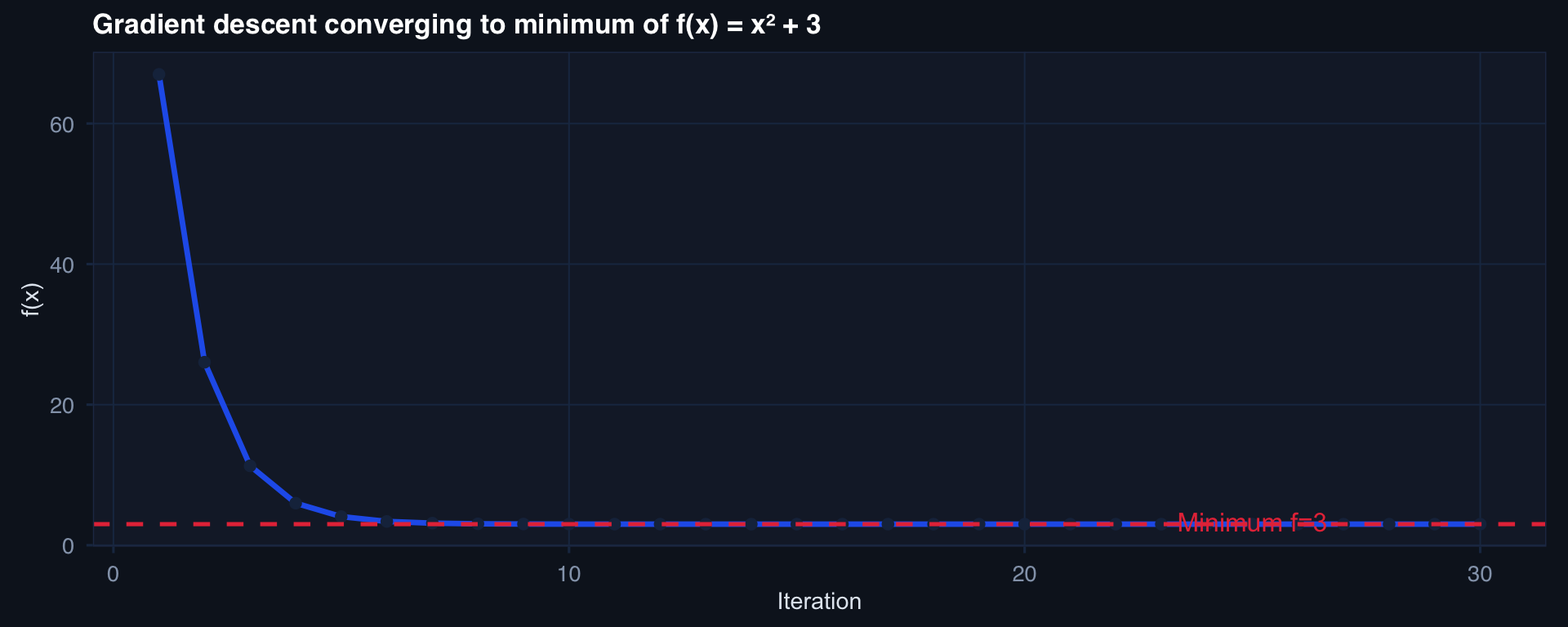
# Simple example: minimize f(x) = x^2 + 3
x_path <- numeric(30); x_path[1] <- 8; lr <- 0.2
for(i in 2:30) x_path[i] <- x_path[i-1] - lr * 2 * x_path[i-1]
tibble(iter=1:30, x=x_path, f=x_path^2+3) |>
ggplot(aes(iter, f)) +
geom_line(linewidth=1.2, color="#2563eb") +
geom_point(size=2, color="#1b2e4b") +
geom_hline(yintercept=3, linetype=2, color="#e63946") +
annotate("text",x=25,y=3.3,label="Minimum f=3",color="#e63946") +
labs(title="Gradient descent converging to minimum of f(x) = x² + 3",
x="Iteration", y="f(x)") + theme_di()Mathematical Foundations of Modern AI
Applied Statistics for AI & Clinical Decision-Making — Lecture 10 of 10
2026-01-01
Gradient Descent: Step Downhill
\[\theta_{t+1} = \theta_t - \alpha \nabla_\theta \mathcal{L}(\theta_t)\]
