library(glmnet)
n <- 500
df_rf <- tibble::tibble(
iss=rnorm(n,28,12), sbp=rnorm(n,110,20),
gcs=rnorm(n,13,3), age=rnorm(n,35,15),
died=rbinom(n,1,plogis(-3+0.05*iss-0.02*sbp-0.1*gcs+0.02*age))
)
X_mat <- model.matrix(died ~ iss + sbp + gcs + age, data=df_rf)[,-1]
cv_fit <- cv.glmnet(X_mat, df_rf$died, family="binomial", alpha=1, nfolds=10)
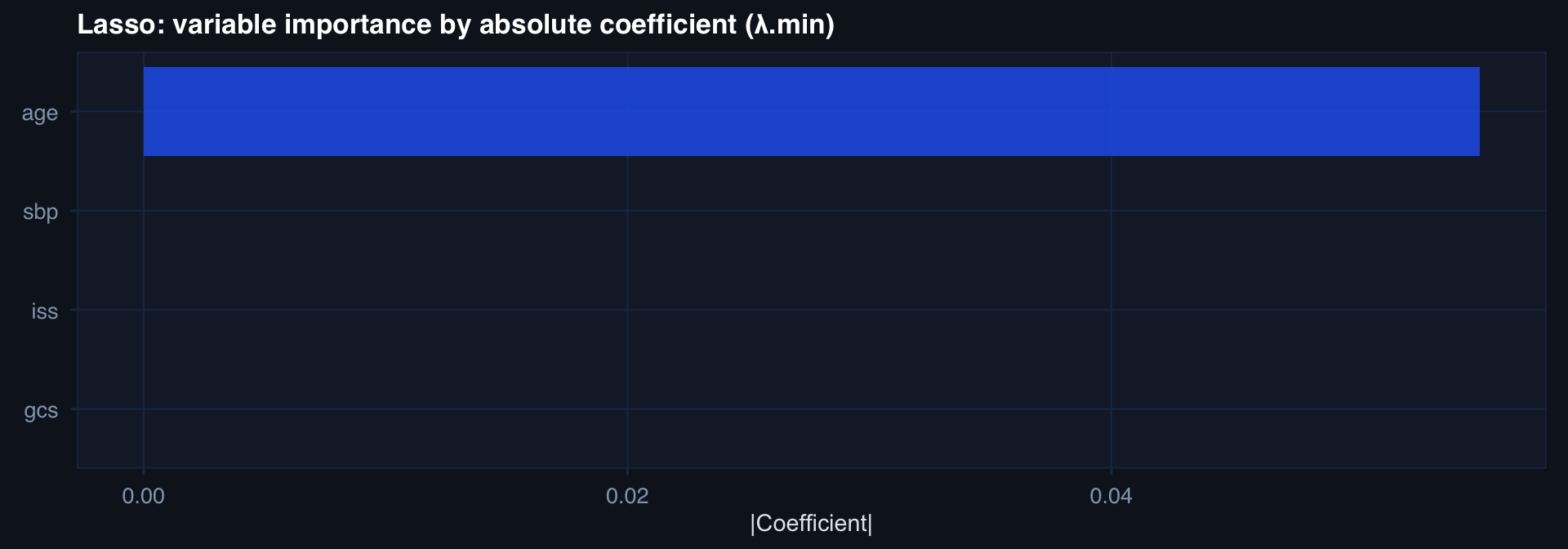
# Variable importance: absolute coefficient at lambda.min
coef_df <- as.matrix(coef(cv_fit, s="lambda.min"))[-1,,drop=FALSE]
tibble::tibble(
Feature = rownames(coef_df),
Importance = abs(coef_df[,1])
) |>
dplyr::arrange(dplyr::desc(Importance)) |>
ggplot2::ggplot(ggplot2::aes(x=reorder(Feature,Importance), y=Importance)) +
ggplot2::geom_col(fill="#2563eb", alpha=0.85) +
ggplot2::coord_flip() +
ggplot2::labs(title="Lasso: variable importance by absolute coefficient (λ.min)",
x=NULL, y="|Coefficient|") +
theme_di()