No Yes
No 0.4 0.1
Yes 0.1 0.4Probability Foundations
Applied Statistics for AI & Clinical Decision-Making — Lecture 1 of 10
2026-01-01
Why Variance Matters in Clinical AI
Two models with the same mean prediction can have very different clinical implications:
set.seed(123)
preds <- tibble::tibble(
model_a = rnorm(500, mean = 0.3, sd = 0.05),
model_b = rnorm(500, mean = 0.3, sd = 0.18)
) |>
tidyr::pivot_longer(everything(), names_to = "model", values_to = "pred_risk")
ggplot2::ggplot(preds, ggplot2::aes(x = pred_risk, fill = model)) +
ggplot2::geom_density(alpha = 0.5) +
ggplot2::labs(title = "Same mean risk — very different uncertainty",
x = "Predicted Risk", y = "Density") +
theme_di()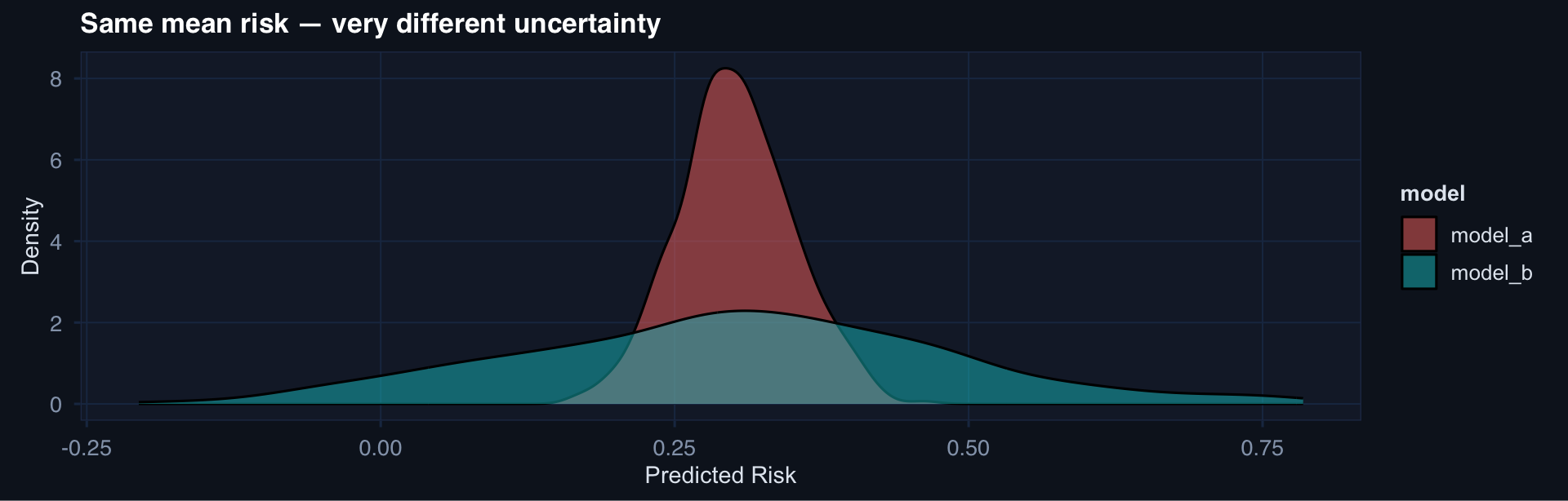
The Normal Distribution: Why It’s Everywhere
x <- seq(-4, 4, length.out = 300)
tibble::tibble(x = x, y = dnorm(x)) |>
ggplot2::ggplot(ggplot2::aes(x, y)) +
ggplot2::geom_line(linewidth = 1.2, color = "#2563eb") +
ggplot2::geom_area(fill = "#2563eb", alpha = 0.12) +
ggplot2::labs(title = "Standard Normal N(0,1)",
x = "Standard deviations from mean", y = "Density") +