\(\alpha\) = learning rate (step size)
Learning Rate: The Most Important Hyperparameter
run_gd <- function(lr, n_iter=40) {
x <- 8
sapply(1:n_iter, function(i) { x <<- x - lr * 2 * x; x^2 + 3 })
}
tibble(iter=rep(1:40,3),
loss=c(run_gd(0.05), run_gd(0.2), run_gd(0.6)),
lr=rep(c("Too small (0.05)","Just right (0.2)","Too large (0.6)"), each=40)) |>
ggplot(aes(iter, loss, color=lr)) +
geom_line(linewidth=1) +
scale_y_log10() +
scale_color_manual(values=c("#94a3b8","#2563eb","#e63946")) +
labs(title="Learning rate: too small = slow, too large = diverges",
x="Iteration", y="Loss (log scale)", color=NULL) + theme_di()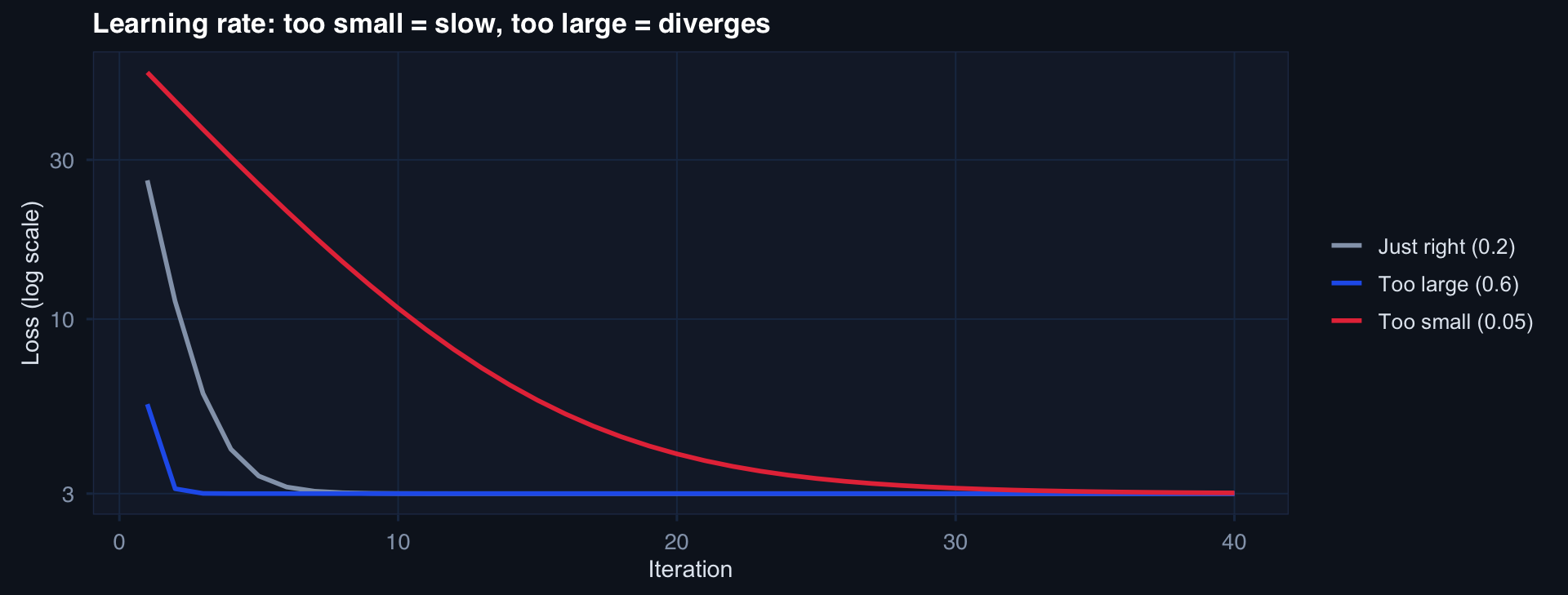
Too small → converges very slowly. Too large → overshoots minimum, diverges. Just right → fast, stable convergence.
