n <- 400
# Unmeasured confounder U affects both severity and treatment choice
U <- rnorm(n)
# Observational: sicker patients more likely to get treatment
trt_obs <- rbinom(n, 1, plogis(-0.5 + 1.8*U))
y_obs <- 5 - 2*trt_obs + 2*U + rnorm(n, 0, 1.5)
# RCT: treatment fully independent of U
trt_rct <- rbinom(n, 1, 0.5)
y_rct <- 5 - 2*trt_rct + 2*U + rnorm(n, 0, 1.5)
bind_rows(
tibble(Design="Observational", Effect=coef(lm(y_obs ~ trt_obs))["trt_obs"]),
tibble(Design="RCT", Effect=coef(lm(y_rct ~ trt_rct))["trt_rct"]),
tibble(Design="Truth", Effect=-2)
) |> mutate(Design=factor(Design, levels=c("Observational","RCT","Truth"))) |>
ggplot(aes(Design, Effect, fill=Design)) +
geom_col(width=0.5, alpha=0.85) +
geom_hline(yintercept=-2, linetype=2, color="#e63946") +
scale_fill_manual(values=c("#e63946","#0891b2","#253554")) +
labs(title="Randomization recovers the true effect; observational data is biased by U",
y="Estimated treatment effect") +
theme_di() + theme(legend.position="none")Study Design Foundations: RCTs, Observational & Cross-Sectional
Design of Experiments — Lecture 1 of 4
2026-01-01
Why Randomization Works
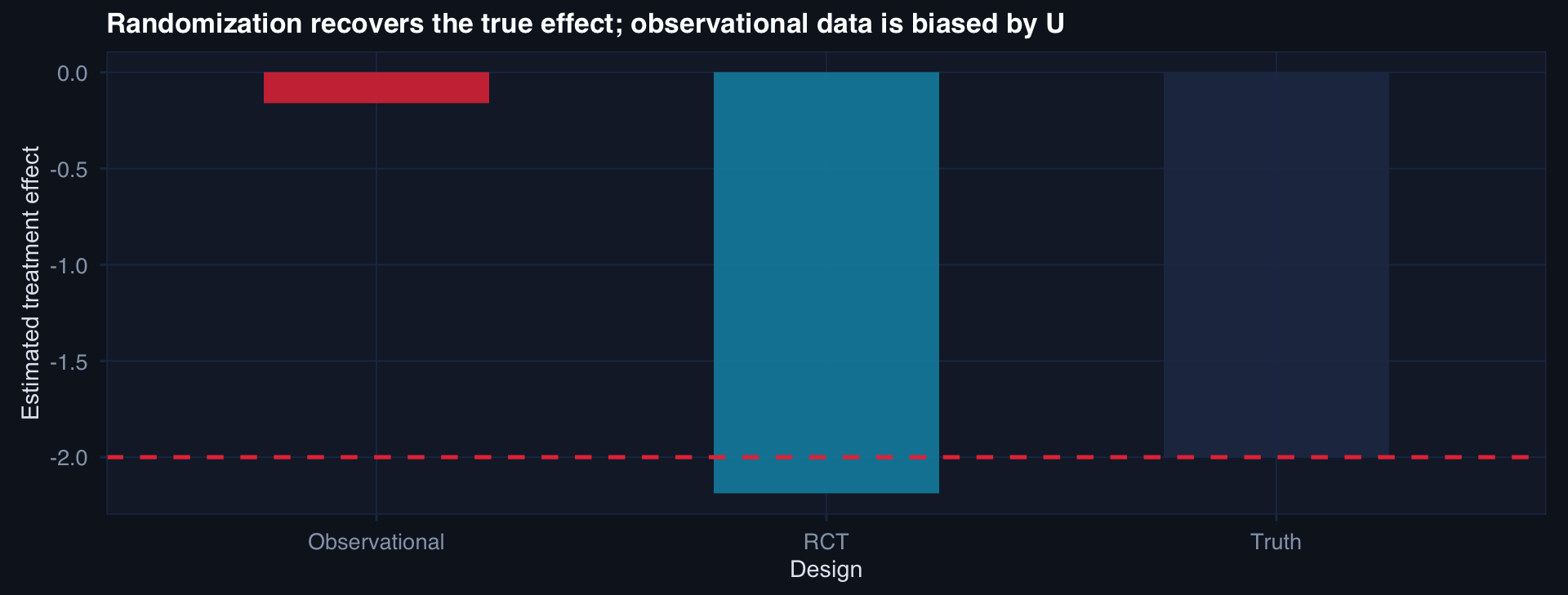
Randomization makes \(P(A=1 \mid U) = 0.5\) regardless of U. The groups become comparable on everything — measured and unmeasured — in expectation.
