# Simulate 8 studies with true effect = -0.4, varying sample sizes and heterogeneity
studies <- tibble(
study = paste0("Study ", 1:8),
n = c(50, 120, 80, 200, 45, 300, 90, 150),
effect = c(-0.6, -0.35, -0.55, -0.38, -0.22, -0.41, -0.70, -0.30),
se = sqrt(0.5 / n)
) |> mutate(
lo = effect - 1.96*se,
hi = effect + 1.96*se
)
ggplot(studies, aes(x=effect, y=reorder(study, effect))) +
geom_point(aes(size=n), color="#0891b2") +
geom_errorbarh(aes(xmin=lo, xmax=hi), height=0.25, color="#e2e8f0", linewidth=0.8) +
geom_vline(xintercept=0, linetype=2, color="#e63946") +
geom_vline(xintercept=-0.4, linetype=3, color="#22d3ee") +
scale_size_continuous(range=c(2,7)) +
labs(title="Eight studies — same question, different answers. Which do we believe?",
x="Effect estimate (95% CI)", y=NULL, size="Sample n") + theme_di()Evidence Synthesis: Meta-Analysis & Real-World Generalizability
Advanced Statistics for AI & Clinical Decision-Making — Lecture 4 of 4
2026-01-01
Why Studies Disagree: The Problem Meta-Analysis Solves
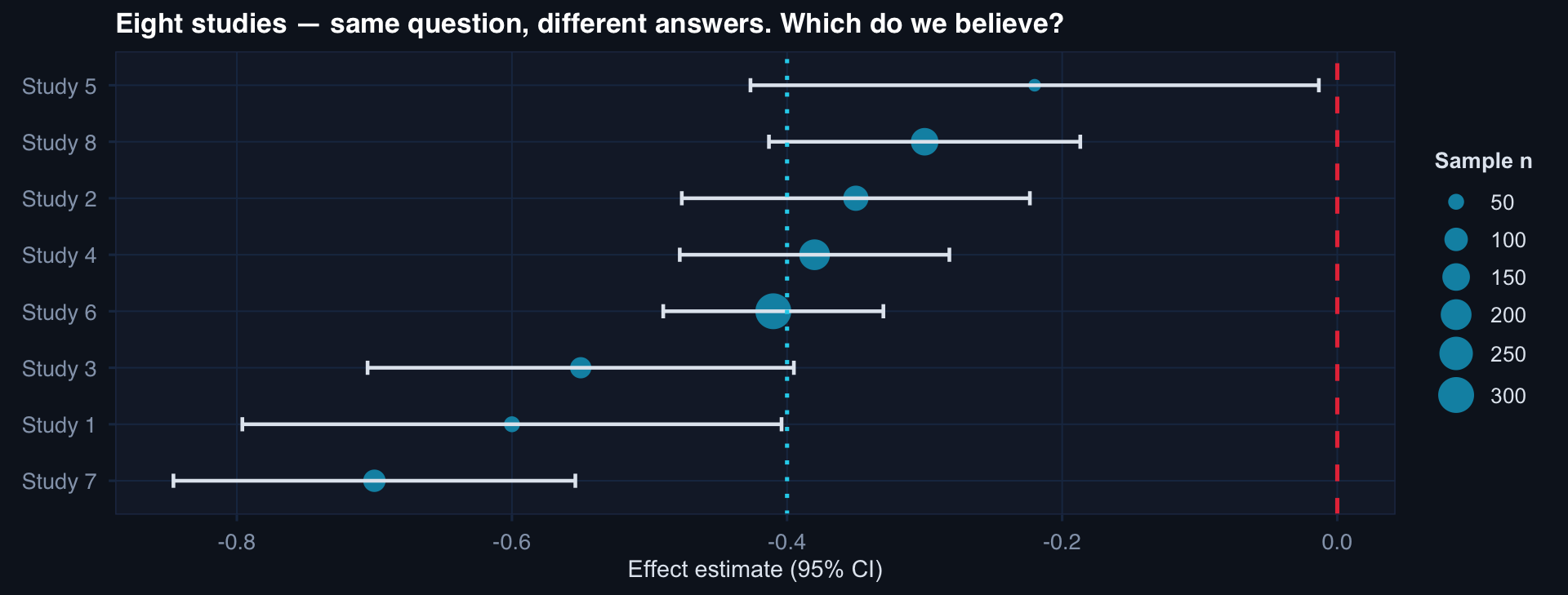
Point estimates range from −0.70 to −0.22. All are individually noisy. Meta-analysis pools them to a single, more precise estimate while quantifying between-study variability.
