# Prior: Beta(7, 3) → prior belief ~70% compliance
# Data: 14/20 compliant
# Posterior: Beta(7+14, 3+6) = Beta(21, 9)
theta <- seq(0, 1, 0.001)
prior <- dbeta(theta, 7, 3)
likelihood_prop <- dbeta(theta, 15, 7) # normalized for display
posterior <- dbeta(theta, 21, 9)
tibble(theta, prior, likelihood_prop, posterior) |>
tidyr::pivot_longer(-theta) |>
ggplot(aes(theta, value, color=name, linewidth=name)) +
geom_line() +
scale_color_manual(values=c("prior"="#94a3b8","likelihood_prop"="#f59e0b","posterior"="#2563eb")) +
scale_linewidth_manual(values=c("prior"=0.8,"likelihood_prop"=0.8,"posterior"=1.4)) +
labs(title="Beta-Binomial conjugate update",
x="Compliance rate θ", y="Density", color=NULL, linewidth=NULL) + theme_di()Bayesian Methods & Simulation
Applied Statistics for AI & Clinical Decision-Making — Lecture 4 of 10
2026-01-01
Conjugate Updating: Beta-Binomial
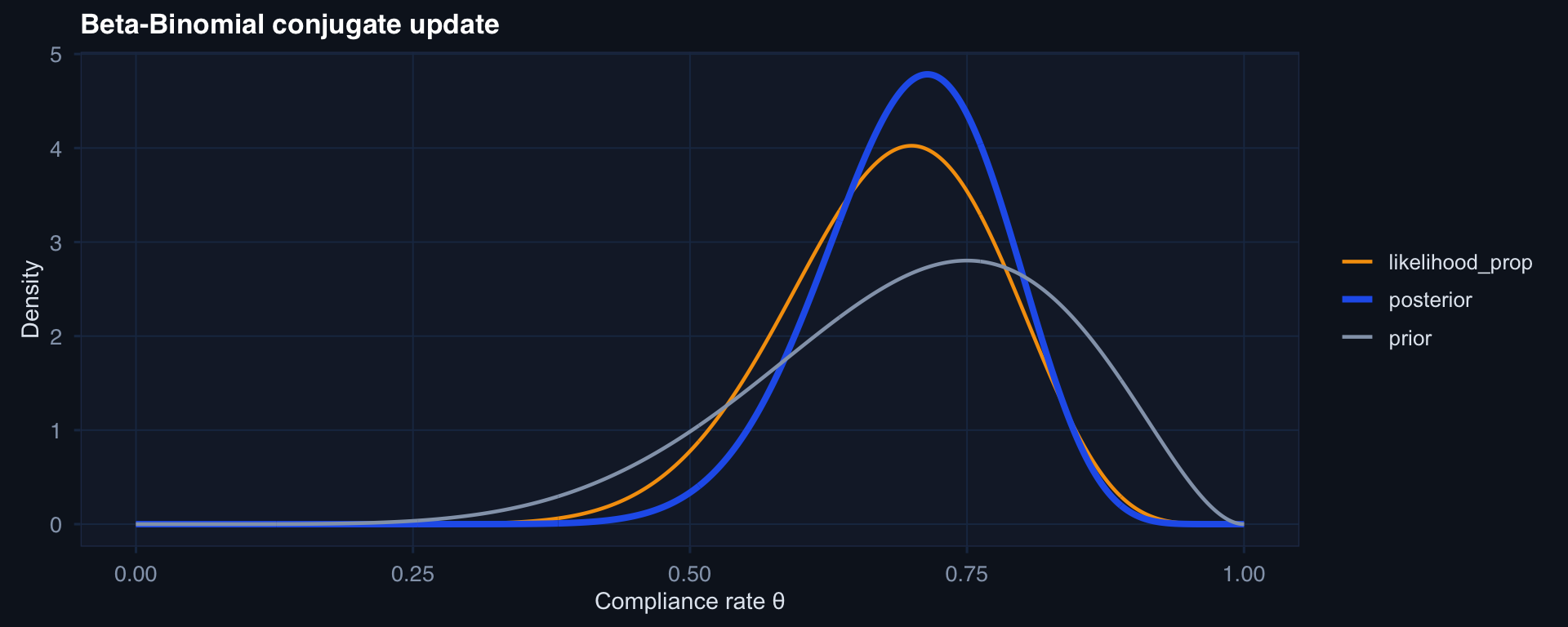
Posterior Predictive Distribution
# Posterior Beta(21,9) — predict next 20 patients
n_sims <- 10000; n_next <- 20
theta_sims <- rbeta(n_sims, 21, 9)
y_pred <- rbinom(n_sims, n_next, theta_sims)
tibble(compliant = y_pred) |>
ggplot(aes(x=compliant)) +
geom_bar(fill="#2563eb", alpha=0.8) +
geom_vline(xintercept=mean(y_pred), linetype=2, color="#e63946") +
labs(title="Posterior predictive: compliant cases in next 20 patients",
x="# compliant", y="Count") + theme_di()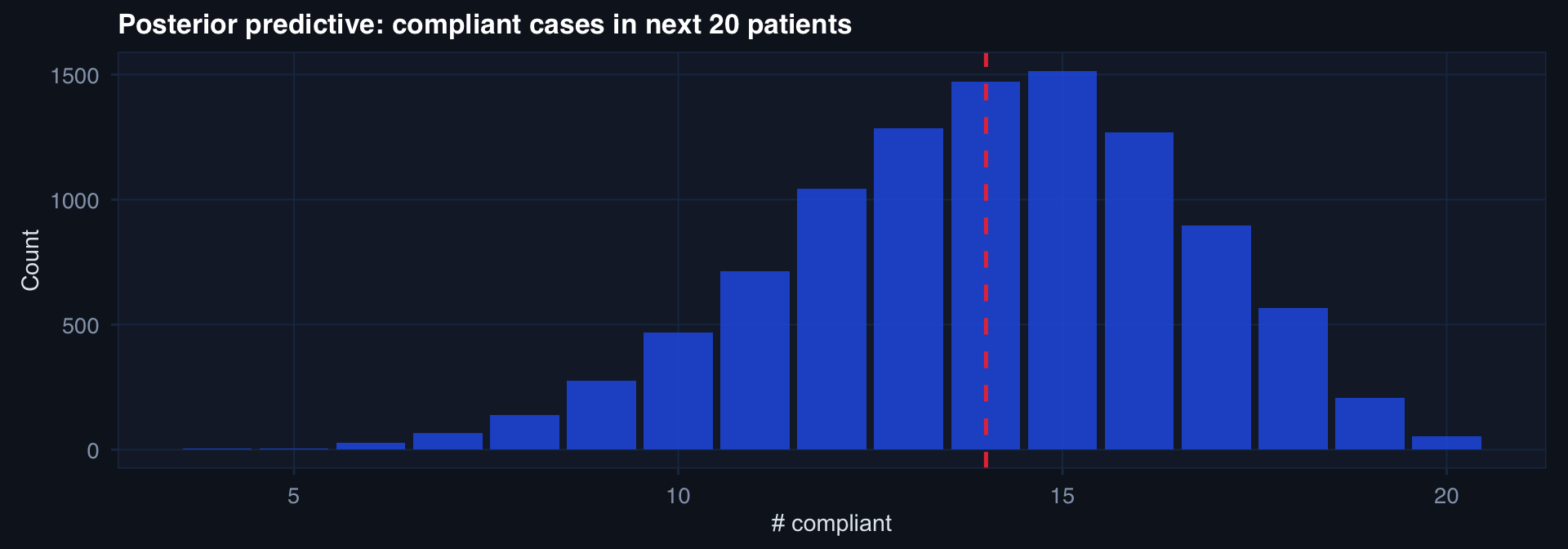
The posterior predictive propagates parameter uncertainty into outcome uncertainty — the right thing to give commanders.
The Core Monte Carlo Idea
\[E_p[g(X)] \approx \frac{1}{n}\sum_{i=1}^n g(X_i), \quad X_i \sim p(x)\]
Simulate → transform → average.