The Observational Design Spectrum
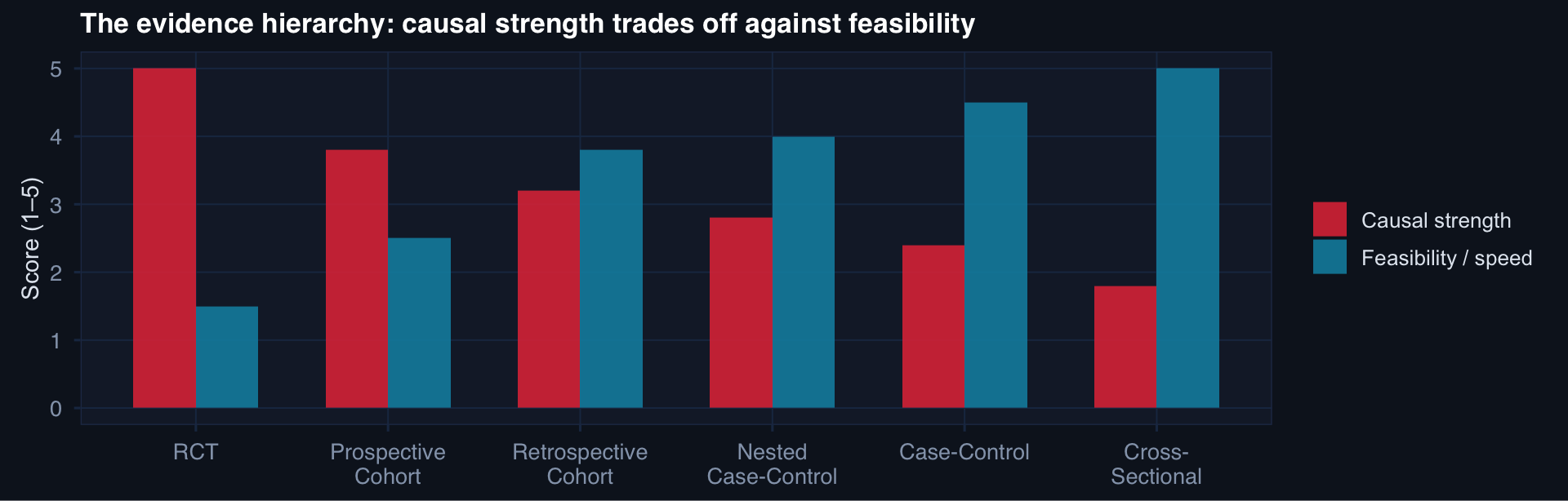
The best design is the one that can actually answer the question — within real-world constraints of time, cost, and ethics.