The Forest Plot — Meta-Analysis Signature Visual
pooled <- tibble(
study = "Pooled (RE)",
effect = mu_re, lo = mu_re - 1.96*se_re, hi = mu_re + 1.96*se_re,
n = sum(studies$n)
)
bind_rows(studies, pooled) |>
mutate(is_pooled = study=="Pooled (RE)",
y_pos = row_number()) |>
ggplot(aes(x=effect, y=reorder(study, y_pos),
color=is_pooled, size=is_pooled)) +
geom_point() +
geom_errorbarh(aes(xmin=lo, xmax=hi), height=0.3, linewidth=0.7) +
geom_vline(xintercept=0, linetype=2, color="#e63946", linewidth=0.8) +
scale_color_manual(values=c("#0891b2","#f59e0b")) +
scale_size_manual(values=c(2.5, 5)) +
labs(title=paste0("Forest plot — I² = ", round(I2,1), "% (moderate heterogeneity)"),
x="Effect estimate (95% CI)", y=NULL) +
theme_di() + theme(legend.position="none")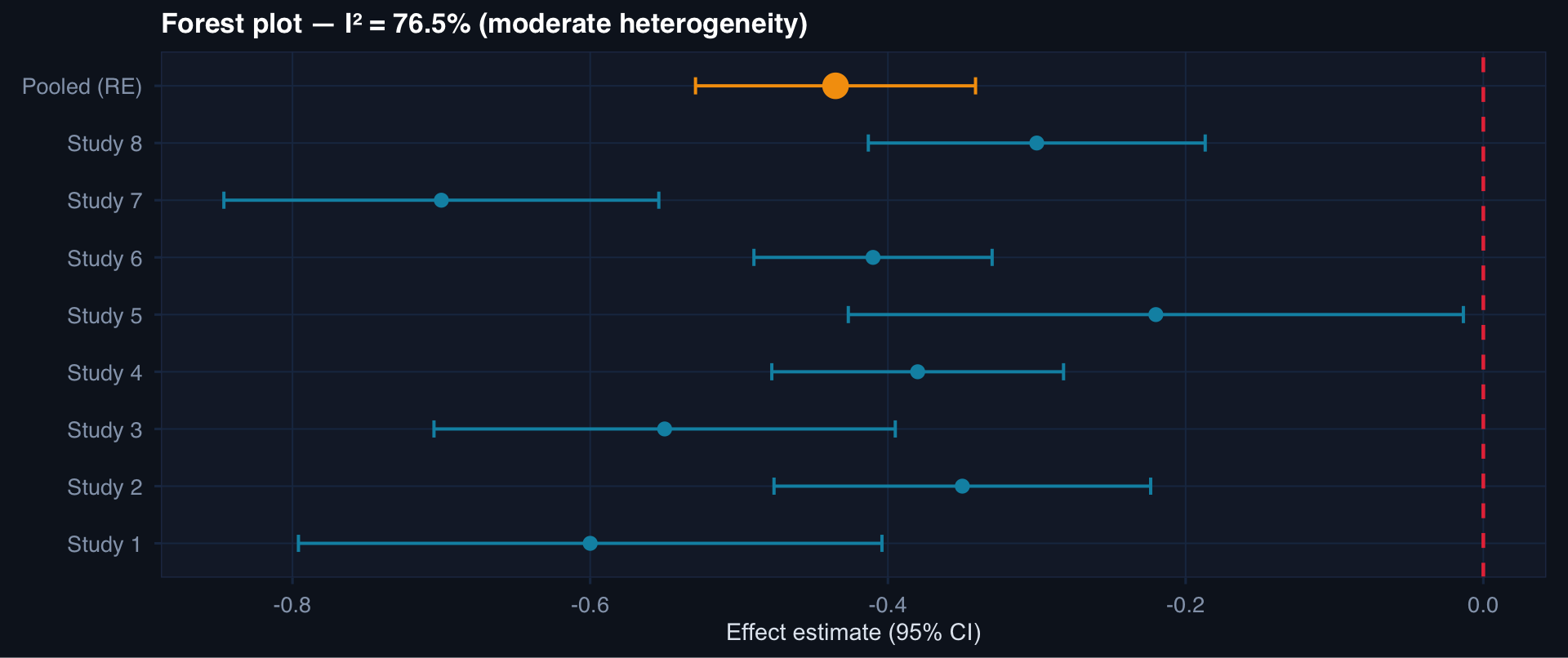
I² interpretation: < 25% = low heterogeneity. 25–75% = moderate — heterogeneity is real and worth investigating. > 75% = high — pooled estimate may be misleading; explore subgroups.
