n <- 200
df <- tibble(
iss = rnorm(n, 25, 12),
los = 2 + 0.4 * iss + rnorm(n, 0, 5)
)
fit <- lm(los ~ iss, data = df)
df$fitted <- fitted(fit)
ggplot(df, aes(iss, los)) +
geom_point(alpha=0.4, color="#475569") +
geom_smooth(method="lm", color="#2563eb", se=TRUE) +
labs(title="Linear regression: ISS → Hospital LOS",
x="Injury Severity Score", y="Length of Stay (days)") + theme_di()Regression — The Workhorse Models
Applied Statistics for AI & Clinical Decision-Making — Lecture 5 of 10
2026-01-01
OLS: The Normal Equations
\[\hat{\beta} = (X^\top X)^{-1} X^\top y\]
Minimize: \(\text{RSS} = \sum_{i=1}^n (y_i - \hat{y}_i)^2\)
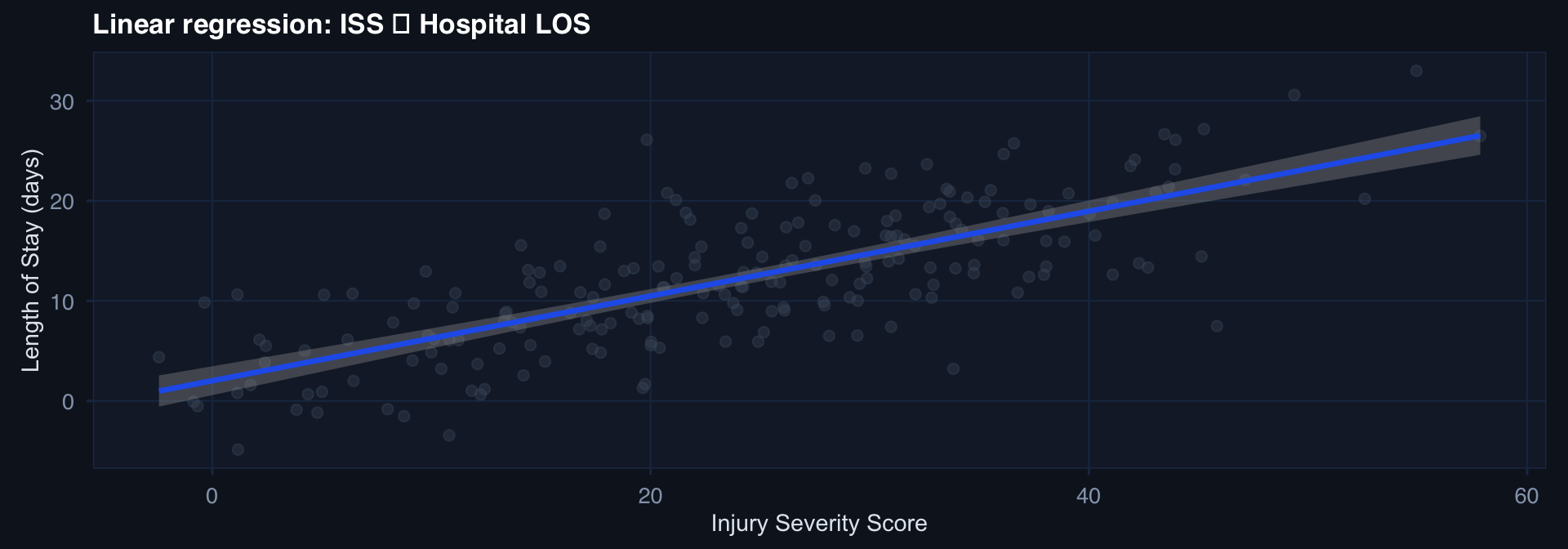
Coefficient interpretation: β = 0.40 means each 1-point increase in ISS is associated with 0.4 additional days of LOS, holding all other predictors constant.