What a Cross-Sectional Study Can and Cannot Tell You
# Prevalence estimation from a cross-sectional survey
n <- 600
df_cs <- tibble(
age_group = sample(c("18-30","31-45","46-60","60+"), n, replace=TRUE,
prob=c(0.3, 0.3, 0.25, 0.15)),
site = sample(c("Role 2","Role 3","Role 4"), n, replace=TRUE),
cpg_compliant = rbinom(n, 1,
ifelse(age_group=="18-30", 0.82,
ifelse(age_group=="31-45", 0.76,
ifelse(age_group=="46-60", 0.70, 0.65))))
)
df_cs |>
group_by(age_group, site) |>
summarise(prevalence = mean(cpg_compliant), n=n(), .groups="drop") |>
ggplot(aes(age_group, prevalence, fill=site)) +
geom_col(position="dodge", alpha=0.85) +
geom_hline(yintercept=0.80, linetype=2, color="#e63946") +
scale_fill_manual(values=c("#2563eb","#0891b2","#8b5cf6")) +
scale_y_continuous(labels=scales::percent_format()) +
labs(title="CPG compliance prevalence by age group and care level — cross-sectional snapshot",
x="Age group", y="Compliance rate", fill="Care level") +
theme_di()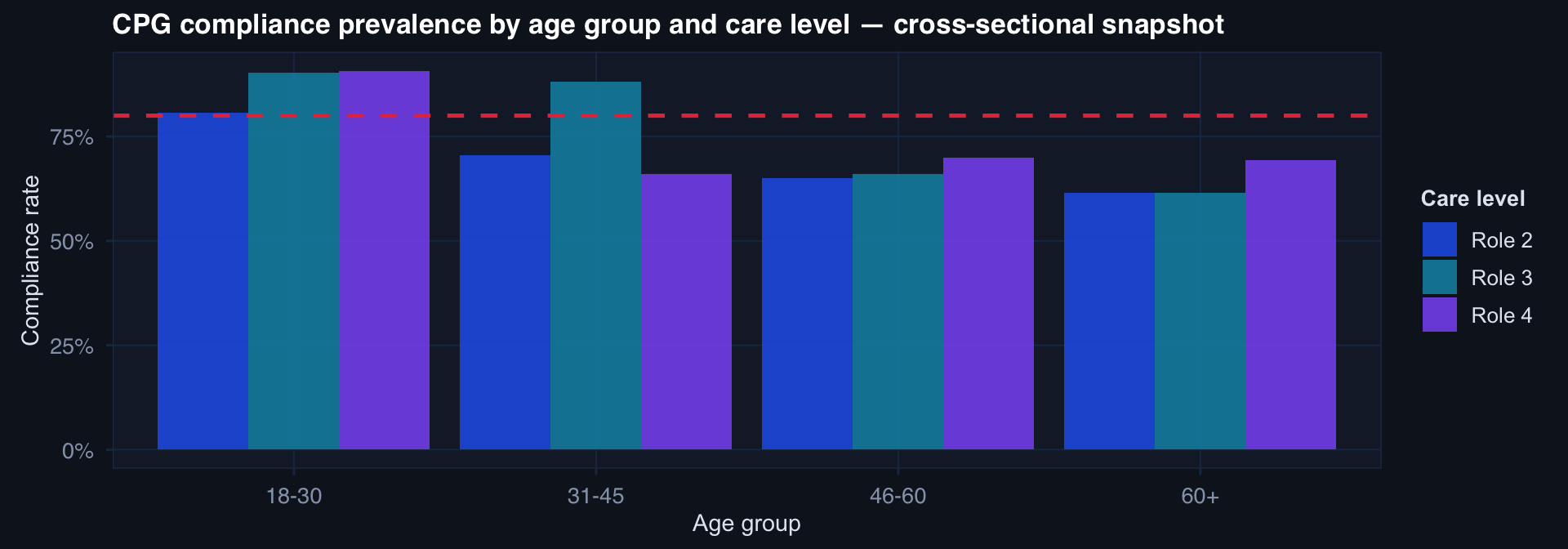
What this tells us: Prevalence at a point in time, stratified by observable characteristics.
What this cannot tell us: Whether compliance caused outcomes, or which direction the association runs.