Covariate Shift: The Mechanism of External Validity Failure
# Source population (US civilian trauma) vs. target (military combat trauma)
n_src <- 400; n_tgt <- 300
df_ext <- bind_rows(
tibble(pop="Source (civilian)", iss=rnorm(n_src, 22, 10),
age=rnorm(n_src, 42, 18), penetrating=rbinom(n_src,1,0.20)),
tibble(pop="Target (military)", iss=rnorm(n_tgt, 32, 12),
age=rnorm(n_tgt, 26, 6), penetrating=rbinom(n_tgt,1,0.65))
)
df_ext |>
pivot_longer(c(iss, age)) |>
ggplot(aes(value, fill=pop, color=pop)) +
geom_density(alpha=0.4, linewidth=0.8) +
facet_wrap(~name, scales="free",
labeller=labeller(name=c(age="Age (years)", iss="ISS"))) +
scale_fill_manual(values=c("#2563eb","#e63946")) +
scale_color_manual(values=c("#2563eb","#e63946")) +
labs(title="Source vs. target population: ISS and age distributions are very different",
fill=NULL, color=NULL) + theme_di()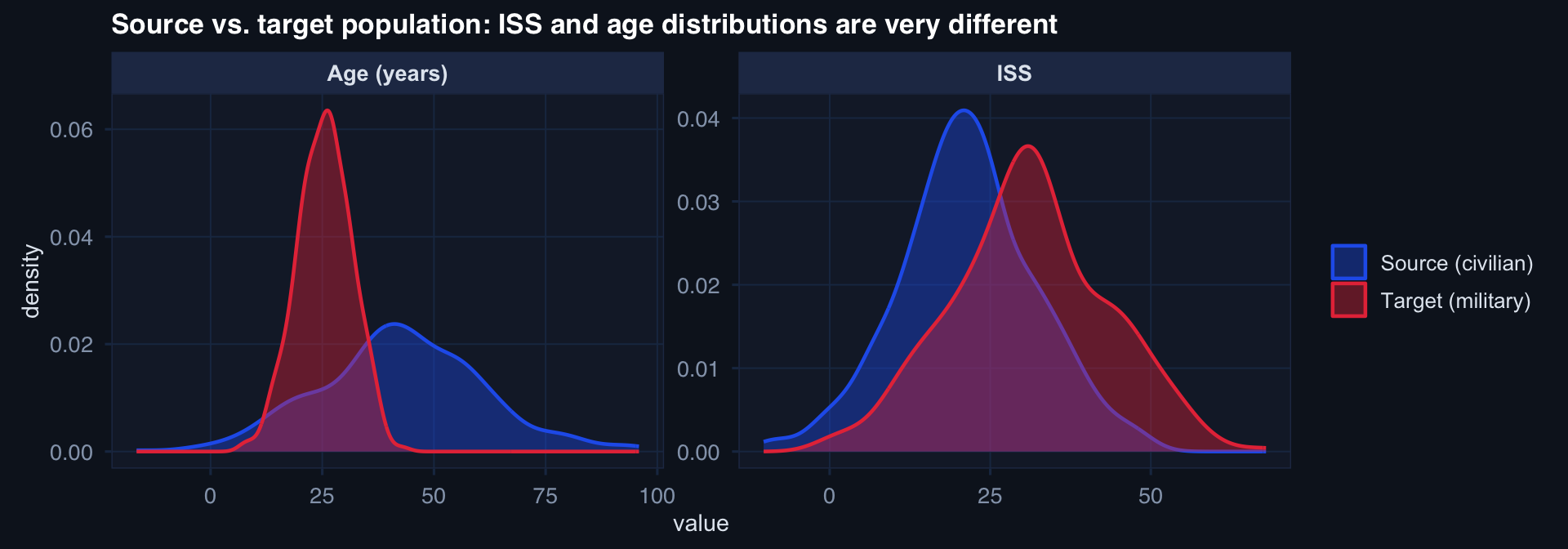
A mortality model trained on civilian trauma patients (older, blunt mechanism, lower ISS) will systematically misfires on military combat casualties (younger, penetrating, higher ISS).