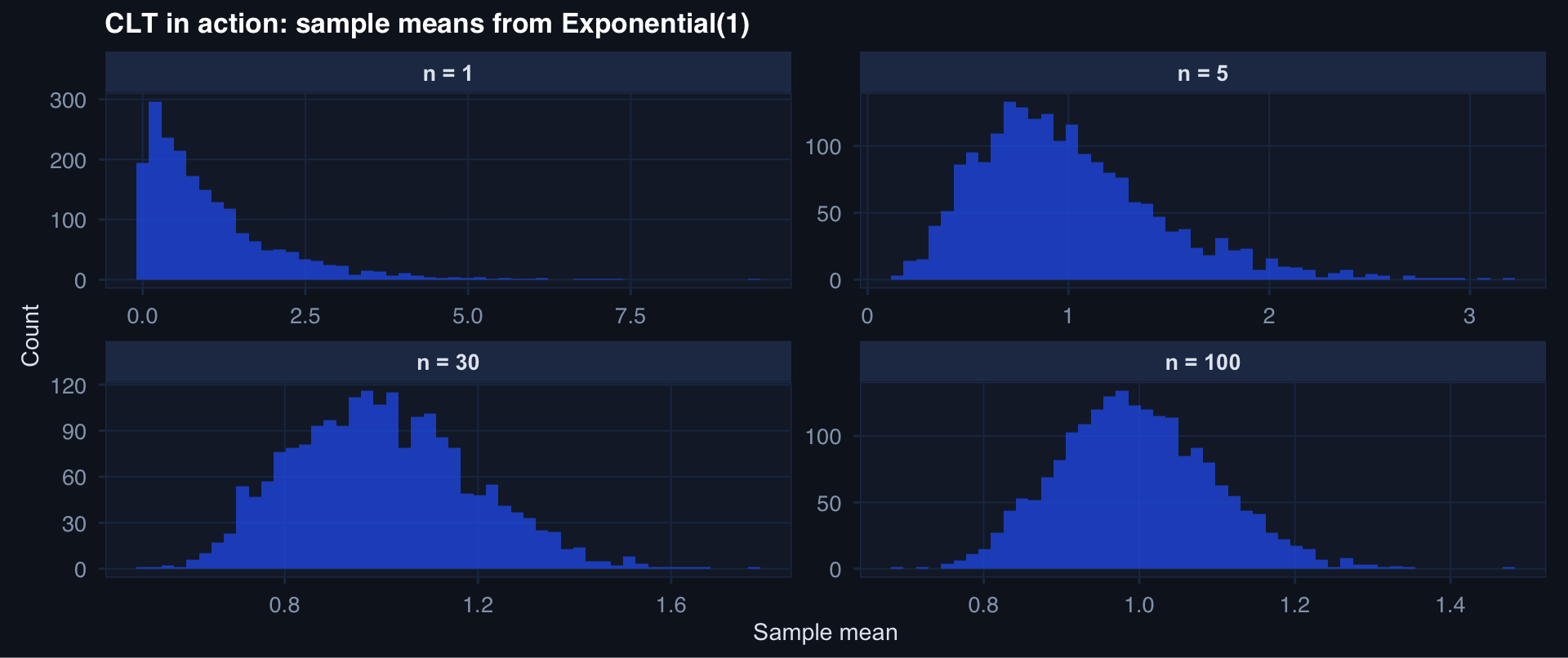
sim_means <- function(n, reps = 2000) {
replicate(reps, mean(rexp(n, rate = 1))) |>
tibble::tibble(mean_val = _) |>
dplyr::mutate(n = n)
}
clt_df <- purrr::map_dfr(c(1, 5, 30, 100), sim_means)
ggplot2::ggplot(clt_df, ggplot2::aes(x = mean_val)) +
ggplot2::geom_histogram(bins = 50, fill = "#2563eb", alpha = 0.75) +
ggplot2::facet_wrap(~n, scales = "free",
labeller = ggplot2::labeller(n = ~ paste0("n = ", .x))) +
ggplot2::labs(title = "CLT in action: sample means from Exponential(1)",
x = "Sample mean", y = "Count") +
theme_di()The Laws That Make Statistics Work
Applied Statistics for AI & Clinical Decision-Making — Lecture 2 of 10
2026-01-01
Watching the CLT Work: Exponential Data
The Standard Error: How Precision Grows with n
\[\text{SE}(\bar{X}) = \frac{\sigma}{\sqrt{n}}\]
Key insight: Precision improves with the square root of sample size.
