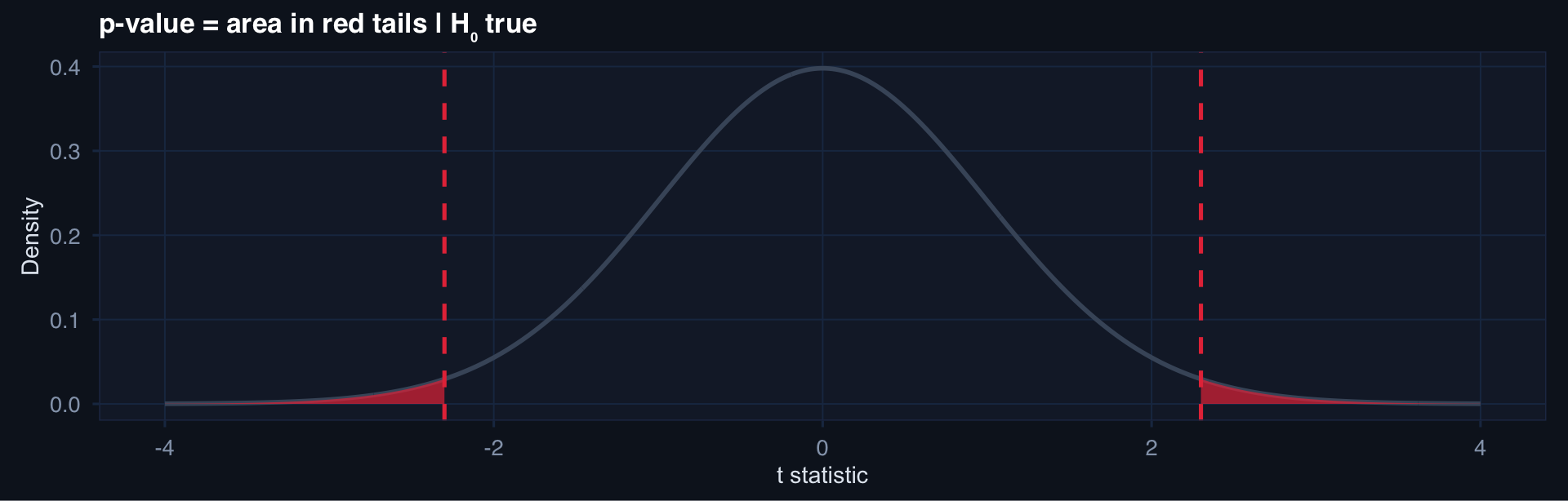
null_df <- tibble::tibble(t = seq(-4, 4, 0.01), y = dt(t, df = 98))
obs_t <- 2.3
ggplot2::ggplot(null_df, aes(t, y)) +
geom_line(linewidth = 1, color = "#475569") +
geom_area(data = filter(null_df, t >= obs_t), fill = "#e63946", alpha = 0.7) +
geom_area(data = filter(null_df, t <= -obs_t), fill = "#e63946", alpha = 0.7) +
geom_vline(xintercept = c(-obs_t, obs_t), linetype = 2) +
labs(title = "p-value = area in red tails | H₀ true", x = "t statistic", y = "Density") + theme_di()Inference — Estimating and Testing from Data
Applied Statistics for AI & Clinical Decision-Making — Lecture 3 of 10
2026-01-01
What a p-value Actually Is
p-value = P(observing data this extreme or more | H₀ is true)
What it is NOT:
- P(H₀ is true)
- P(you made a mistake)
- A measure of effect size
- A measure of clinical importance
What a Confidence Interval Actually Means
A 95% CI means: if we repeated this study 100 times, approximately 95 of the resulting intervals would contain the true parameter.
