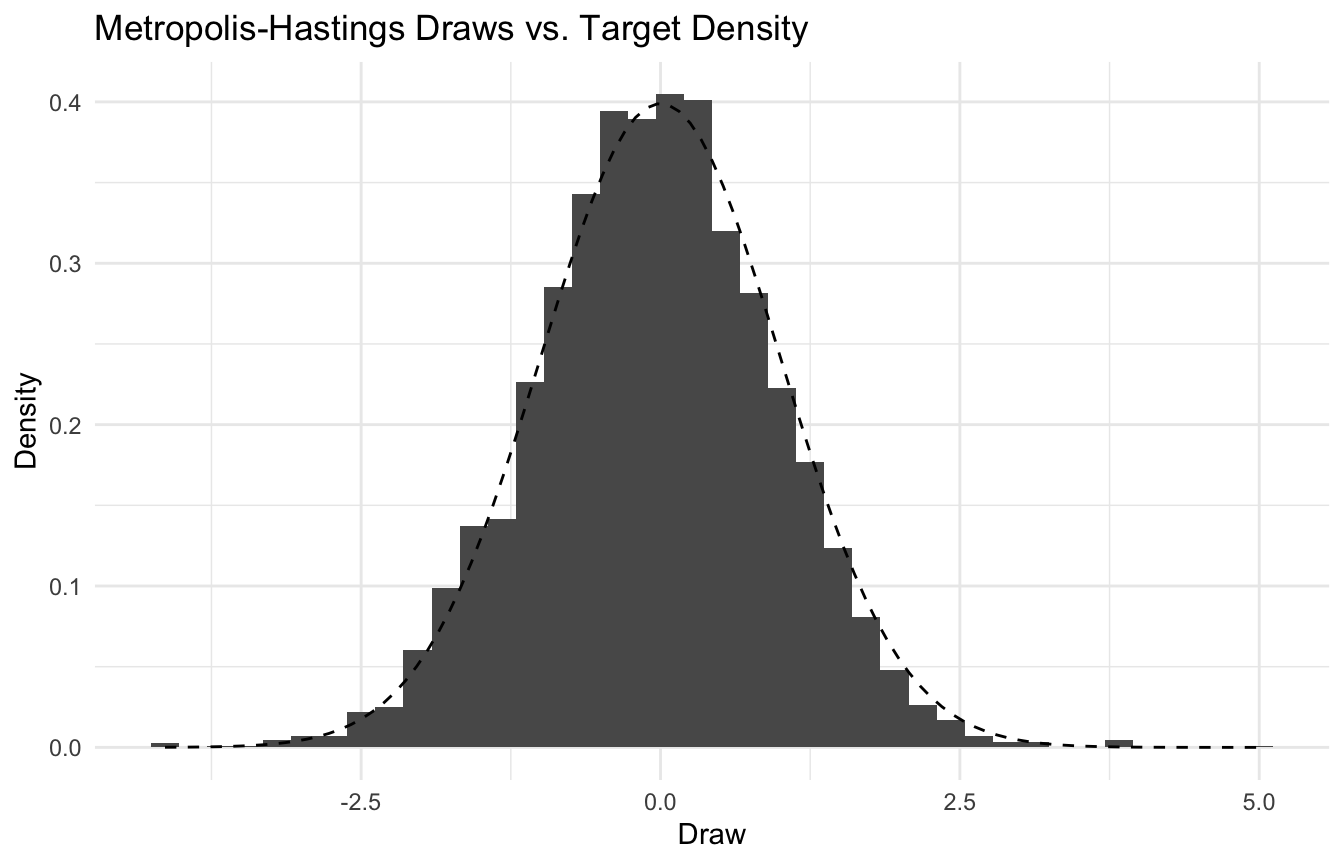
Over time, the chain explores the target distribution.
The beauty of Metropolis-Hastings is that it only needs the target distribution up to proportionality.