tibble::tibble(n = 1:500, se = 15 / sqrt(1:500)) |>
ggplot2::ggplot(ggplot2::aes(x = n, y = se)) +
ggplot2::geom_line(linewidth = 1.2, color = "#2563eb") +
ggplot2::geom_vline(xintercept = c(30, 100, 200), linetype = 2, color = "#e63946") +
ggplot2::labs(title = "Standard Error vs. Sample Size (σ = 15)",
x = "n", y = "Standard Error") +
theme_di()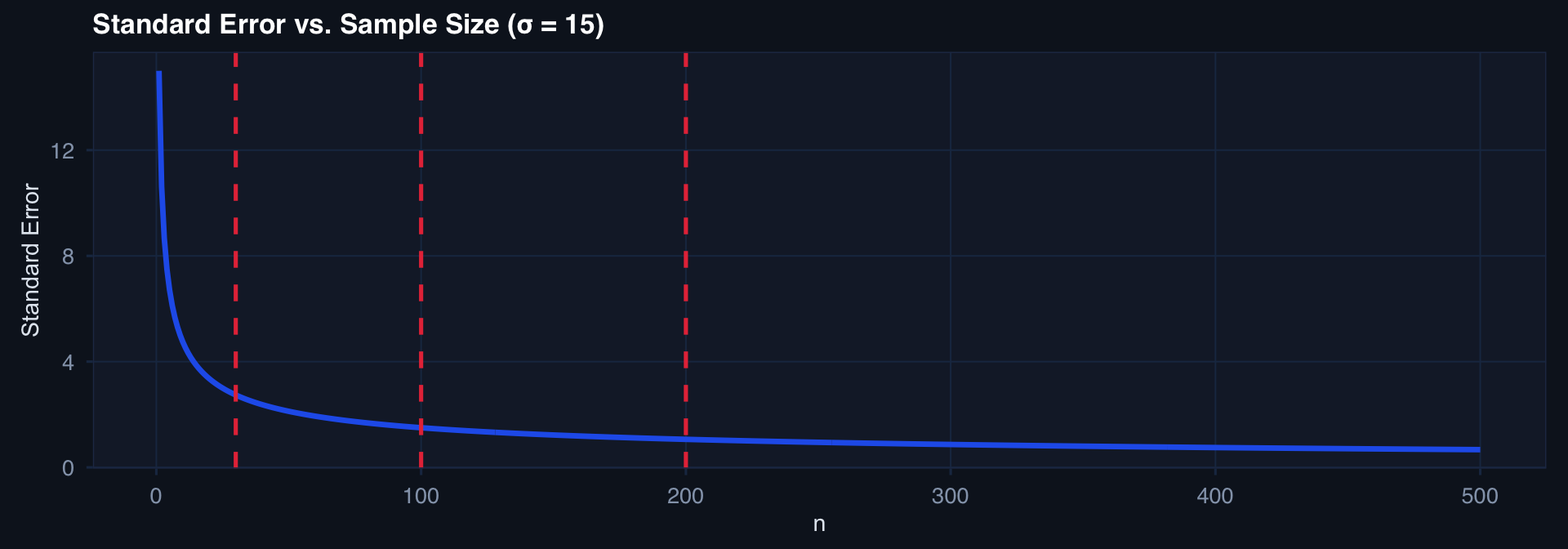
Going from n=50 to n=200 only halves the SE. Quadrupling n for half the precision — this matters for study planning.