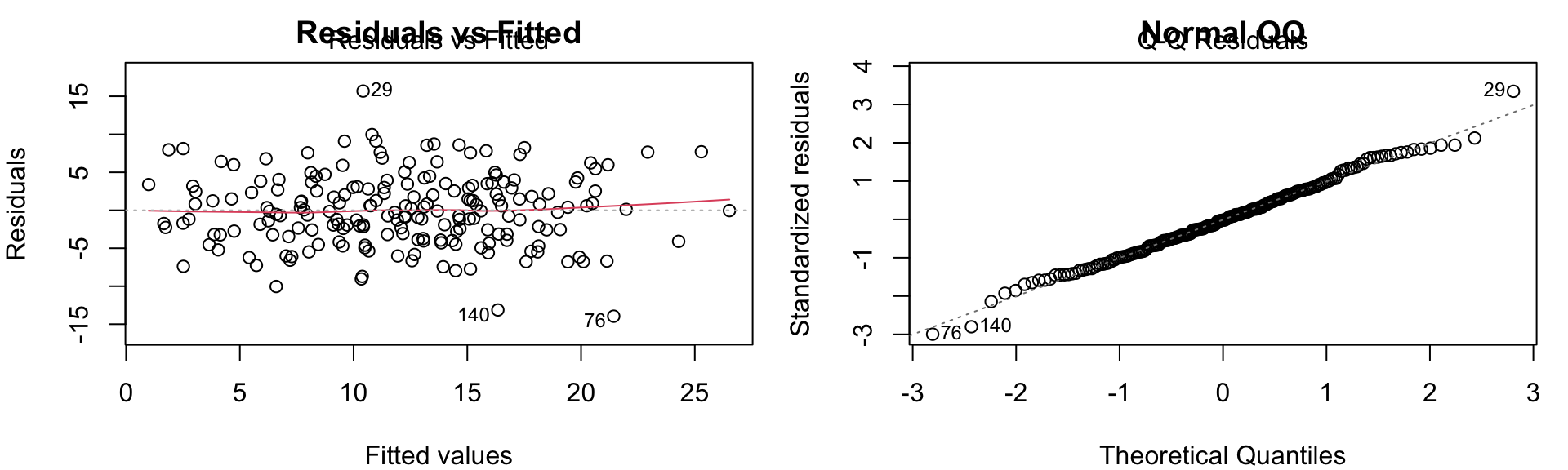
The Four OLS Assumptions (L-I-N-E)
| Assumption | What it means | How to check |
|---|---|---|
| Linearity | E[Y|X] is linear in X | Residual vs. fitted plot |
| Independence | Observations independent | Study design, ACF plot |
| Normality | Residuals ~ Normal | QQ plot |
| Equal variance | Var(ε) constant | Scale-location plot |
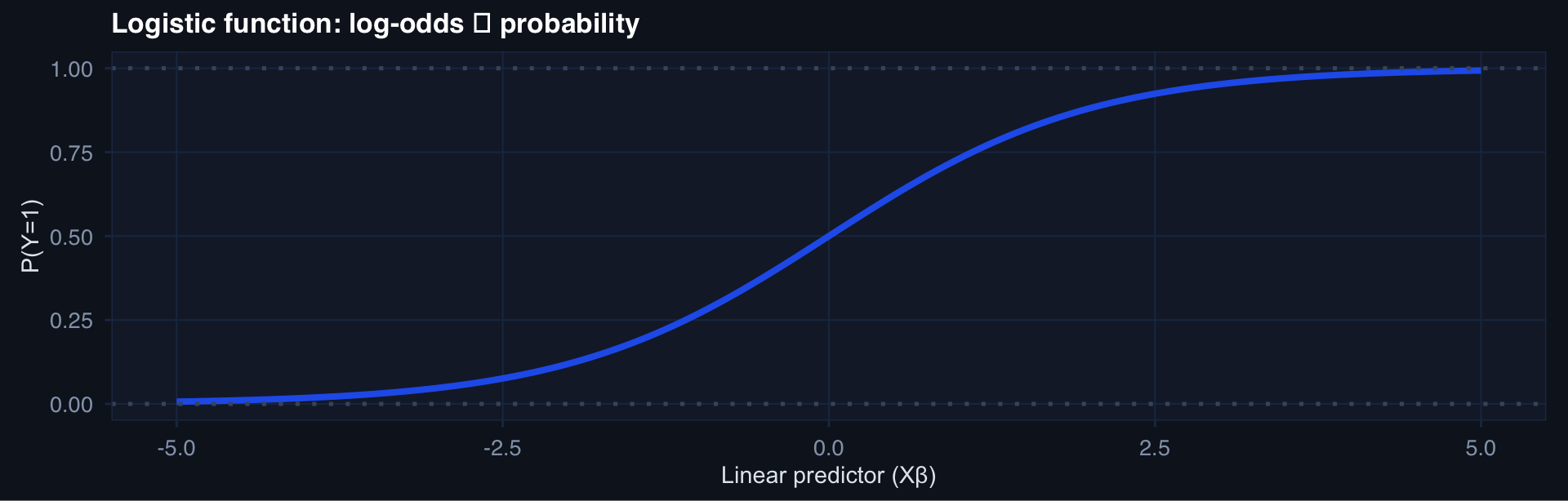
Why Not Linear Regression for Binary Outcomes?