That makes it ideal for posterior distributions that are analytically awkward but easy to evaluate pointwise.
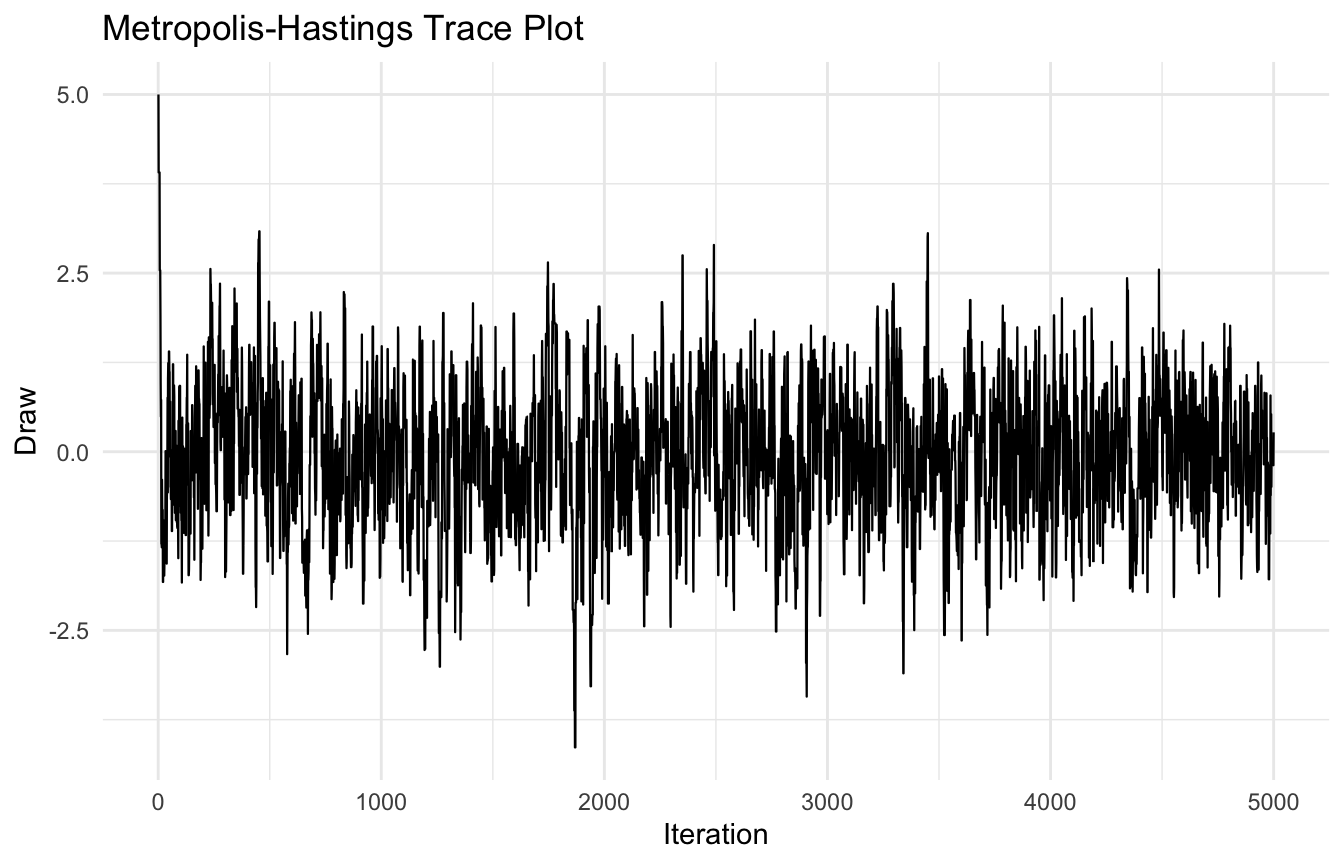
A Simple Metropolis-Hastings Example Makes MCMC Concrete
Suppose our target distribution is a standard normal density.