Watching the LLN Converge
set.seed(42)
n_max <- 2000
x <- rbinom(n_max, size = 1, prob = 0.27) # 27% mortality
lln_df <- tibble::tibble(
n = 1:n_max,
cumulative_mean = cumsum(x) / (1:n_max)
)
ggplot2::ggplot(lln_df, ggplot2::aes(x = n, y = cumulative_mean)) +
ggplot2::geom_line(linewidth = 0.7, color = "#2563eb") +
ggplot2::geom_hline(yintercept = 0.27, linetype = 2, color = "#e63946", linewidth = 1) +
ggplot2::annotate("text", x = 1600, y = 0.285, label = "True rate = 0.27",
color = "#e63946", size = 3.5) +
ggplot2::labs(title = "LLN: Cumulative mean converging to true mortality rate",
x = "Patients observed", y = "Running mortality rate") +
theme_di()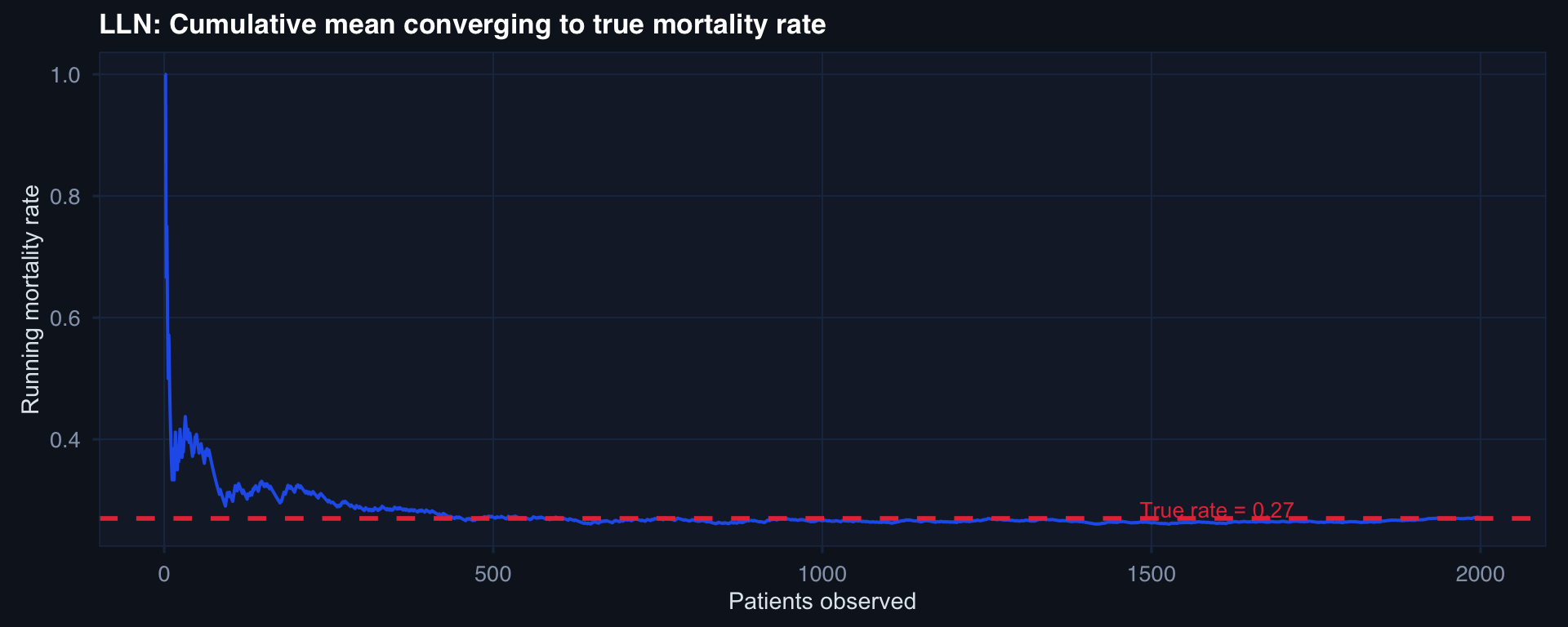
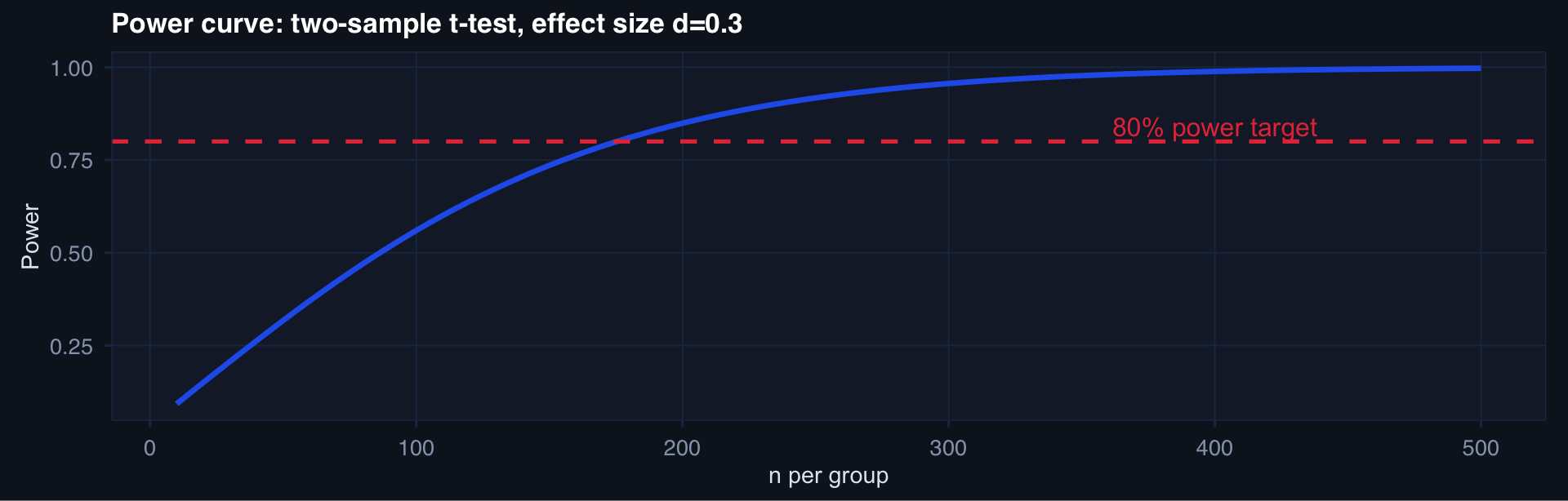
Sample Size Planning: The Four Inputs
\[n \approx \frac{(z_{\alpha/2} + z_\beta)^2 \cdot 2\sigma^2}{\delta^2}\]
where \(\delta\) = minimum detectable difference, \(\sigma^2\) = variance, \(\alpha\) = Type I error rate, \(\beta\) = Type II error rate
# base R power.t.test — no extra packages needed
n_seq <- seq(10, 500, by = 5)
power_df <- tibble::tibble(
n = n_seq,
pwr = sapply(n_seq, function(n) {
power.t.test(n = n, delta = 0.3, sd = 1,
sig.level = 0.05, type = "two.sample")$power
})
)
ggplot2::ggplot(power_df, ggplot2::aes(x = n, y = pwr)) +
ggplot2::geom_line(linewidth = 1.2, color = "#2563eb") +
ggplot2::geom_hline(yintercept = 0.80, linetype = 2, color = "#e63946") +
ggplot2::annotate("text", x = 400, y = 0.84, label = "80% power target",
color = "#e63946") +
ggplot2::labs(title = "Power curve: two-sample t-test, effect size d=0.3",
x = "n per group", y = "Power") +
theme_di()