theme_di()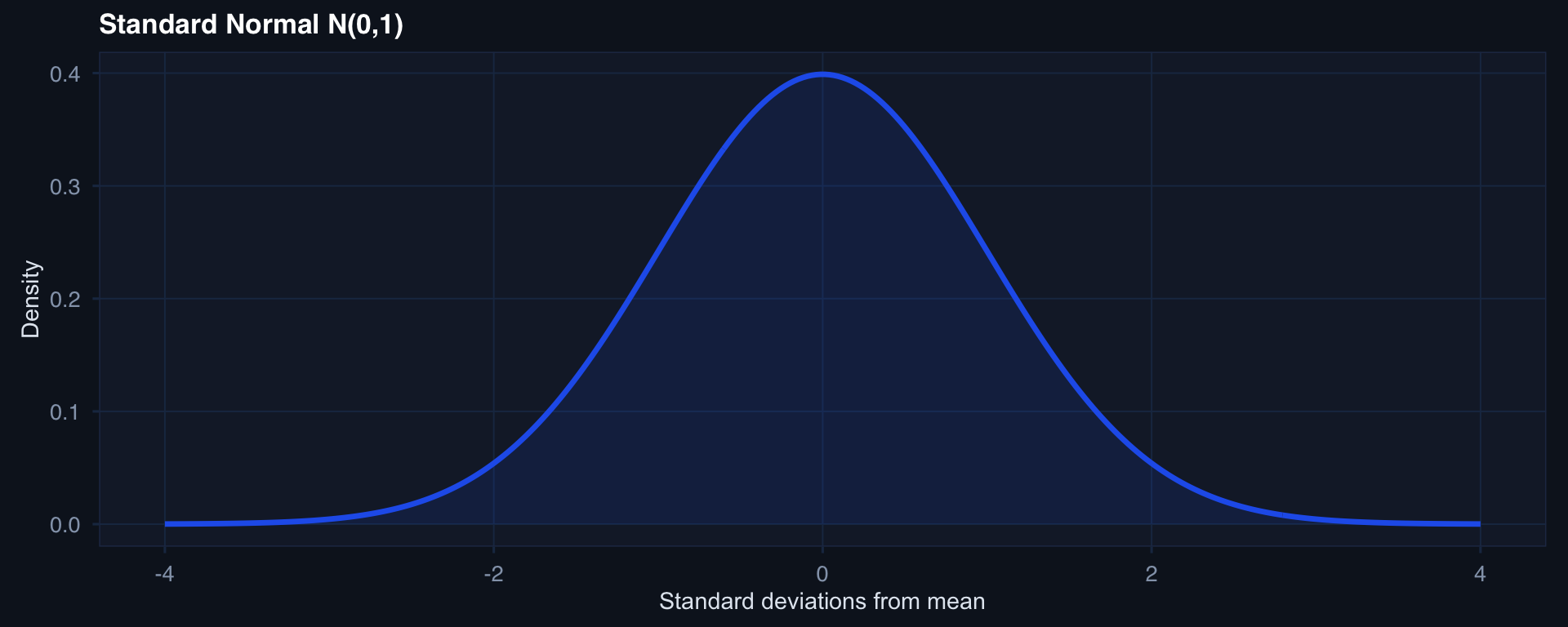
The 68-95-99.7 rule:
- 68% of data within ±1 SD
- 95% within ±2 SD
- 99.7% within ±3 SD
It’s ubiquitous because of the CLT — sums of many independent variables converge to Normal (Lecture 2).
Clinical: Systolic BP, hematocrit, temperature — all approximately Normal in stable populations.
Poisson: When Events Are Rare and Independent
lambdas <- c(1, 3, 8)
pois_df <- purrr::map_dfr(lambdas, function(l) {
tibble::tibble(
x = 0:20,
prob = dpois(0:20, lambda = l),
lambda = paste0("λ = ", l)
)
})
ggplot2::ggplot(pois_df, ggplot2::aes(x, prob, fill = lambda)) +
ggplot2::geom_col(position = "dodge", alpha = 0.85) +
ggplot2::scale_fill_brewer(palette = "Blues") +
ggplot2::labs(title = "Poisson distribution — three rates",
x = "Count", y = "P(X = x)", fill = NULL) +
theme_di()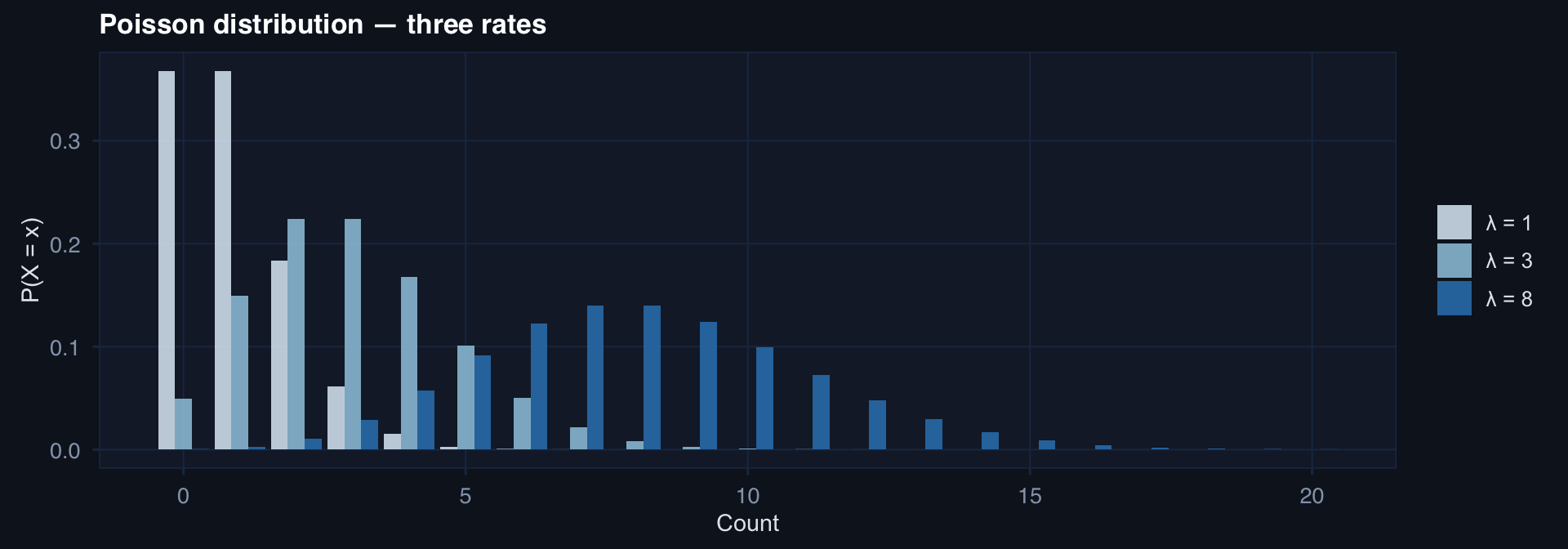
Clinical application: Rare adverse events — anastomotic leaks, intraoperative cardiac arrest, battlefield tourniquet failures. When mean ≈ variance and events are independent, Poisson is the right model.