We will sample from it using a random-walk Metropolis-Hastings algorithm.
This is a simple risk-assessment style Monte Carlo workflow. The same logic scales to much more complex models.
High Dimensions Make Everything Harder
A recurring theme in Monte Carlo methods is that high-dimensional problems are harder.
Why?
Because in high dimensions:
direct integration becomes difficult
importance weights can become unstable
chains can mix slowly
target geometry becomes more complex
This is one reason advanced MCMC methods and variational approximations became so important.
The basic ideas still matter, but the computational challenge grows quickly with dimension.
Understanding that difficulty helps explain why simulation-based inference remains an active research area.
Monte Carlo Methods Connect Statistics and AI Very Directly
Monte Carlo methods are one of the clearest bridges between classical statistics and modern AI.
They appear in:
Bayesian posterior inference
approximate integration
generative modeling
uncertainty estimation
simulation-based decision support
and reinforcement learning style sampling ideas
That is why they remain so important conceptually.
They show that randomness is not only noise. It can also be a computational tool for answering otherwise intractable questions.
A Practical Checklist for Applied Work
Before using Monte Carlo methods, ask:
What quantity am I trying to approximate?
Can I sample directly from the target, or do I need indirect methods?
Is importance sampling likely to be stable here?
Does MCMC mix well enough for the problem?
Have I checked trace plots and empirical summaries?
Is the dimensionality likely to create computational problems?
Am I using enough draws for the desired level of precision?
These questions often matter more than simply running the algorithm.
NoteWhere This Shows Up in AI/ML
Monte Carlo dropout — running inference through a neural network multiple times with different dropout masks active, then averaging the predictions — is one of the few practical uncertainty quantification methods deployed in production clinical AI systems, including deterioration prediction models in ICU settings where the width of the uncertainty interval determines whether an alert is escalated or suppressed. MCMC sampling underlies Bayesian trauma outcome models used to estimate 30-day mortality in DoDTR analysis, where the posterior over model coefficients quantifies how much the injury severity estimates depend on the prior when data from rare injury patterns are sparse. When dropout-based uncertainty is disabled at inference time — the standard PyTorch behavior unless explicitly overridden — the model produces single point estimates with no signal about when it is operating outside its training distribution.
Closing: Monte Carlo Methods Make Hard Inference Feasible
Monte Carlo methods remain essential because many important statistical and ML quantities are analytically difficult but simulation-friendly.
Basic Monte Carlo turns sampling into approximation. Importance sampling reweights simulation from a convenient proposal. MCMC builds dependent draws from otherwise intractable target distributions. Together, these methods make uncertainty quantification possible in problems that would otherwise be out of reach.
Monte Carlo methods matter because when exact inference is too hard, simulation lets us trade algebra for computation and still learn something useful.
This post is part of the Bayesian Workflow Toolkit — a companion reference with Monte Carlo integration templates, importance sampling code, Metropolis-Hastings scaffolds, and MCMC diagnostic tools.
Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis. 3rd ed. Chapman; Hall/CRC.
Hastings, W. K. 1970. “Monte Carlo Sampling Methods Using Markov Chains and Their Applications.”Biometrika 57 (1): 97–109. https://doi.org/10.1093/biomet/57.1.97.
Metropolis, Nicholas, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. 1953. “Equation of State Calculations by Fast Computing Machines.”The Journal of Chemical Physics 21 (6): 1087–92. https://doi.org/10.1063/1.1699114.
Robert, Christian P., and George Casella. 2004. Monte Carlo Statistical Methods. 2nd ed. Springer.
Vehtari, Aki, Andrew Gelman, Daniel Simpson, Bob Carpenter, and Paul-Christian Bürkner. 2021. “Rank-Normalization, Folding, and Localization: An Improved \(\widehat{R}\) for Assessing Convergence of MCMC.”Bayesian Analysis 16 (2): 667–718. https://doi.org/10.1214/20-BA1221.