It does NOT mean: “there is a 95% probability the true value is in this interval”
simulate_ci <- function(id) {
x <- rnorm(40, mean=0.30, sd=0.10)
ci <- t.test(x)$conf.int
tibble(id=id, lower=ci[1], upper=ci[2], contains_true = ci[1] <= 0.30 & ci[2] >= 0.30)
}
ci_df <- purrr::map_dfr(1:50, simulate_ci)
ggplot2::ggplot(ci_df, aes(x=id, ymin=lower, ymax=upper, color=contains_true)) +
geom_errorbar(linewidth=0.6) +
geom_hline(yintercept=0.30, linetype=2, color="#e63946") +
scale_color_manual(values=c("FALSE"="#e63946","TRUE"="#2563eb")) +
coord_flip() + theme_di() +
labs(title="50 simulated 95% CIs — ~5% miss the true value (red)",
x="Simulation", y="Interval", color="Contains true value")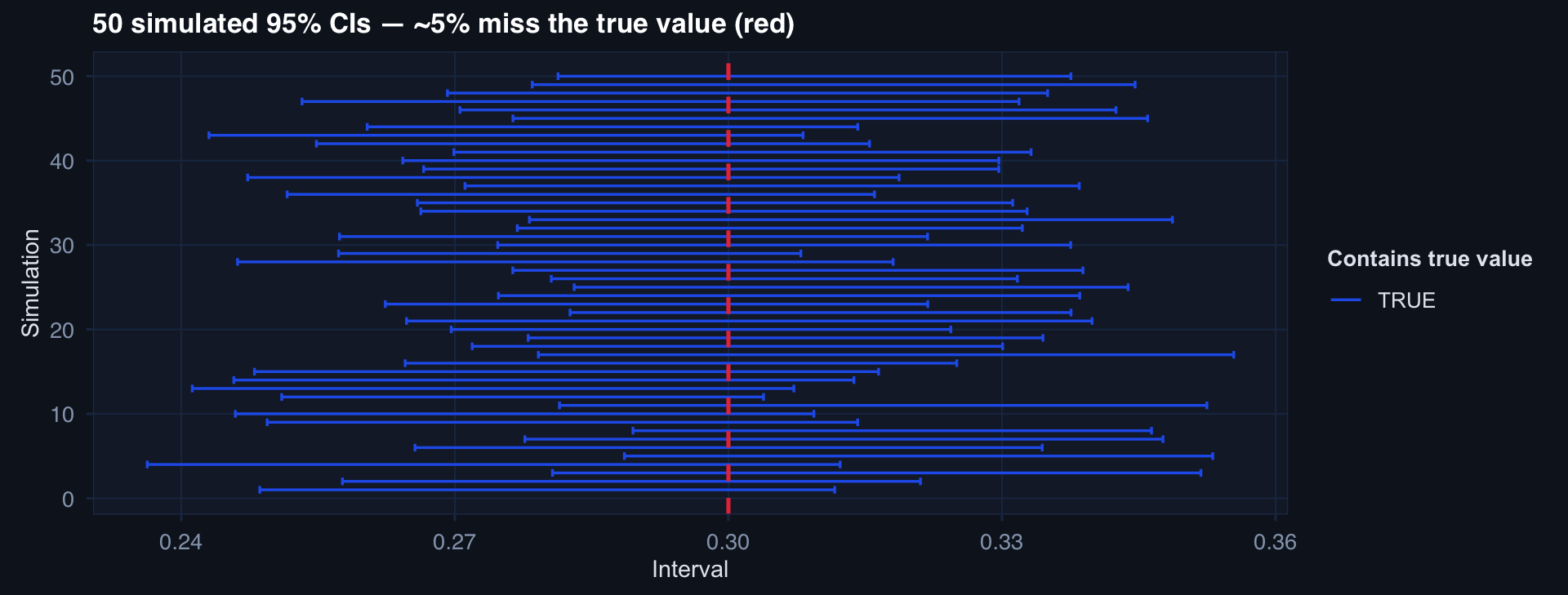
CI Width Tells You About Precision
ci_widths <- tibble::tibble(
n = c(20, 50, 100, 200, 500, 1000),
width = 2 * qt(0.975, df = n-1) * (0.15 / sqrt(n))
)
ggplot2::ggplot(ci_widths, aes(x=n, y=width)) +
geom_line(linewidth=1.2, color="#2563eb") +
geom_point(size=3, color="#1b2e4b") +
labs(title="95% CI width vs. sample size (σ = 0.15)",
x="n", y="CI width (percentage points)") + theme_di()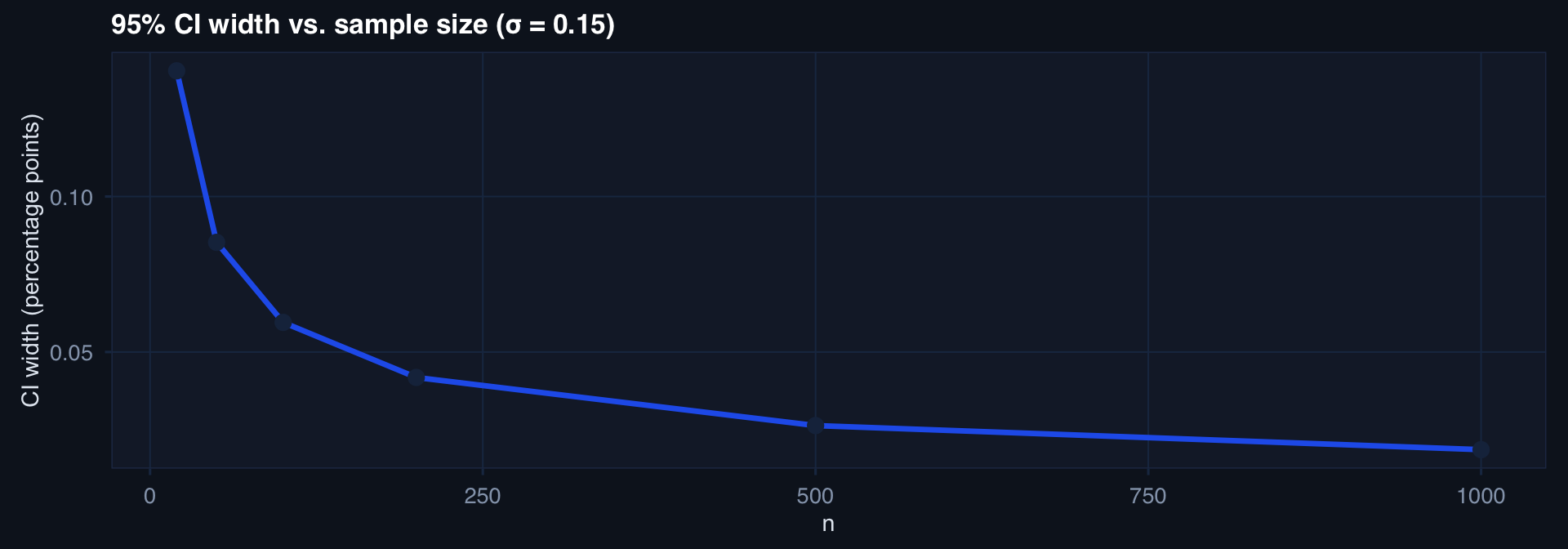
Registry reporting: A 95% CI of [0.23, 0.41] for a CPG compliance rate tells commanders the range of plausible true compliance — far more actionable than “p = 0.003.”
