n <- 500
# U = unmeasured confounder (patient frailty)
U <- rnorm(n)
# Z = instrument (hospital distance, affects care but not frailty)
Z <- rnorm(n)
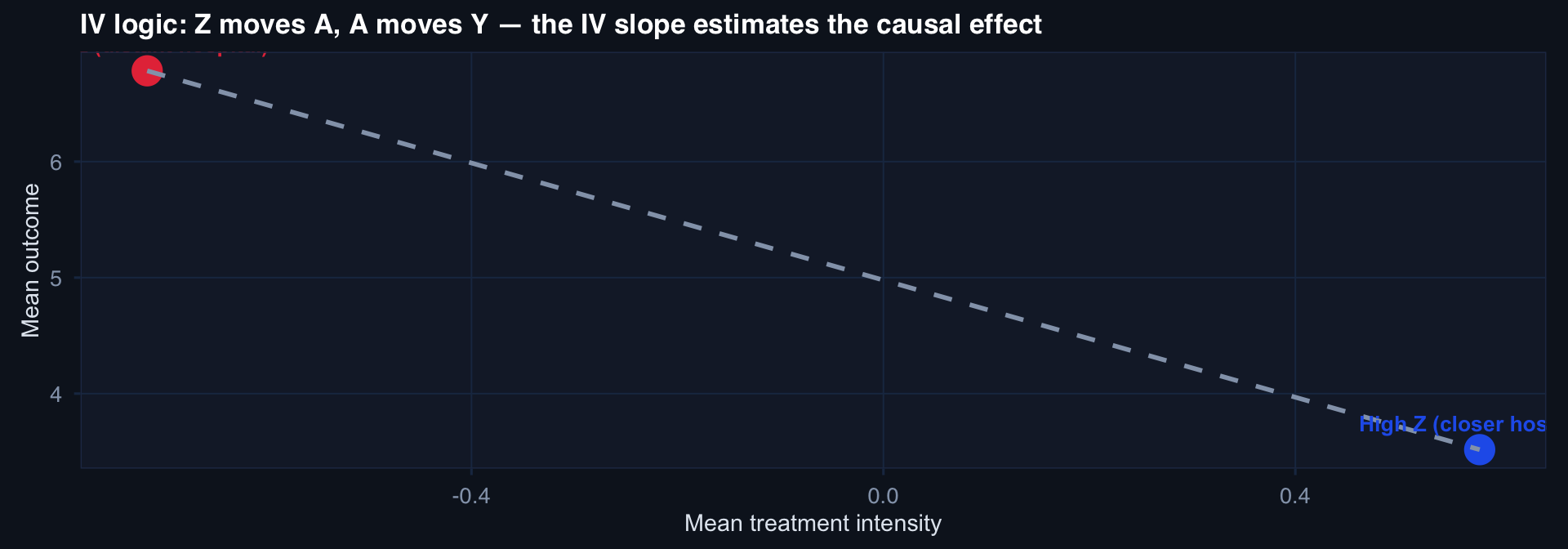
# Treatment (DCS): driven by U and Z
A <- 0.8*Z - 1.2*U + rnorm(n, 0, 0.8)
# Outcome: true treatment effect = -2, U also worsens outcome
Y <- 5 - 2*A + 2.5*U + rnorm(n, 0, 2)
# OLS (biased)
ols_est <- coef(lm(Y ~ A))["A"]
# 2SLS manually
stage1 <- lm(A ~ Z)
A_hat <- fitted(stage1)
stage2 <- lm(Y ~ A_hat)
iv_est <- coef(stage2)["A_hat"]
# First-stage F
f_stat <- summary(stage1)$fstatistic[1]
tibble(
Method = c("OLS (biased)", "2SLS (IV)", "True effect"),
Estimate = round(c(ols_est, iv_est, -2), 3),
`F-stat` = c(NA, round(f_stat, 1), NA)
)# A tibble: 3 × 3
Method Estimate `F-stat`
<chr> <dbl> <dbl>
1 OLS (biased) -3.12 NA
2 2SLS (IV) -2.45 197.
3 True effect -2 NA