Monte Carlo π estimate: 3.1264 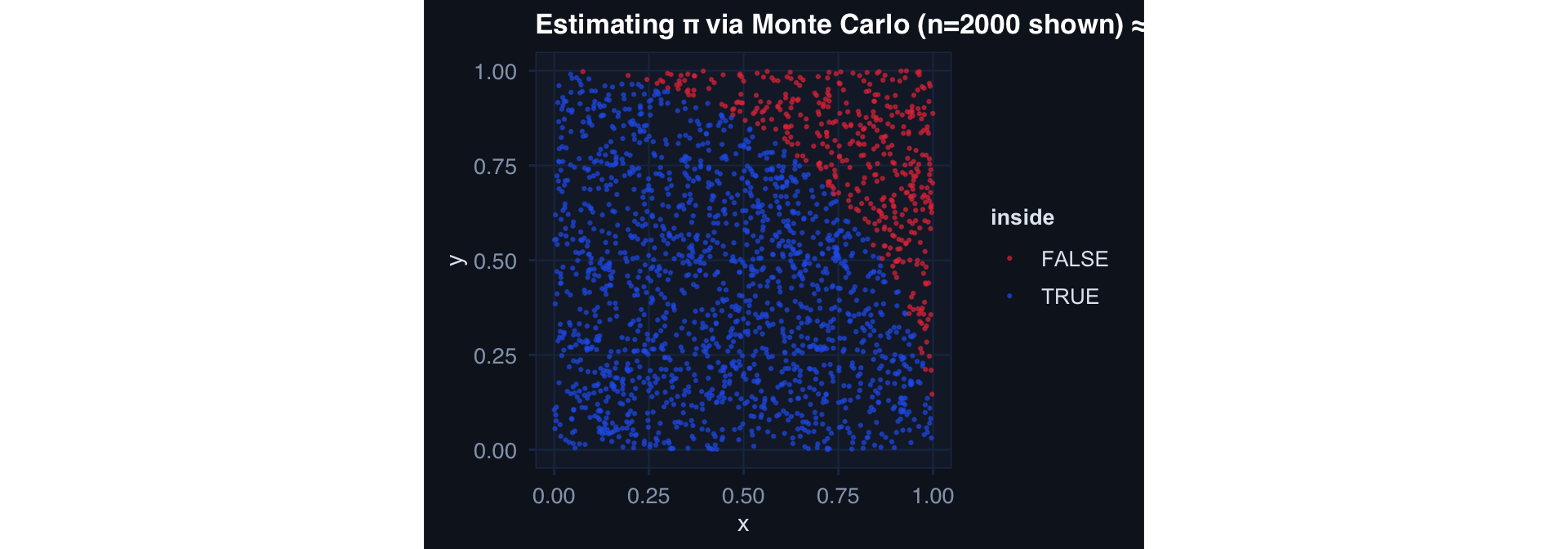
MCMC: Sampling from Intractable Posteriors
When we can’t sample directly, build a Markov chain that converges to the target.
# Metropolis-Hastings targeting N(0,1)
n_iter <- 4000; chain <- numeric(n_iter); chain[1] <- 5
for(i in 2:n_iter) {
prop <- rnorm(1, chain[i-1], 0.8)
log_a <- dnorm(prop,log=TRUE) - dnorm(chain[i-1],log=TRUE)
chain[i] <- if(log(runif(1)) < log_a) prop else chain[i-1]
}
tibble(iter=1:n_iter, value=chain) |>
ggplot(aes(iter, value)) +
geom_line(linewidth=0.35, color="#2563eb") +
geom_hline(yintercept=0, linetype=2, color="#e63946") +
labs(title="Metropolis-Hastings trace plot — targeting N(0,1)",
x="Iteration", y="Sample") + theme_di()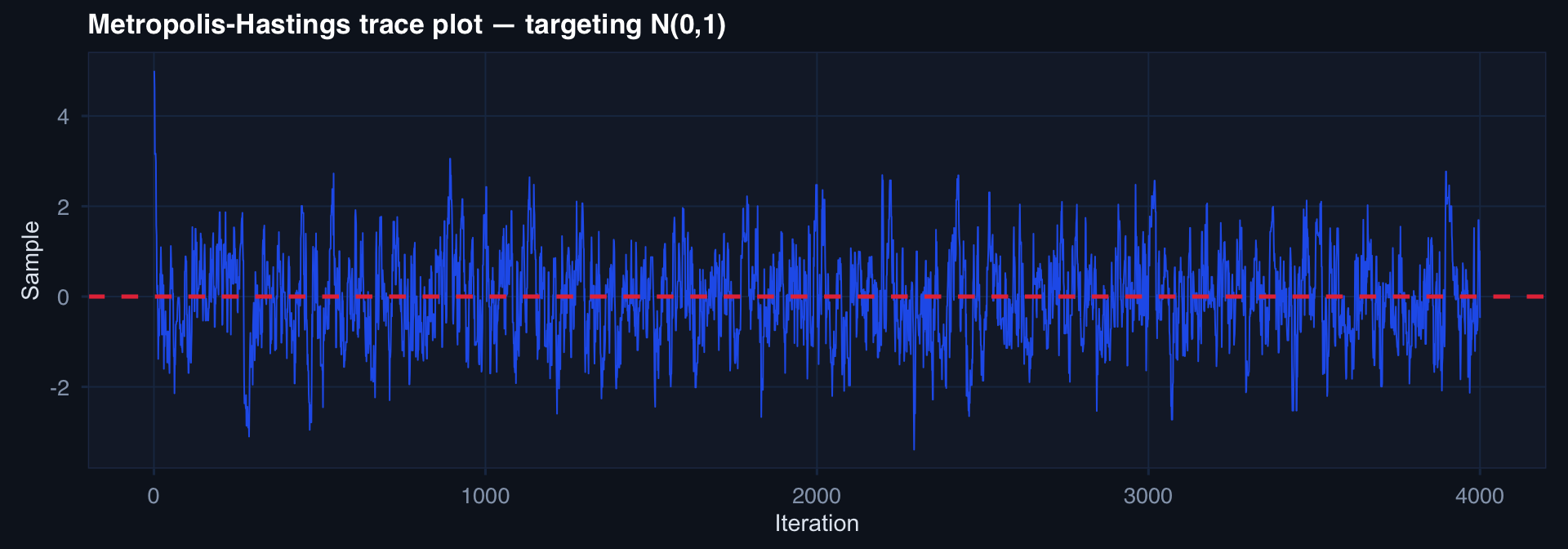
Bayesian trauma model: MCMC lets us fit hierarchical models with random effects for facility, time period, and injury pattern — posteriors that have no closed form but can be sampled.