MLE in Action: Fitting a Bernoulli Model
# Trauma mortality: find MLE of p from n=50 patients, 12 deaths
n_patients <- 50; n_deaths <- 12
# Log-likelihood surface
p_grid <- seq(0.01, 0.99, 0.001)
log_lik <- dbinom(n_deaths, size=n_patients, prob=p_grid, log=TRUE)
mle_p <- p_grid[which.max(log_lik)]
tibble::tibble(p = p_grid, log_lik = log_lik) |>
ggplot2::ggplot(aes(p, log_lik)) +
geom_line(linewidth=1.2, color="#2563eb") +
geom_vline(xintercept=mle_p, linetype=2, color="#e63946") +
annotate("text", x=mle_p+0.06, y=-25,
label=paste0("MLE = ", mle_p), color="#e63946") +
labs(title="Log-likelihood for mortality rate p",
x="p (mortality rate)", y="Log-likelihood") + theme_di()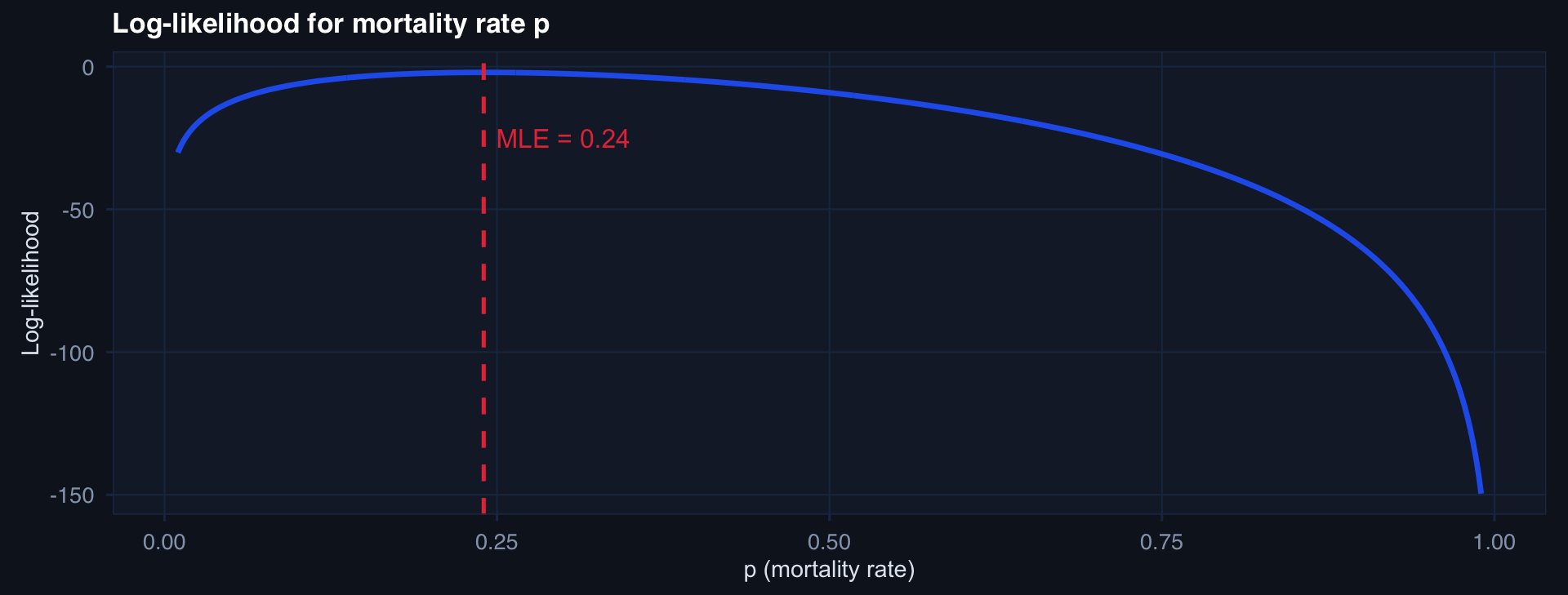
MLE = 12/50 = 0.24 — exactly the sample proportion. The math confirms the intuition.