Df Sum Sq Mean Sq F value Pr(>F)
role 2 8613 4306 38.45 3.46e-15 ***
Residuals 237 26544 112
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Comparing Groups & Special Clinical Methods
Applied Statistics for AI & Clinical Decision-Making — Lecture 6 of 10
2026-01-01
Kaplan-Meier Curves
df_surv <- tibble(
time = c(rexp(100, 0.02), rexp(100, 0.035)),
status = rbinom(200, 1, 0.75),
group = rep(c("Standard","Damage Control"), each=100)
)
km_fit <- survfit(Surv(time, status) ~ group, data=df_surv)
plot(km_fit, col=c("#2563eb","#e63946"), lwd=2,
xlab="Days", ylab="Survival probability",
main="Kaplan-Meier: Standard vs. Damage Control Resuscitation")
legend("topright", levels(factor(df_surv$group)),
col=c("#2563eb","#e63946"), lwd=2)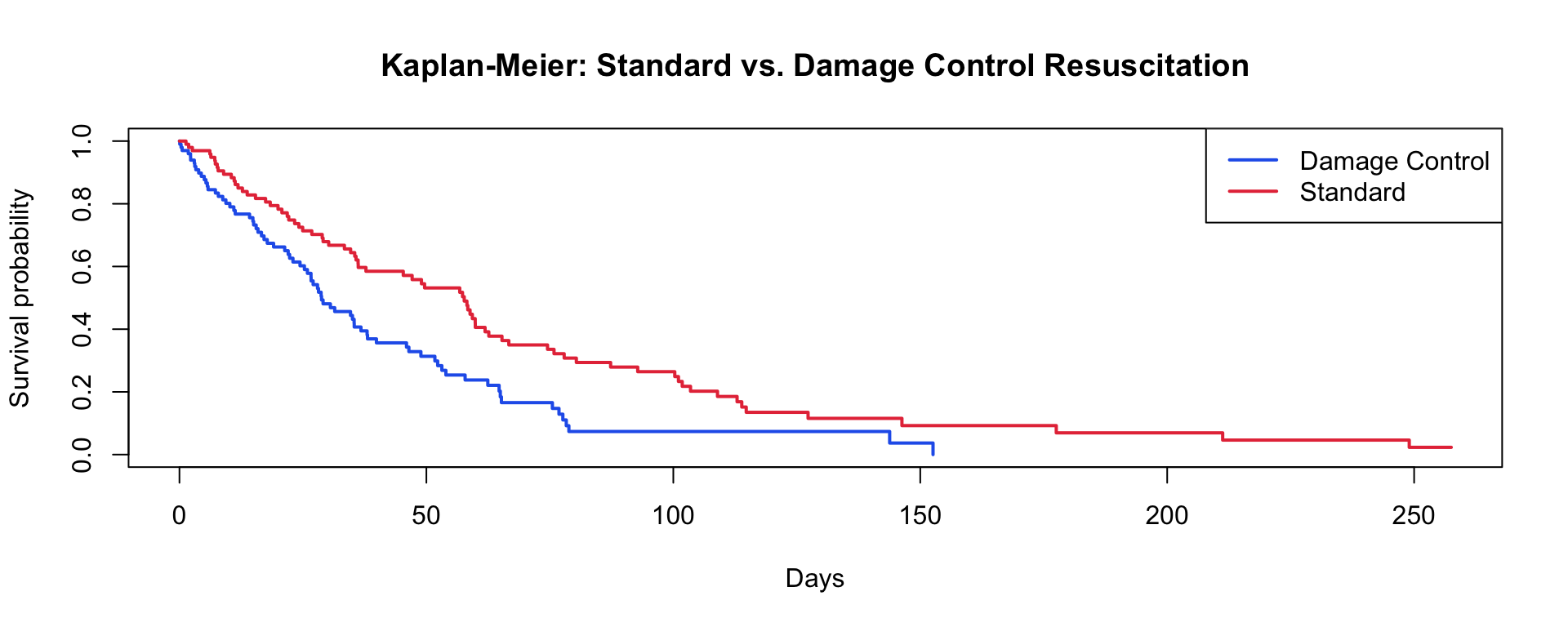
Wilcoxon Rank-Sum in Practice
Wilcoxon W = 57.5 p = 0.596
Key property: Tests whether one distribution is stochastically larger than another — doesn’t require Normality, doesn’t require equal variances.