Shannon Entropy: Measuring Uncertainty
\[H(X) = -\sum_{x} P(x) \log_2 P(x)\]
Units: bits (base 2) or nats (base e)
entropy <- function(p) -sum(p[p>0] * log2(p[p>0]))
probs <- seq(0.01, 0.99, 0.01)
entropies <- sapply(probs, function(p) entropy(c(p, 1-p)))
tibble(p=probs, H=entropies) |>
ggplot(aes(p, H)) +
geom_line(linewidth=1.3, color="#2563eb") +
geom_vline(xintercept=0.5, linetype=2, color="#e63946") +
labs(title="Entropy of a binary outcome — max at p=0.5",
x="P(event)", y="Entropy H (bits)") + theme_di()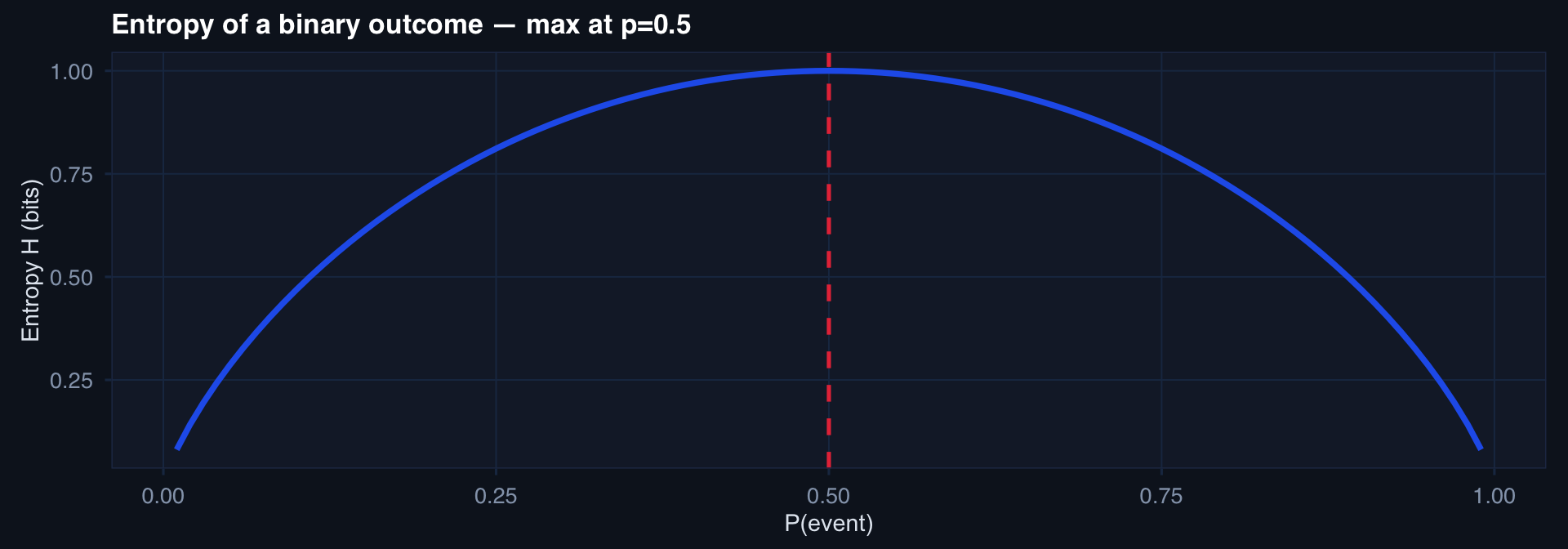
High entropy = high uncertainty (50/50 coin flip). Low entropy = low uncertainty (rare event we’re nearly certain about).