Linear regression on a 0/1 outcome produces predicted probabilities outside [0,1].
The logistic solution: model the log-odds.
\[\log\frac{P(Y=1)}{P(Y=0)} = \beta_0 + \beta_1 X_1 + \dots\]
\[P(Y=1) = \frac{e^{X\beta}}{1 + e^{X\beta}} = \text{logistic}(X\beta)\]
Calibration: The Most Important Model Property
df_log$pred_prob <- predict(fit_log, type="response")
df_log |>
dplyr::mutate(decile = ntile(pred_prob, 10)) |>
dplyr::group_by(decile) |>
dplyr::summarise(mean_pred=mean(pred_prob), obs_rate=mean(died)) |>
ggplot(aes(mean_pred, obs_rate)) +
geom_abline(linetype=2, color="#94a3b8") +
geom_point(size=3, color="#2563eb") +
geom_line(color="#2563eb") +
labs(title="Calibration plot: predicted vs. observed mortality",
x="Mean predicted probability", y="Observed rate") + theme_di()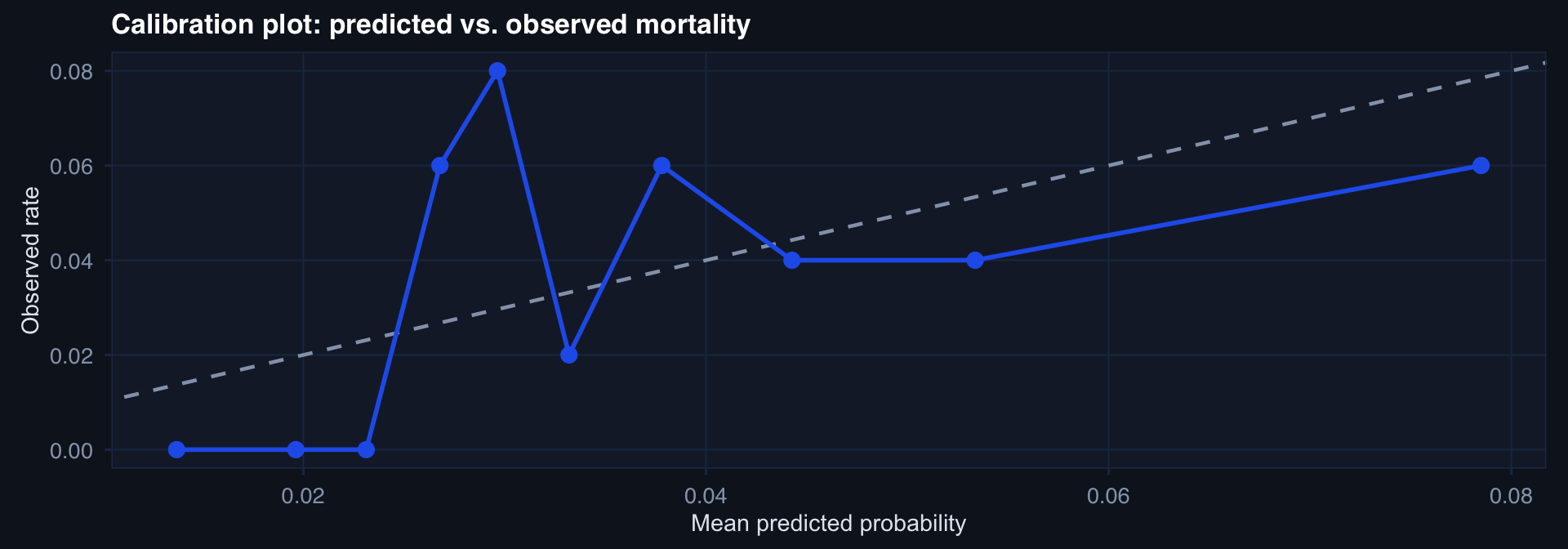
A model that says “30% mortality risk” should be wrong about 70% of the time. Calibration measures whether the model’s confidence matches reality. A discriminating but miscalibrated model gives overconfident wrong answers — dangerous in clinical triage.