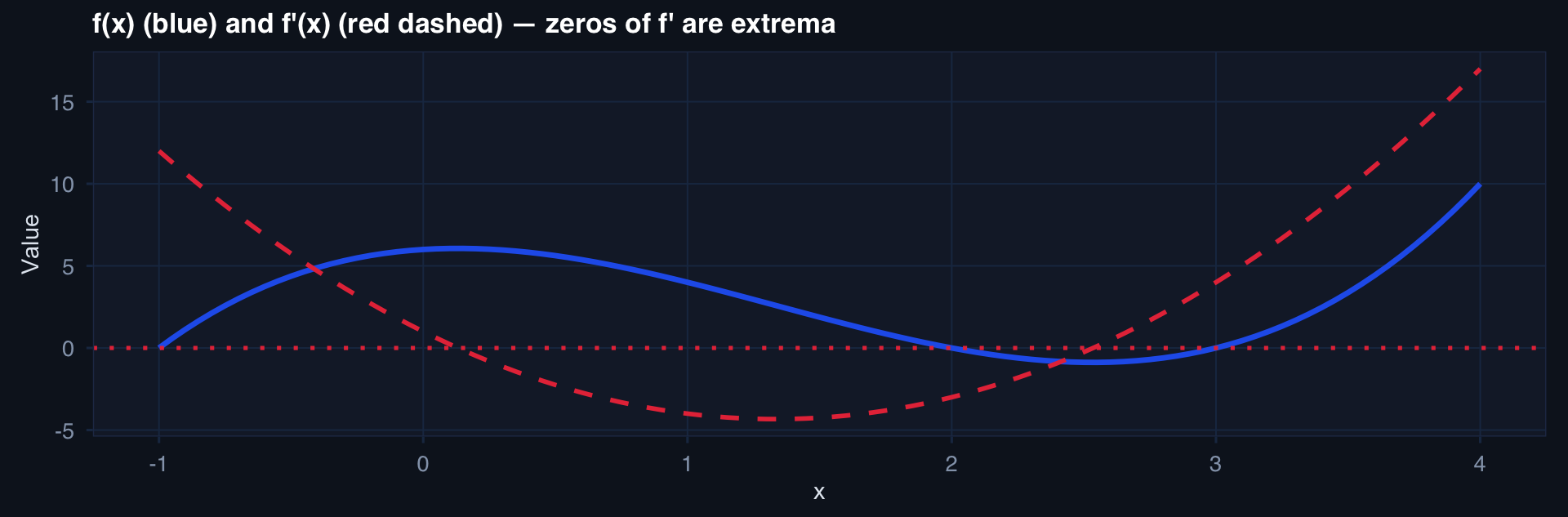
The Derivative: Rate of Change
\[f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}\]
For a multivariable function: gradient \(\nabla_\theta \mathcal{L} = \left[\frac{\partial \mathcal{L}}{\partial \theta_1}, \dots, \frac{\partial \mathcal{L}}{\partial \theta_k}\right]^\top\)
f <- function(x) x^3 - 4*x^2 + x + 6
df <- function(x) 3*x^2 - 8*x + 1
x_grid <- seq(-1, 4, 0.05)
tibble(x=x_grid, f=f(x_grid), deriv=df(x_grid)) |>
ggplot(aes(x)) +
geom_line(aes(y=f), color="#2563eb", linewidth=1.2) +
geom_line(aes(y=deriv), color="#e63946", linewidth=1, linetype=2) +
geom_hline(yintercept=0, linetype=3) +
labs(title="f(x) (blue) and f'(x) (red dashed) — zeros of f' are extrema",
y="Value") + theme_di()